
作者:陈出新
SphereEx 中间件研发工程师,Apache ShardingSphere Committer,目前专注于 Apache ShardingSphere 内核模块的研发工作。
经常使用数据库的朋友们一定见过无比复杂的 SQL,以下面的 SQL 语句为例,你能立刻看出来这条 SQL 的含义吗?
select a.order_id,a.status,sum(b.money) as money from t_order a inner join (select c.order_id as order_id, c.number * d.price as money from t_order_detail c inner join t_order_price d on c.s_id = d.s_id) b on a.order_id = b.order_id where b.money > 100 group by a.order_id
经过格式化之后是不是容易理解多了:
SELECT a . order_id , a . status , SUM(b . money) AS money
FROM t_order a INNER JOIN
(
SELECT c . order_id AS order_id, c . number * d . price AS money
FROM t_order_detail c INNER JOIN t_order_price d ON c . s_id = d . s_id
) b ON a . order_id = b . order_id
WHERE
b . money > 100
GROUP BY a . order_id;
相信大家拿到复杂 SQL 分析的第一步就是格式化这个 SQL,然后才能基于格式化之后的内容进一步分析 SQL 语义。SQL 的格式化功能也是众多数据库相关软件的必备功能之一。Apache ShardingSphere 基于这样的需求,依托自带的数据库方言解析引擎,推出了自己的 SQL 格式化工具——SQL Parse Format。
**SQL Parse Format 是 Apache ShardingSphere 解析引擎的功能之一,也将是未来规划版本中 SQL 审计功能的基础。**本文将带领读者深入浅出地理解 SQL Parse Format 功能,了解它的底层原理、使用方式以及如何参与 SQL Parse Format 开发。
Parser Engine
SQL Parse Format 作为 Apache ShardingSphere 解析引擎的功能之一,是解析引擎中独特并且相对独立的功能。要理解 SQL Parse Format 功能,需要首先需要了解 Apache ShardingSphere 的解析引擎。
Apache ShardingSphere 解析引擎创建的初衷是为了提取 SQL 中的关键信息,例如用于分库分表的字段、加密改写的列等等内容。随着 Apache ShardingSphere 的不断发展,解析引擎也经历了 3 代产品的更新迭代。
第一代解析引擎采用 Druid 作为 SQL 解析器,它在 1.4.x 之前的版本使用,性能优异。第二代解析引擎采用了全自研的方式,由于使用目的不同,第二代产品采用对 SQL 半理解的方式,仅仅提取分片数据关心的上下文信息,无需生成解析树,也不用二次遍历,因此性能和兼容性进一步提升。第三代解析引擎采用 ANTLR 作为解析引擎的生成器,从而生成解析树,然后再对解析树进行二次遍历访问提取上下文信息。利用 ANTLR 作为解析引擎生成器之后,SQL 的兼容性得以大幅提升,Apache ShardingSphere 的众多功能也能够基于这个基础快速展开。5.0.x 的版本也对第三代解析引擎进行了大量的性能优化,包括将遍历方式从 Listener 变为 Visitor,为预编译的 SQL 语句添加解析结果缓存等等。
SQL Parse Format 功能的实现正是得益于第三代解析引擎的创建。接下来,就让我们将目光聚集到 SQL Parse Format 功能之上。
SQL Parse Format
SQL Parse Format 是一款 SQL 语句格式化的工具。SQL Parse Format 功能将来还会用于 SQL 审计功能之中,它可以方便用户查看历史 SQL 、通过报表展示格式化的 SQL 或者对 SQL 作进一步的分析处理。
例如如下 SQL 经过 SQL Parse Format 格式化之后会变成以下格式。它通过换行和关键字大写的方式让 SQL 的各个部分更加突出和清晰。
select age as b, name as n from table1 join table2 where id = 1 and name = 'lu';
-- 格式化
SELECT age AS b, name AS n
FROM table1 JOIN table2
WHERE
id = 1
and name = 'lu';
了解了 SQL Parse Format 的基本功能之后,让我们一起来探究 SQL Parse Format 背后的原理。
SQL Parse Format 原理解读
以如下 SQL 为例,我们来一起探究它在 Apache ShardingSphere 中是如何被格式化的。
select order_id from t_order where status = 'OK'
Apache ShardingSphere 采用了 ANTLR4 作为解析引擎生成器工具,所以我们首先按照 ANTLR4 的方式,在 .g4 文件中定义了 select 的语法(以 MySQL 为例)。
simpleSelect
: SELECT ALL? targetList? intoClause? fromClause? whereClause? groupClause? havingClause? windowClause?
| SELECT distinctClause targetList intoClause? fromClause? whereClause? groupClause? havingClause? windowClause?
| valuesClause
| TABLE relationExpr
;
我们通过 IDEA 的 ANTLR4 插件可以方便地查看 SQL 生成的语法树。
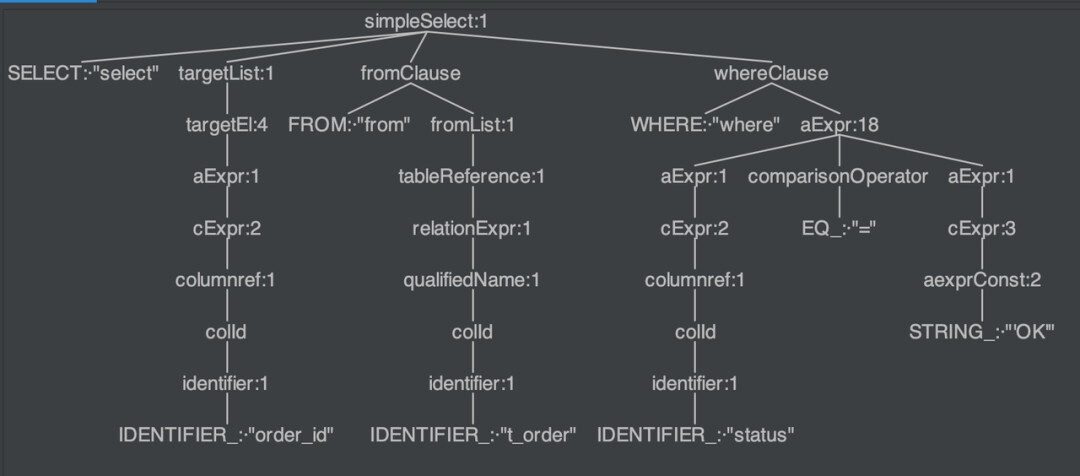
ANTLR4 会将我们定义的语法文件编译,首先对 SQL 进行词法分析,将 SQL 拆分成不可分割的部分,也就是 token,并且会根据不同数据库提供的字典值,将这些 token 划分为关键字,表达式,字面量和操作符。例如,上图中我们分别得到了关键字 SELECT、FROM、WHERE、= 以及变量 order_id、t_order、status、OK。接着 ANTLR4 会将语法分析器的输出结果转化为上图的语法树。
结合 Apache ShardingSphere 中的源码,上述过程复现如下所示。
String sql = "select order_id from t_order where status = 'OK'";
CacheOption cacheOption = new CacheOption(128, 1024L, 4);
SQLParserEngine parserEngine = new SQLParserEngine("MySQL", cacheOption, false);
ParseContext parseContext = parserEngine.parse(sql, false);
Apache ShardingSphere 的 SQLParserEngine 是对 ANTLR4 解析的封装和抽象,它会通过 SPI 的方式来加载数据库方言的解析器,用户可以通过 SPI 扩展点对数据方言进行进一步扩展。另外内部还增加了缓存机制,用来提高性能。我们着重来看一下解析的相关代码。
public ParseContext parse(final String sql) {
ParseASTNode result = twoPhaseParse(sql);
if (result.getRootNode() instanceof ErrorNode) {
throw new SQLParsingException("Unsupported SQL of `%s`", sql);
}
return new ParseContext(result.getRootNode(), result.getHiddenTokens());
}
private ParseASTNode twoPhaseParse(final String sql) {
DatabaseTypedSQLParserFacade sqlParserFacade = DatabaseTypedSQLParserFacadeRegistry.getFacade(databaseType);
SQLParser sqlParser = SQLParserFactory.newInstance(sql, sqlParserFacade.getLexerClass(), sqlParserFacade.getParserClass(), sqlCommentParseEnabled);
try {
((Parser) sqlParser).getInterpreter().setPredictionMode(PredictionMode.SLL);
return (ParseASTNode) sqlParser.parse();
} catch (final ParseCancellationException ex) {
((Parser) sqlParser).reset();
((Parser) sqlParser).getInterpreter().setPredictionMode(PredictionMode.LL);
try {
return (ParseASTNode) sqlParser.parse();
} catch (final ParseCancellationException e) {
throw new SQLParsingException("You have an error in your SQL syntax");
}
}
}
twoPhaseParse 是解析的核心,首先会根据数据库类型加载到对应解析类,接着通过反射机制,生成 ANTLR4 的解析器实例。然后通过 ANTLR4 官方提供的两种解析方式,首先进行快速解析,快速解析失败,会进行常规解析,大部分 SQL 都能够通过快速解析得到结果从而提高解析性能。解析过后,我们便得到了解析树。
那么 Apache ShardingSphere 又是如何从解析树得到格式化的 SQL 呢?其实就是通过 Visitor 方法来实现的。ANTLR4 提供了两种访问语法树的方式,包括 Listener 和 Visitor ,ShardingSphere 采用 Visitor 的方式来访问语法树。下方代码展示了如何从语法树得到格式化 SQL 的方式。
SQLVisitorEngine visitorEngine = new SQLVisitorEngine("MySQL", "FORMAT", new Properties());
String result = visitorEngine.visit(parseContext);
Apache ShardingSphere 的 SQLVisitorEngine 也是对各种方言访问器的抽象和封装。核心方法如下。
public <T> T visit(final ParseContext parseContext) {
ParseTreeVisitor<T> visitor = SQLVisitorFactory.newInstance(databaseType, visitorType, SQLVisitorRule.valueOf(parseContext.getParseTree().getClass()), props);
T result = parseContext.getParseTree().accept(visitor);
appendSQLComments(parseContext, result);
return result;
}
上述 visit 方法首先根据数据库类型以及访问器类型来决定采用的访问器,内部也是通过反射的方式来实例化访问器。目前 visitorType 支持两种方式,一种是 FORMAT 也就是格式化,另外一种是 STATEMENT 也就是 Apache ShardingSphere 常用的方式,将 SQL 转化为 Statement 信息,提取相关上下文信息,为后续例如分库分表等功能服务。其实这也是 SQL Parse Format 功能和普通的解析引擎功能的唯一区别。接下来我还是以上述 SQL 为例,通过具体代码展示 Visitor 如何将 SQL 格式化。
MySQLFormatSQLVisitor 负责该 SQL 的访问任务,通过 DEBUG 代码我们可以清晰地看到本次访问的执行路径,如下图所示。Visitor 对语法树的各个部分进行了遍历,ANTLR4 会根据定义的语法规则对各个节点的访问生成默认方法。Apache ShardingSphere 对关键方法进行了覆盖,从而完成 SQL 的格式化功能。
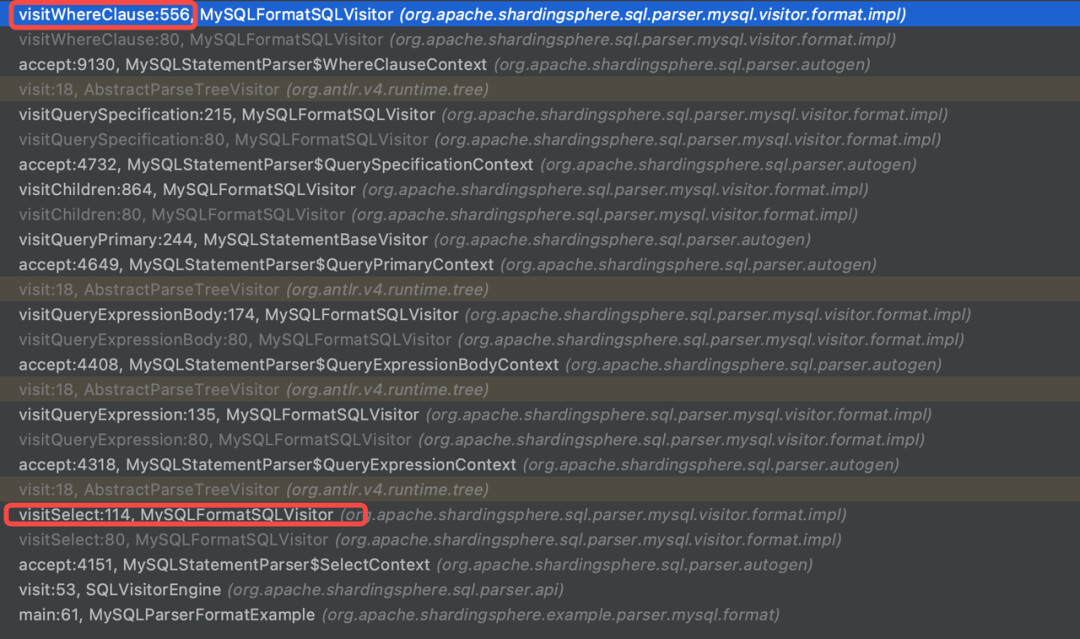
通过如下代码片段可以帮助我们理解 Visitor 实现格式化的方式。当 Visitor 遍历到了 select 之后,会首先对其格式化,接着访问 projection,projection 内部格式化的实现,会进一步通过 visitProjections 方法实现。在访问 from 之前会先空行处理。Visitor 实例化的对象内部会维护一个 StringBuilder 用来存储格式化的结果。因为每条 SQL 使用的解析器和访问器都是新实例化的对象,因此也不会存在线程安全的问题。最后遍历结束后,Apache ShardingSphere 会将 StringBuilder 的结果输出,那么我们也就得到了格式化的 SQL。
public String visitQuerySpecification(final QuerySpecificationContext ctx) {
formatPrint("SELECT ");
int selectSpecCount = ctx.selectSpecification().size();
for (int i = 0; i < selectSpecCount; i++) {
visit(ctx.selectSpecification(i));
formatPrint(" ");
}
visit(ctx.projections());
if (null != ctx.fromClause()) {
formatPrintln();
visit(ctx.fromClause());
}
if (null != ctx.whereClause()) {
formatPrintln();
visit(ctx.whereClause());
}
if (null != ctx.groupByClause()) {
formatPrintln();
visit(ctx.groupByClause());
}
if (null != ctx.havingClause()) {
formatPrintln();
visit(ctx.havingClause());
}
if (null != ctx.windowClause()) {
formatPrintln();
visit(ctx.windowClause());
}
return result.toString();
}
相信通过上述的过程分析和代码展示,读者朋友们都能够大概了解到 SQL Parse Format 的原理了。
SQL Parse Format 使用指南
在了解了 SQL Parse Format 的原理之后,使用 SQL Parse Format 也非常简单了。
对于 Java 应用而言,只需要添加依赖,调用 api 即可。
- 引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-engine</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-sql-parser-mysql</artifactId>
<version>${project.version}</version>
</dependency>
- 调用 api
public static void main(String[] args) {
String sql = "select order_id from t_order where status = 'OK'";
CacheOption cacheOption = new CacheOption(128, 1024L, 4);
SQLParserEngine parserEngine = new SQLParserEngine("MySQL", cacheOption, false);
ParseContext parseContext = parserEngine.parse(sql, false);
SQLVisitorEngine visitorEngine = new SQLVisitorEngine("MySQL", "FORMAT", new Properties());
String result = visitorEngine.visit(parseContext);
System.out.println(result);
}
- Properties 支持参数如下
参数名 |
类型 |
默认值 |
说明 |
upperCase |
boolean |
true |
关键字是否大写 |
parameterized |
boolean |
true |
参数是否用 ? 代替 |
projectionsCountOfLine |
int |
3 |
每行查询列最大个数 |
如果使用 ShardingSphere-Proxy 那么还可以通过 DistSQL 语法来使用 SQL Parse Format 功能。
mysql> FORMAT select order_id from t_user where status = 'OK';
+-----------------------------------------------------+
| formatted_result |
+-----------------------------------------------------+
| SELECT order_id
FROM t_user
WHERE
status = 'OK'; |
+-----------------------------------------------------+
对于前文提到的 Statement 方式的解析引擎,也可以方便地查看将 SQL 转化为 SQLStatement 的结果。
mysql> parse SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18;
+----------------------+---------------------------------------+
| parsed_statement | parsed_statement_detail
+----------------------+--------------------------------------+
| MySQLSelectStatement | {"projections":{"startIndex":7,"stopIndex":14,"distinctRow":false,"projections":[{"column":{"startIndex":7,"stopIndex":8,"identifier":{"value":"id","quoteCharacter":"NONE"}}},{"column":{"startIndex":11,"stopIndex":14,"identifier":{"value":"name","quoteCharacter":"NONE"}}}]},"from":{"tableName":{"startIndex":21,"stopIndex":26,"identifier":{"value":"t_user","quoteCharacter":"NONE"}}},"where":{"startIndex":28,"stopIndex":63,"expr":{"startIndex":34,"stopIndex":63,"left":{"startIndex":34,"stopIndex":50,"left":{"startIndex":34,"stopIndex":39,"identifier":{"value":"status","quoteCharacter":"NONE"}},"right":{"startIndex":43,"stopIndex":50,"literals":"ACTIVE"},"operator":"\u003d","text":"status \u003d \u0027ACTIVE\u0027"},"right":{"startIndex":56,"stopIndex":63,"left":{"startIndex":56,"stopIndex":58,"identifier":{"value":"age","quoteCharacter":"NONE"}},"right":{"startIndex":62,"stopIndex":63,"literals":18},"operator":"\u003e","text":"age \u003e 18"},"operator":"AND","text":"status \u003d \u0027ACTIVE\u0027 AND age \u003e 18"}},"unionSegments":[],"parameterCount":0,"commentSegments":[]} |
+----------------------+----------------------------------------------+
更多 DistSQL 功能欢迎查看 DistSQL 文档
结语
目前 Apache ShardingSphere 只实现了 MySQL 方言的格式化功能,其它方言还未实现,相信了解了原理和使用的你一定也能够轻松参与到 SQL Parse Format 功能的开发中。如果你对参与贡献开源代码有兴趣,也欢迎来到社区参与贡献,相信通过贡献代码,你能更深刻地理解 Apache ShardingSphere 的相关功能。
GitHub issue:
贡献指南:
https://shardingsphere.apache.org/community/cn/contribute/
中文社区: