
转载至 ShardingSphere 官微
京东白条使用 Apache ShardingSphere 解决了千亿数据存储和扩容的问题,为大促活动奠定了基础。
2014 年初,“京东白条”作为业内互联网信用支付产品,数据量爆发式的增长,每一次大促备战都是对技
术人员的考验,每一次的战略转型驱动着数据架构的成长。
–张栋芳,京东白条研发负责人
京东白条数据架构演进史
自 2014 年 2 月京东白条业务上线起,为满足快速发展的业务和激增的海量数据,白条的数据架构经历了数次演进。
· 2014~2015
Solr + HBase 的方案解决了核心、非核心业务系统对关键数据库的访问问题,Solr 作为被检索字段的索引,HBase 用作全量的数据存储。
- 通过 Solr 集群分担部分读和写的业务,缓解核心库的压力;
- Solr 扩展体验上欠佳,对业务也存在较大的入侵。
· 2015~2016
引入 NoSQL 方案,业务数据以月份进行分表存储在 MongoDB 集群中,阶段性满足了结算处理场景中海量数据导入导出的需求。
- 查询热点数据效率高,非结构化的存储方式易于修改表结构;
- 依然面对着扩展差、对业务入侵强的局面,而且耗内存。
· 2016~2017
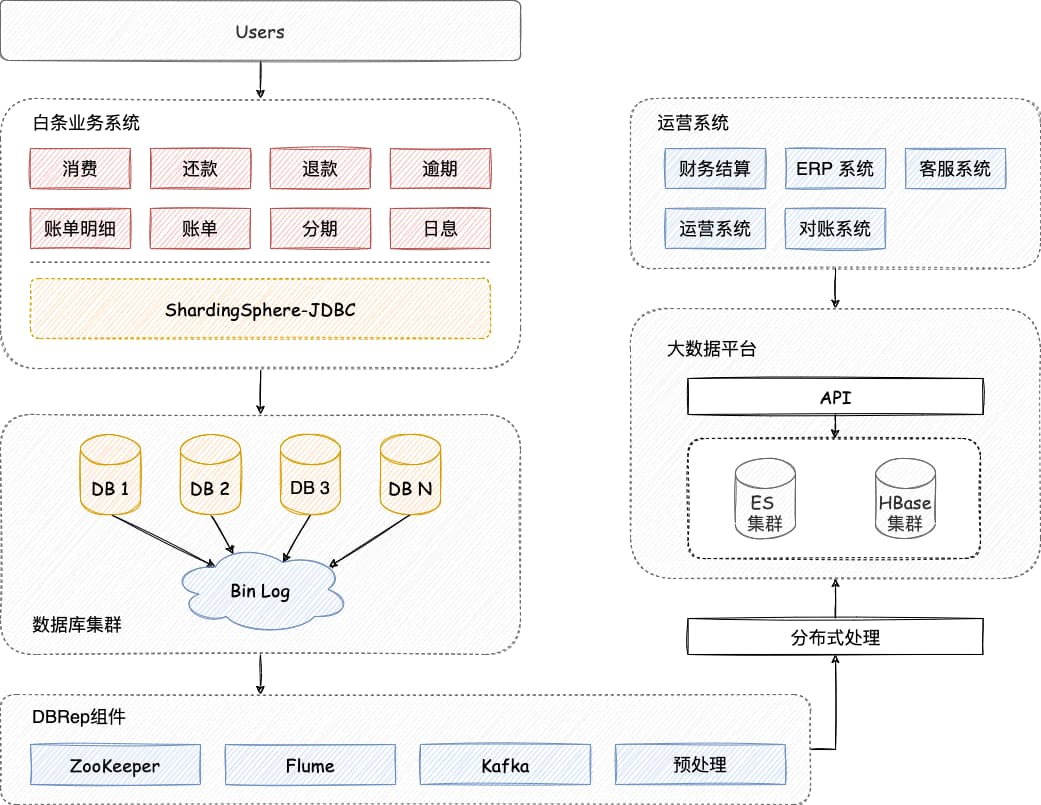
随着业务快速发展,数据量突破百亿大关,此时 MongoDB 面临着容量和性能的双重考验。京东白条大数据平台通过 DBRep 以 MySQL Slave 的形式采集变动信息并存储到消息中心,最后落盘到 ES 和 HBase 中。
-
该方案具有较强的数据实时性,扩展性良好;
-
基于业务框架的数据分片难以降低代码维护成本。
白条数据架构的演进间接地反应了互联网消费金融的飞速发展,也说明了每一种解决方案在不同背景下都有不同的保质期。
迫在眉睫的架构解耦
为保证业务系统在数据激增情况下始终能保持高效运行,技术团队在设计初期使用了数据分片数据架构,发挥极致性能的同时也兼顾代码的可控性,采用基于应用框架的数据拆分方案完成了数据拆分工作。
但随着产品升级迭代,早期的解决方案演变成为了眼前的问题,通过业务框架实现的数据分片方案导致业务代码复杂度增加、维护成本不断攀升,紧耦合的弊端原形毕露,应用每次升级都需要投入较多的精力对分片做相应调整,研发人员难以专注于业务本身。
面对如上问题,技术团队经权衡后开始考虑使用成熟的分库分表组件来承担这部分工作,让业务系统升级和架构调整不再复杂。基于自研框架分片和基于 ShardingSphere 分片的对比如下:
| 基于自研框架分片 | 基于 ShardingSphere 分片 | |
|---|---|---|
| 性能 | 高 | 高 |
| 代码耦合度 | 高 | 低 |
| 业务入侵程度 | 高 | 低 |
| 升级难度 | 高 | 低 |
| 扩展度 | 一般 | 良好 |
下一阶段工作,解耦。
显然京东白条数据架构将迎来一个新的阶段,解耦的驱动力可以概括如下 3 方面:
-
聚焦精力:将基于架构的数据库拆分,交给分表组件实现,研发精力需聚焦于业务本身;
-
简化升级:解耦技术架构,简化业务系统升级工作的研发流程;
-
规划未来:为系统提供良好的扩展能力,从容应对“618”和“11. 11”等活动。
京东白条业务体量巨大,是名副其实的金融级高并发、海量数据的业务场景,因此分库分表组件应具有以下特点:
-
产品成熟稳定
-
极致性能表现
-
处理海量数据
-
架构灵活扩展
Apache ShardingSphere 解决方案
ShardingSphere-JDBC 是 Apache ShardingSphere 的第一款产品,它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
ShardingSphere-JDBC 的以下特点能够很好地满足白条业务场景:
-
**产品成熟:**经数年打磨产品成熟度高,且社区活跃;
-
**性能良好:**微内核、轻量化的设计,性能损耗极小;
-
**改造量小:**支持原生的 MySQL 协议,研发工作量小;
-
**扩展灵活:**搭配使用迁移同步组件轻松实现数据扩展。
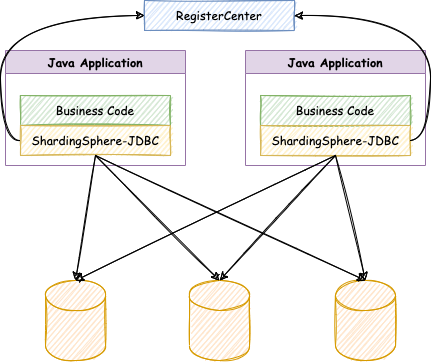
经内部大量系统性验证之后,Apache ShardingSphere 成为了京东白条数据分片中间件的首选方案,2018 年底正式开始对接。
产品适配
为能全面支撑白条业务、提供更好的业务体验,Apache ShardingSphere 在京东白条业务落地过程中对产品的功能和性能方面进行了更多的支持和提升,产品再一次经历典型案例的打磨。
- 升级 SQL 引擎
白条的业务逻辑非常复杂且庞大,多样化场景的需求对 SQL 的兼容程度有着较高要求,Apache ShardingSphere 重构了 SQL 解析模块,并支持了更多的 SQL。
-
路由至单数据节点 ,SQL 100% 兼容;
-
路由至多数据节点,可全面支持 DML、DDL、DCL、TCL 和部分 DAL。支持分页、去重、排序、分组、聚合、关联查询。
-
分布式主键
Apache ShardingSphere 提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE 等分布式主键生成器。同时 Apache ShardingSphere 提供了分布式主键生成器的接口,用户可自定义自增主键生成算法来满足特殊场景的需求。
- 业务分片键值注入
对于没有分片条件的 SQL,Apache ShardingSphere 使用 ThreadLocal 管理分片键值,通过编程的方式向 HintManager 中添加分片条件,该分片条件仅在当前线程内生效,实现了 SQL 零侵入。
除了对功能上的增强,Apache ShardingSphere 为满足京东白条业务严苛的性能要求,同时做了多方面调优。
-
SQL 解析结果缓存
-
JDBC 元数据信息缓存
-
Bind 表 & 广播表的使用
-
自动化执行引擎 & 流式归并
经两团队通力合作,京东白条业务与 Apache ShardingSphere 相结合的各项指标满足预期,性能与原生 JDBC 几乎一致。
关于对接过程中的问题详情及方案,请通过《Apache ShardingSphere 对接京东白条实战》一文来了解。
业务割接
Apache ShardingSphere 使用定制化 HASH 策略对数据进行分片,有效避免了热点数据问题,拆分后的数据节点数达近万个,整个割接过程大约持续了 4 周左右的时间。
-
DBRep 读取数据,通过 Apache ShardingSphere 将数据同步至目标数据库集群;
-
两套集群并行运行,数据迁移后再使用自研工具对业务和数据进行校验。
DBRep 是 ShardingSphere-Scaling 产品设计的基石,Scaling 具备的自动化能力为后续的迁移扩容工作提供了更多的便利。
Apache ShardingSphere 带来的收益
- 简化升级路径
通过架构解耦,业务系统升级所涉及技术栈得到有效缩短,研发团队不再需要关注分表设计,精力全部聚焦于业务本身,升级路径得到大幅度优化;
- 节省研发力量
引入成熟的 Apache ShardingSphere 无需重新开发分表组件,在简化业务升级路径的基础上节省了大量研发力量;
- 架构灵活扩展
搭配使用 Scaling 同步迁移组件从容面对“618”和“11.11”等大型活动,系统灵活扩容。
写在最后
京东白条业务的快速增长驱动着数据架构不断升级,本次架构演进通过引入 Apache ShardingSphere 助力白条架构解耦,简化了系统升级路径,使研发团队只需关注业务本身,同时也实现了数据架构的灵活扩展,在消费金融场景开启了良好的开端。
互联网信用消费模式发展逐步多样化,未来 Apache ShardingSphere 将与京东展开更多业务场景的实践和探索,通过推动金融科技创新发展,进一步提升互联网金融的创新速度和效率。
ShardingSphere 作为 Apache 基金会下的顶级开源项目,在 GitHub 上获得了超 14K Star 的关注,已成为行业内受欢迎的开源项目,全球有超过 170 家企业用户登记使用,覆盖金融、电子商务、云服务、旅游、物流、教育、文娱等多个领域。
- 欢迎更多技术团队约稿投稿,和大家分享使用 ShardingSphere 的经验思考。如需转载请后台私信留言,对案例感兴趣的伙伴可联系社区经理,(我们也会不定期为社区发展做贡献的热心伙伴送上精美周边噢