方便更快捷的说明问题,可以按需填写(可删除)
使用环境:5.1
场景、问题:
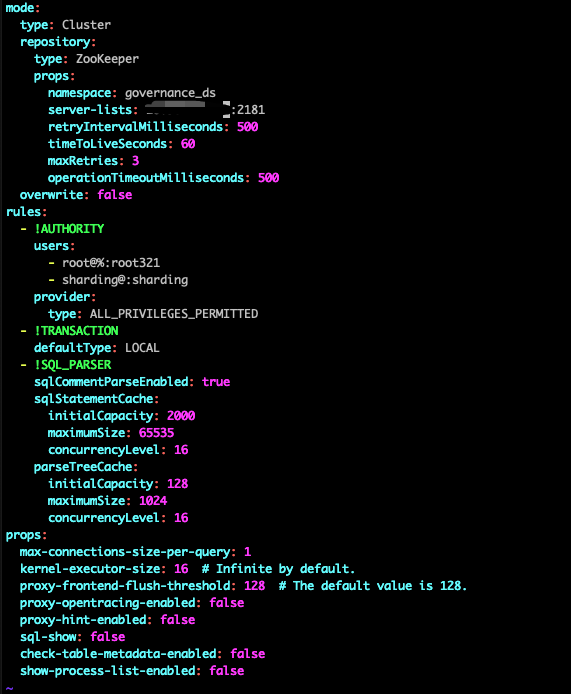
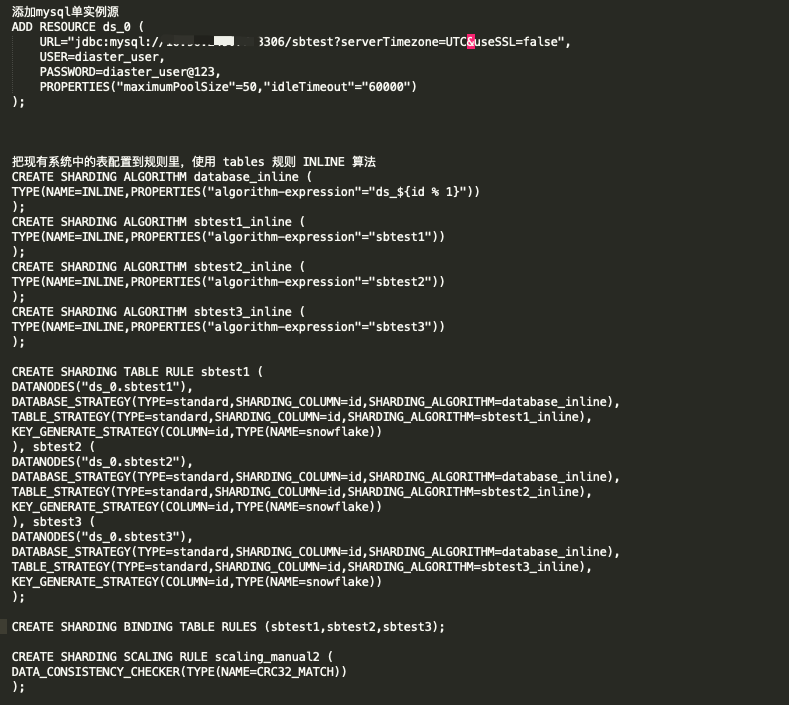
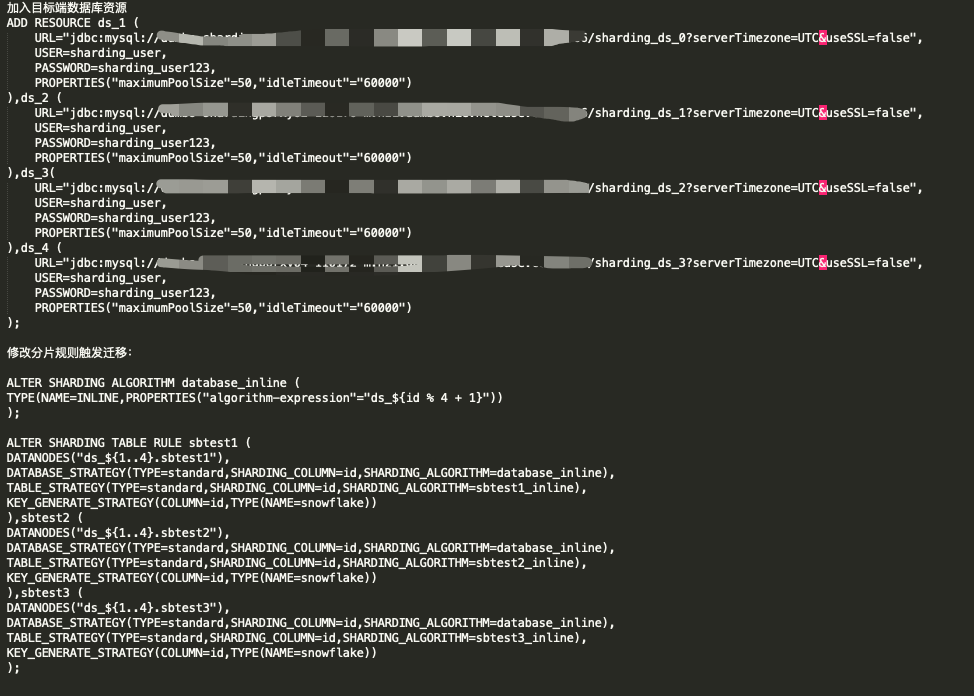
有一个问题想请教一下,我准备迁移数据时, 我配置proxy 集群模式启动时 配置文件如下
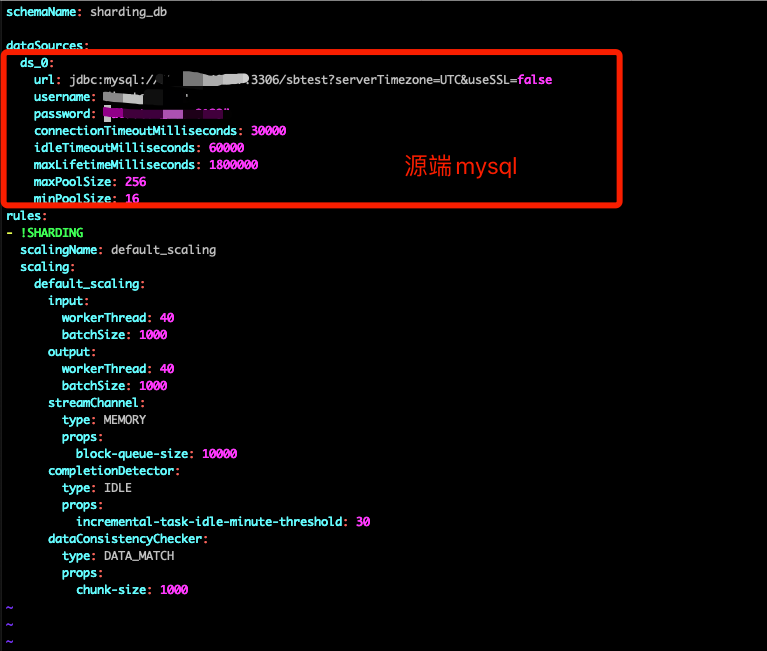
已进行操作:
现状:
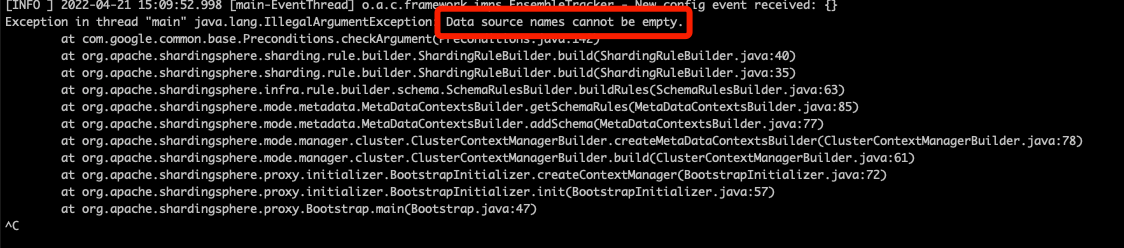
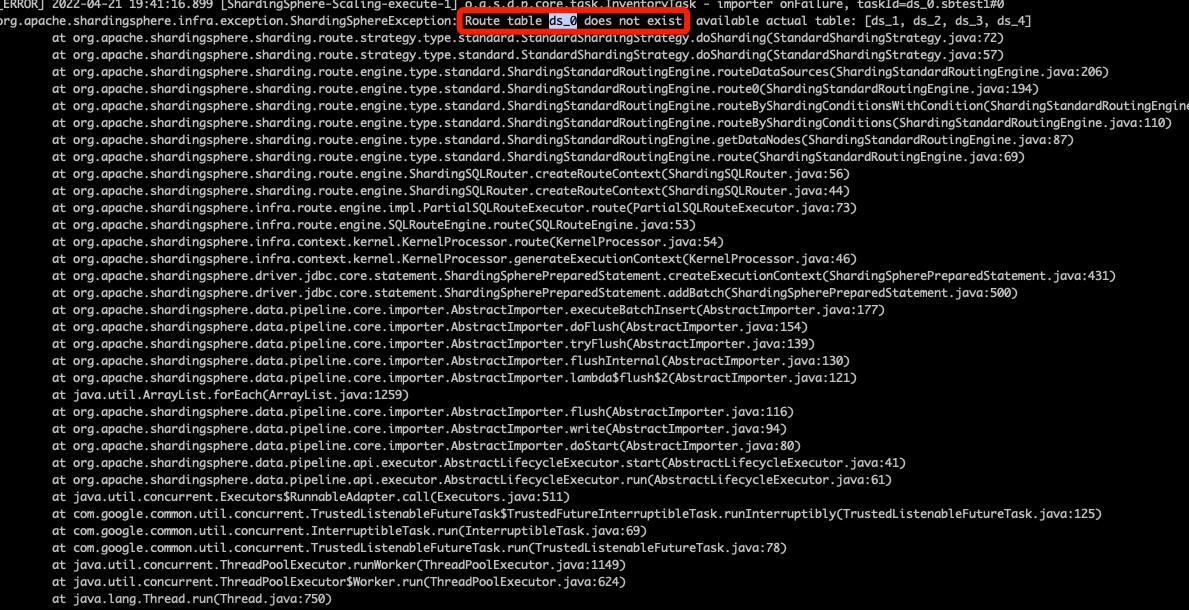
启动时报了如下错误,应该是Datasource 配置有问题?

方便更快捷的说明问题,可以按需填写(可删除)
有一个问题想请教一下,我准备迁移数据时, 我配置proxy 集群模式启动时 配置文件如下
启动时报了如下错误,应该是Datasource 配置有问题?
server.yaml 方便提供下吗?
请把 overwrite 设置为 true 再试试.
设置为true就可以了,估计是之前启动时,zookeep有记录信息了?
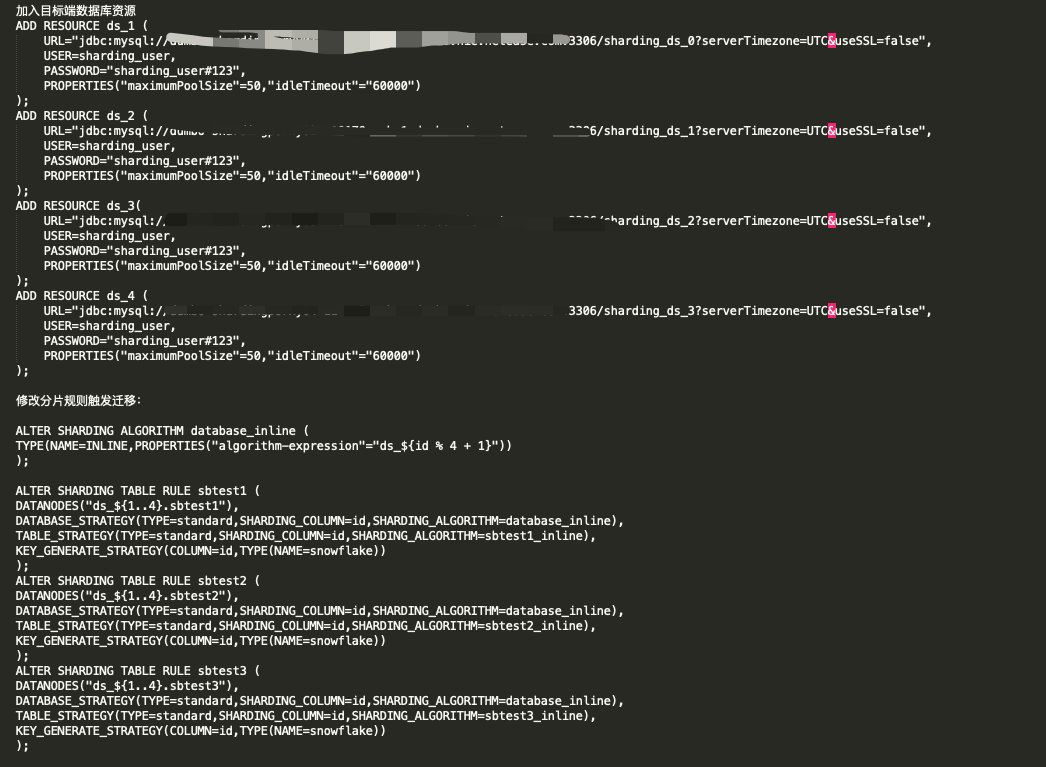
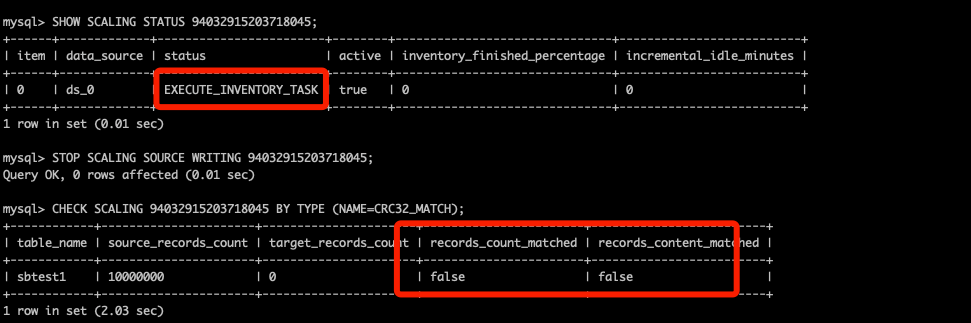
迁移过程中报校验有问题,如何处理
错误日志:
[INFO ] 2022-04-21 17:16:05.280 [_finished_check_Worker-1] o.a.s.d.p.c.a.i.RuleAlteredJobAPIImpl - Scaling job 94023779170872054 with check algorithm ‘org.apache.shardingsphere.data.pipeline.core.spi.check.consistency.DataMatchDataConsistencyCheckAlgorithm’ data consistency checker result {sbtest1=DataConsistencyCheckResult(sourceRecordsCount=10000000, targetRecordsCount=0, recordsCountMatched=false, recordsContentMatched=false), sbtest2=DataConsistencyCheckResult(sourceRecordsCount=10000000, targetRecordsCount=10000000, recordsCountMatched=true, recordsContentMatched=false), sbtest3=DataConsistencyCheckResult(sourceRecordsCount=10000000, targetRecordsCount=10000000, recordsCountMatched=true, recordsContentMatched=false)}
[ERROR] 2022-04-21 17:16:05.281 [_finished_check_Worker-1] o.a.s.d.p.c.a.i.RuleAlteredJobAPIImpl - Scaling job: 94023779170872054, table: sbtest1 data consistency check failed, recordsContentMatched: false, recordsCountMatched: false
[INFO ] 2022-04-21 17:16:05.281 [_finished_check_Worker-1] o.a.s.d.p.c.a.i.GovernanceRepositoryAPIImpl - persist job check result ‘false’ for job 94023779170872054
[ERROR] 2022-04-21 17:16:05.283 [_finished_check_Worker-1] o.a.s.d.p.c.a.i.RuleAlteredJobAPIImpl - Scaling job: 94023779170872054, table: sbtest1 data consistency check failed, recordsContentMatched: false, recordsCountMatched: false
[ERROR] 2022-04-21 17:16:05.283 [_finished_check_Worker-1] o.a.s.d.p.core.job.FinishedCheckJob - data consistency check failed, job 94023779170872054
操作步骤如下:
是的哈, ZooKeeper 上已经有了. 本地需要覆盖
PREPARING_FAILED,可能是有权限之类的异常。
可以粘贴下异常堆栈么
[INFO ] 2022-04-21 18:03:31.155 [94027057633371213_Worker-1] o.a.s.s.s.ShardingRuleAlteredJobConfigurationPreparer - createTaskConfiguration, dataSourceName=ds_0, result=TaskConfiguration(handleConfig=HandleConfiguration(jobId=94027057633371213, concurrency=3, retryTimes=3, tablesFirstDataNodes=sbtest1:ds_0.sbtest1|sbtest2:ds_0.sbtest2|sbtest3:ds_0.sbtest3, jobShardingDataNodes=[sbtest1:ds_0.sbtest1|sbtest2:ds_0.sbtest2|sbtest3:ds_0.sbtest3], logicTables=sbtest1,sbtest2,sbtest3, jobShardingItem=0, shardingSize=10000000, sourceDatabaseType=MySQL, targetDatabaseType=MySQL), dumperConfig=DumperConfiguration(dataSourceName=ds_0, position=null, tableNameMap={sbtest1=sbtest1, sbtest2=sbtest2, sbtest3=sbtest3}), importerConfig=ImporterConfiguration(shardingColumnsMap={sbtest2=[id], sbtest1=[id], sbtest3=[id]}, batchSize=1000, retryTimes=3))
[INFO ] 2022-04-21 18:03:31.712 [94027057633371213_Worker-1] o.a.s.d.p.c.p.d.AbstractDataSourcePreparer - execute target table sql: CREATE TABLE IF NOT EXISTS sbtest1 (
id int(11) NOT NULL,
k int(11) NOT NULL DEFAULT ‘0’,
c char(120) NOT NULL DEFAULT ‘’,
pad char(60) NOT NULL DEFAULT ‘’,
PRIMARY KEY (id),
KEY k_1 (k)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
[INFO ] 2022-04-21 18:03:31.856 [94027057633371213_Worker-1] o.a.s.d.p.m.p.d.MySQLDataSourcePreparer - create target table ‘sbtest1’ success
[INFO ] 2022-04-21 18:03:31.859 [94027057633371213_Worker-1] o.a.s.d.p.c.p.d.AbstractDataSourcePreparer - execute target table sql: CREATE TABLE IF NOT EXISTS sbtest2 (
id int(11) NOT NULL,
k int(11) NOT NULL DEFAULT ‘0’,
c char(120) NOT NULL DEFAULT ‘’,
pad char(60) NOT NULL DEFAULT ‘’,
PRIMARY KEY (id),
KEY k_2 (k)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
[INFO ] 2022-04-21 18:03:31.878 [94027057633371213_Worker-1] o.a.s.d.p.m.p.d.MySQLDataSourcePreparer - create target table ‘sbtest2’ success
[INFO ] 2022-04-21 18:03:31.879 [94027057633371213_Worker-1] o.a.s.d.p.c.p.d.AbstractDataSourcePreparer - execute target table sql: CREATE TABLE IF NOT EXISTS sbtest3 (
id int(11) NOT NULL,
k int(11) NOT NULL DEFAULT ‘0’,
c char(120) NOT NULL DEFAULT ‘’,
pad char(60) NOT NULL DEFAULT ‘’,
PRIMARY KEY (id),
KEY k_3 (k)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4
[INFO ] 2022-04-21 18:03:31.889 [94027057633371213_Worker-1] o.a.s.d.p.m.p.d.MySQLDataSourcePreparer - create target table ‘sbtest3’ success
[ERROR] 2022-04-21 18:03:31.945 [94027057633371213_Worker-1] o.a.s.d.p.s.r.RuleAlteredJob - job prepare failed, 94027057633371213-0
[INFO ] 2022-04-21 18:03:31.945 [94027057633371213_Worker-1] o.a.s.d.p.s.r.RuleAlteredJobContext - close…
[ERROR] 2022-04-21 18:03:31.985 [94027057633371213_Worker-1] o.a.s.e.e.h.g.LogJobErrorHandler - Job ‘94027057633371213’ exception occur in job processing
org.apache.shardingsphere.data.pipeline.core.exception.PipelineJobPrepareFailedException: Target table sbtest2 is not empty, sql: SELECT * FROM sbtest2 LIMIT 1.
at org.apache.shardingsphere.data.pipeline.core.check.datasource.AbstractDataSourceChecker.checkEmpty(AbstractDataSourceChecker.java:65)
at org.apache.shardingsphere.data.pipeline.core.check.datasource.AbstractDataSourceChecker.checkTargetTable(AbstractDataSourceChecker.java:51)
at org.apache.shardingsphere.data.pipeline.scenario.rulealtered.RuleAlteredJobPreparer.checkTargetDataSource(RuleAlteredJobPreparer.java:113)
at org.apache.shardingsphere.data.pipeline.scenario.rulealtered.RuleAlteredJobPreparer.initAndCheckDataSource(RuleAlteredJobPreparer.java:97)
at org.apache.shardingsphere.data.pipeline.scenario.rulealtered.RuleAlteredJobPreparer.prepare(RuleAlteredJobPreparer.java:66)
at org.apache.shardingsphere.data.pipeline.scenario.rulealtered.RuleAlteredJob.execute(RuleAlteredJob.java:51)
at org.apache.shardingsphere.elasticjob.simple.executor.SimpleJobExecutor.process(SimpleJobExecutor.java:33)
at org.apache.shardingsphere.elasticjob.simple.executor.SimpleJobExecutor.process(SimpleJobExecutor.java:29)
at org.apache.shardingsphere.elasticjob.executor.ElasticJobExecutor.process(ElasticJobExecutor.java:172)
at org.apache.shardingsphere.elasticjob.executor.ElasticJobExecutor.process(ElasticJobExecutor.java:141)
at org.apache.shardingsphere.elasticjob.executor.ElasticJobExecutor.execute(ElasticJobExecutor.java:124)
at org.apache.shardingsphere.elasticjob.executor.ElasticJobExecutor.execute(ElasticJobExecutor.java:100)
at org.apache.shardingsphere.elasticjob.lite.internal.schedule.LiteJob.execute(LiteJob.java:35)
at org.quartz.core.JobRunShell.run(JobRunShell.java:202)
at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)
[INFO ] 2022-04-21 18:03:32.315 [Curator-SafeNotifyService-0] o.a.s.m.m.c.c.r.c.s.ScalingRegistrySubscriber - start scaling job, locked the schema name, event=org.apache.shardingsphere.mode.manager.cluster.coordinator.registry.config.event.rule.RuleConfigurationCachedEvent@75aa5a6d
看错误信息是 提示这个表不存在的,但是我查看目标数据库,都没有生成这个表
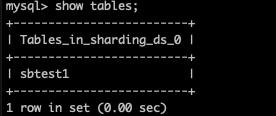
关键错误是这个: Target table sbtest2 is not empty, sql: SELECT * FROM sbtest2 LIMIT 1.。
在这次运行之前目标端已经有sbtest2表么,有没有数据。
可以清空目标端表数据再验证下。
目标端检查了 没有看到有sbtest2这张表
全部清空了,然后执行 迁移 还是报上面的错误,而且目标段看到只创建了 sbtest1一张空表
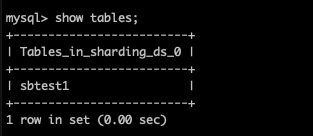
你使用这个5.1版本可用跑通官网的例子么?
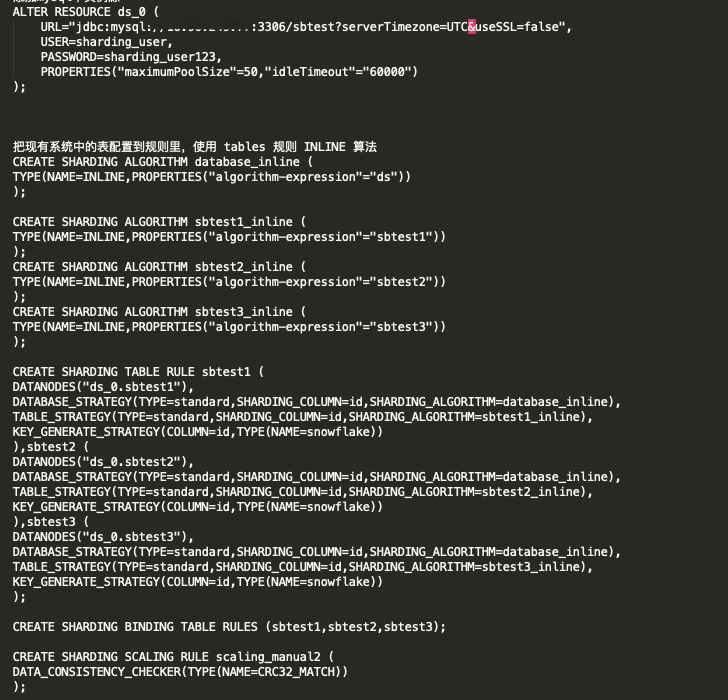
另外,ALTER SHARDING TABLE RULE 只能写一条,把所有要处理的表的规则都写到一块。因为每次执行这个语句都可能触发scaling job。
可能是规则配置错了。检查下database_inline计算出来的分库名和actualDataNodes里面配置的是否匹配。
如果看不出来问题,去注册中心把/{namespace}/scaling/{jobId}/config的内容拷贝粘贴到这里(把数据库IP和账号密码脱敏下)。
已经搞定了 非常感谢
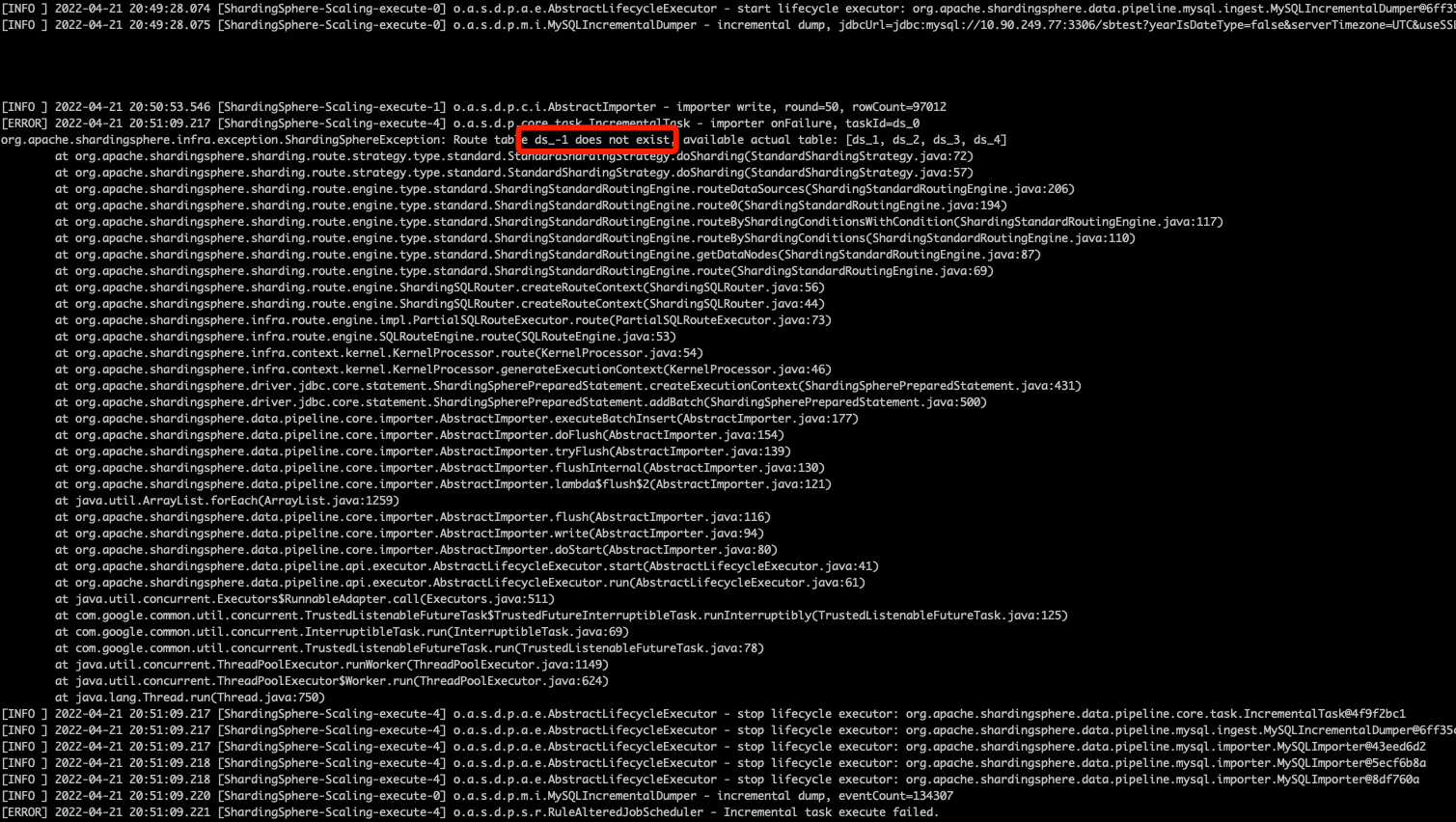
ds_-1应该是规则里指定的expression计算出来的,可以参考前面的方法排查下。
job config 里面有两套rules,看下target那套rules,如果不确定的话两套rules都检查下。
查不出来的话可以拷贝粘贴前面提到的job config到这。
看了一下代码,已经搞定了