使用环境:
shardingsphere 4.0.0-RC1
场景、问题:
两个库是在同个host 和端口下,以前可以通过库名.表名的形式进行跨库查询,集成shardingjdbc后,库名应该是gyscadax.sys_tenant 后来会被改写成gyscadax_internet.sys_tenant
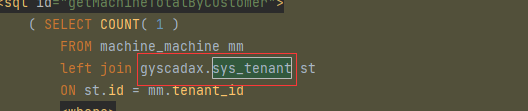
已进行操作:
1.配置多数据源,设置defaultdataSource
2.在表名前加数据源名称
现状:
库名会被改为默认数据源的库名

shardingsphere 4.0.0-RC1
两个库是在同个host 和端口下,以前可以通过库名.表名的形式进行跨库查询,集成shardingjdbc后,库名应该是gyscadax.sys_tenant 后来会被改写成gyscadax_internet.sys_tenant
1.配置多数据源,设置defaultdataSource
2.在表名前加数据源名称
库名会被改为默认数据源的库名
有点需要注意:
ShardingSphere 中使用逻辑数据库,SQL 语句中包含 schema.table 时,schema 应当是逻辑库。
由于你没有贴出具体配置,猜测 SQL 中的 schema 并不是逻辑库,因此改写结果也不符合预期。
建议:
在使用 ShardingSphere 时不要用 schema.table 的方式查询,因为逻辑 schema 聚合了多个数据库的表,直接使用表名就可以了。
好的谢谢,因为我现在未做分表规则的表出现了这个问题没办法给他配置逻辑库,我现在准备升级5.1试一下,好像有个新的配置default single table rule可以解决这个问题。
没有分表规则的表(已存在的),不需要配置,也不用 default single table rule 的,SS 是能够自动从数据源中识别出来的,因此直接用表名就行,你可以试试。
刚才试了一下,直接使用表名还是前面还是会加上默认数据源的库名 
spring:
autoconfigure:
exclude: org.springframework.cloud.gateway.config.GatewayAutoConfiguration,org.springframework.cloud.gateway.config.GatewayClassPathWarningAutoConfiguration
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名
names: ds0,ds11111
# 给master-ds1每个数据源配置数据库连接信息
ds0:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${MYSQL_HOST:gyscada-mysql}:${MYSQL_PORT:3306}/${MYSQL_DB:gyscadax_internet}?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8&allowMultiQueries=true&allowPublicKeyRetrieval=true
username: ${MYSQL_USER:gydev}
password: ${MYSQL_PWD:Gy123!@#}
maxPoolSize: 100
minPoolSize: 5
ds11111:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${MYSQL_HOST:gyscada-mysql}:${MYSQL_PORT:3306}/${MYSQL_DB:gyscadax}?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8&allowMultiQueries=true&allowPublicKeyRetrieval=true
username: ${MYSQL_USER:gydev}
password: ${MYSQL_PWD:Gy123!@#}
maxPoolSize: 100
minPoolSize: 5
# 配置默认数据源ds0
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。
# binding-tables: sys_tenant
default-data-source-name: ds0
# 配置分表的规则
tables:
# fault_cause_day_record 逻辑表名
energy_output_shifts_record:
# 数据节点:数据源$->{0…N}.逻辑表名$->{0…N}
logicTable: energy_output_shifts_record
actual-data-nodes: ds0.energy_output_shifts_record
table-strategy:
standard:
shardingColumn: create_time
preciseAlgorithmClassName: algorithm.YearMonthShardingAlgorithm
这是我的配置,sys_tenant这个表是在gyscadax库,现在默认数据源是ds0,sys_tenant还是会被解析成gyscadax_internet.sys_tenant
这是使用 4.0.0-RC1 的配置吗?
4.0 确实会走默认数据源,我之前说直接用表名是因为看到你说要尝试 5.1.0。
4.0 这个版本有 3 年了,考虑升级一下吧,性能和兼容性都有很大提升
嗯嗯好的,现在使用的是4.0.0-RC1马上升级5.1.0试一下