
状态:原创
一、业务背景
F6汽车科技,一家专注于汽车后市场信息化建设的互联网平台公司,为维修企业开发智慧管理平台。各个维修企业(后文简称商户)之间的数据是相互隔离的,不同商户之间的数据理论上可以存储在不同库不同表。随着公司业务发展迅速,有些表的数据量增长迅速,单表总的数据量达到千万甚至亿的级别,系统越来越难以满足业务的高速发展。另外随着业务发展公司也在对系统进行拆分,按照不同域不同业务拆分成许多微服务,随之也就垂直拆分成了不同的业务库。
二、技术背景
关系型数据库由于单机存储容量、连接数、处理能力都有限,容易成为系统瓶颈。从性能上看,当单表的数据量达到千万以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间。另外单库的连接数有限,如果数据库查询的QPS过高,那么就需要通过分库来分担单个数据库的连接压力。从可用性上看,单个数据库如果发生意外,很可能会丢失所有数据,影响所有业务,分库可以隔离故障,减少业务的影响范围。通常,表的体积大于2G或者行数大于1000w,并且数据快速增长,这个时候就要考虑进行分库分表。
三、分库分表介绍
根据业界经验,分库分表有以下四种常见形式:
-
垂直分表——大表拆小表,基于字段进行,将一些不常使用或长度较大字段拆分成扩展表;
-
垂直分库——基于业务边界进行数据库层面的拆分,解决单库的性能瓶颈;
-
水平分表——横向分表,将表中的数据行按照一定规律分布到不同的表中,降低单表数据量,优化查询性能,但是库级别还存在瓶颈;
-
水平分库分表——在水平分表基础上,将数据进一步分布到不同的库中,有效缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源的瓶颈;
业界常用的分库分表解决方案有以下几种
1、Sharding-JDBC(ShardingSphere)
优点:
-
Apache成员,社区活跃,目前已经升级至4.0.0版本,仍处于快速迭代中;
-
成功应用案例多,京东、当当等大公司广泛应用;
-
使用简单,Sharding-JDBC快速集成项目,不需要部署额外服务;
-
兼容性好,路由至单数据节点,SQL100%支持;
-
性能优异,损耗低,官网有给测试结果;
缺点:
- 增加运维成本,分表后修改字段,增加索引繁琐——可以部署Sharding-Proxy解决,支持异构语言,对运维友好;
- 尚未支持分片数据动态迁移,需要开发功能实现;
2、MyCat
优点:
-
MyCat是介于应用与数据库之间,进行数据处理与交互的中间服务,对研发无感知,接入成本低
-
支持JDBC连接ORACLE、DB2、SQL Server、MYSQL等不用数据库
-
支持多语言、跨平台;部署和实施简单
-
高可用,故障自动切换
缺点:
- 运维成本高,得配置Mycat的一系列参数以及高可用负载均衡的配置
- 需要单独部署一个服务,增加了系统风险
其他类似的解决方案如:Cobar、Zebra、MTDDL、tidb就没有过多的去研究了,有兴趣的可以自己去研究下。结合公司实际情况我们选择了ShardingSphere。
四、ShardingSphere简介
Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
主要功能
-
数据分片——分库 & 分表;读写分离;分片策略定制化;无中心化分布式主键;
-
分布式事务——标准化事务接口;两阶段提交事务;柔性事务;
-
数据库治理——配置动态化;编排 & 治理;数据脱敏;可视化链路追踪;弹性伸缩 (规划中);
Sharding-JDBC
功能特性
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架;
-
适用于任何基于Java的ORM框架。
-
基于任何第三方的数据库连接池。
-
支持任意实现JDBC规范的数据库。
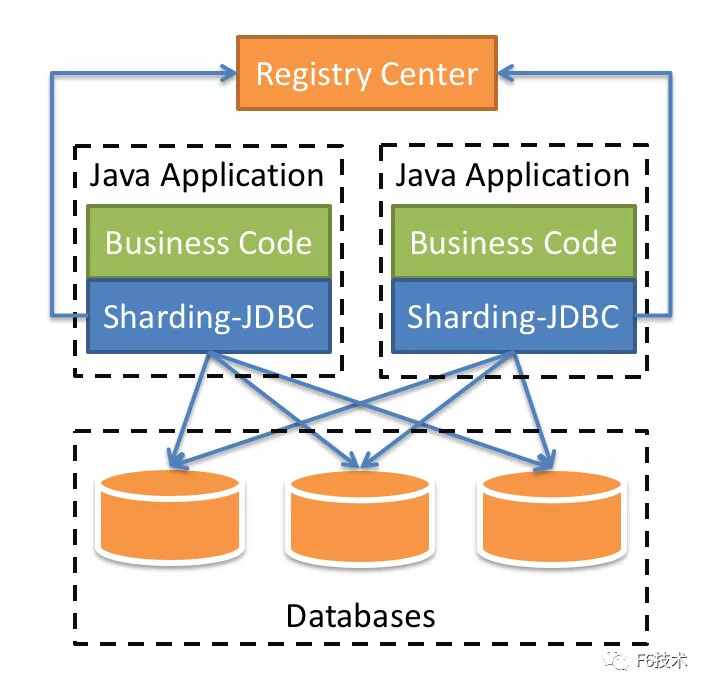
通过注册中心,可以实现简单的治理功能,将数据分片、读写分离相关配置放入注册中心进行管理。
基本概念
-
逻辑表——具有相同结构的水平拆分数据表的总称,实际使用中直接针对逻辑表编程,由Sharding-JDBC负责SQL解析、改写及路由
-
真实表——在分片的数据库中真实存在的物理表,真正负责数据存储的表;
-
数据节点(actual-data-nodes)——数据分片的最小单元,由数据源名称和数据表组成。
-
分片策略——包含分片键和分片算法,分片键指用于分片的数据库字段,分配算法则是具体的分片方法,Sharding-JDBC内置了五种分片策略;
-
主键生成策略(key-generator)——通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复,本文采用SNOWFLAKE算法;
基本原理
Sharding-JDBC(4.x版本)数据分片主要流程为:
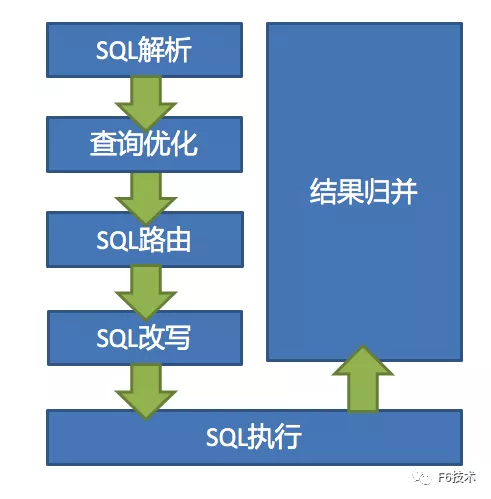
-
SQL解析——分为词法解析和语法解析。先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。由于第三代解析引擎使用ANTLR进行SQL解析,大大提升了SQL语句的兼容性,号称路由至单数据节点100%兼容;
-
执行器优化——对分片条件进行合并及优化;
-
SQL路由——根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由,如果使用时未传递分片键,则会使用广播路由,影响性能;
-
SQL改写——将SQL改写为真实可执行的SQL,由逻辑表、逻辑索引,转换成真实表、真实索引。可以分为正确性改写及优化改写;
-
SQL执行——通过多线程执行器异步执行;
-
结果归并——归并结果集统一输出结果;
五、总体方案
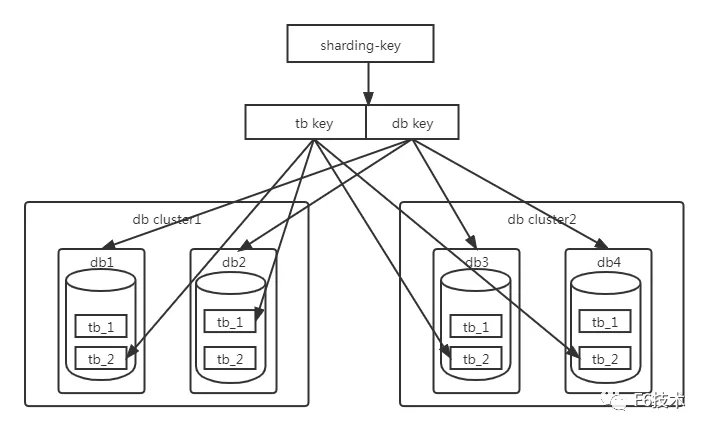
按照公司现有业务逻辑,因此采用商户ID作为分片键(ShardingKey),保证一个商户的工单数据,分配在同一个库同一个单表中,避免了多表查询关联的性能损耗,后期分片到多个库时,可以避免跨库事务及跨库JOIN。
商户ID数据库中的类型为BIGINT(20),为了保证后续分库扩容的需求,采用基因法,选取商户ID最后两位作为分库基因,按照双倍扩容的规则,可以最大扩展到64个库中。剩余位数的值用于分表,分片到32个分表中。
规则如下(10545055917999668983为某商户ID):
105450559179996689 83
分表基因值 % 32 分库基因值 % 1
最后两位83用于分库,暂时数据只分片到f6xxx一个库中,因此余数为0,后期数据量增加,扩展至多个库。剩余数值105450559179996689用于分表,首次分为32个单表,取模余数对应具体的分表下标,为0~31。
按照公司系统现状及开发功能能快速迭代分步上线的背景,因此我们制定了先分表再拆库的方案,考虑到分库分表改动影响比较大,因此需要灰度上线,一旦有问题需要快速回滚,不能影响正常业务。具体实施步骤如下:
分表
(1)工程从jdbc切到Sharding-JDBC数据源连接方式
(2)写库业务解耦和代码迁移
(3)历史数据和增量数据同步
(4)切分表
分库
(1)读库业务迁移
(2)数据迁移
(3)切读库
(4)切写库
六、分表
分表个数选择
根据业界经验,单个表的数据尽量控制在500万条以内,分表的数量为2的n次方,方便扩展;根据业务的发展速度和未来的数据增长量,并结合未来的数据归档方案计算出分表个数。分表个数和分片算法定义好之后,就可以评估已有数据划分到每个分表之后的数据量。
准备工作
数据库表的自增id替换
由于分表之后依赖数据库的自增id不能再用了,需要考虑使用其他方案,可行性方案有:
1、用其他主键【比如snowflake】
2、自己实现步长(数据库、redis)

通过对比上述方案和考虑现状,我们采用了方案2,共通组提供了表级别的全局自增id实现方案。
排查所有请求是否带上分片键
现有的微服务流量入口
-
http
-
dubbo
-
xxljob定时任务
-
mq消息
分表之后,为了能快速定位数据在哪一个分片,需要所有请求都带上分片键
业务解耦
1、各个域之间业务解耦,读写数据均通过接口交互
2、去除直接表join的场景,改走接口
业务解耦带来的最大问题就是分布式事务问题,如何保证数据的一致性,业界通常的做法就是引入分布式事务组件保证事务一致性或者使用补偿等机制保证数据的最终一致性。
灰度切换方案
为了保证新功能在出问题时能够快速回滚,所有线上修改都按照商户逐步切换原则进行上线。我们考虑的灰度方案如下:
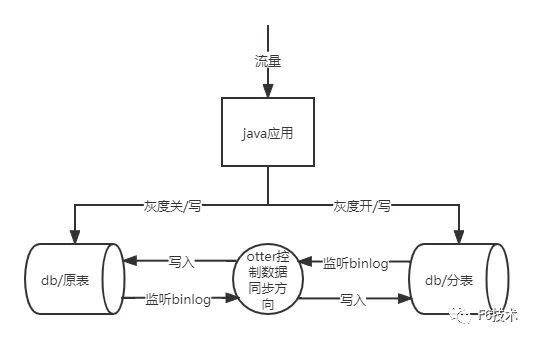
1、维护两套mapper接口,一套使用Sharding-JDBC数据源连接db,另一套mapper使用jdbc数据源连接db,在service层按照灰度开关判断选择那一套接口,流程图如下:
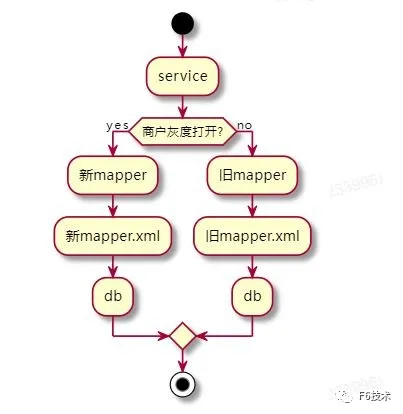
上述实现方案会导致所有访问mapper层的代码都有一个if else 分支,改动比较多,对业务代码有侵入,代码也难以维护,因此我们考虑了如下的方案二。
2、自适应选择mapper方案:一套mapper接口对应两个数据源两套实现,不同商户请求会根据灰度配置走不同的mapper实现,一个service对应两个数据源两套事务管理器,不同商户请求会根据灰度配置走不同的事务管理器。根据上述思路我们利用mybatis的多个mapperScanner完成多个mapperInterface的生成,同时再次生成一个mapperInterface完成包装,包装类里面支持hintManger自动选择多种mapper;事务管理器类似也是生成一个包装类,包装类里面支持hintManger自动选择多种事务管理器管理事务。这个方案避免了对业务代码的入侵,对service层业务代码来说,就只有一套mapper接口。
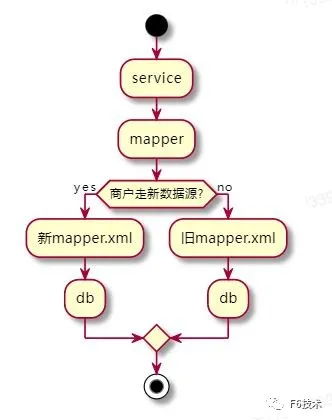
业务切数据源连接
Sharding-JDBC除了官网给定的一些不支持的语法,我们在开发当中也发现了下列一些sql语法Sharding-JDBC解析出来会有问题:
-
子查询不带分片键
-
insert 语句values里带 cast ifnull now 等函数时不支持
-
不支持ON DUPLICATE KEY UPDATE
-
select for update 默认走从库(4.0.0.RC3版本修复)
-
Sharding-JDBC不支持MySqlMapper(乐观锁查询版本号)中ResultSet.first()语法
-
批量更新语法不支持
-
UNION ALL不支持
按照之前设计的灰度上线方案,我们只需复制一套mapper.xml,然后按照Sharding-JDBC的语法修改好即可上线。
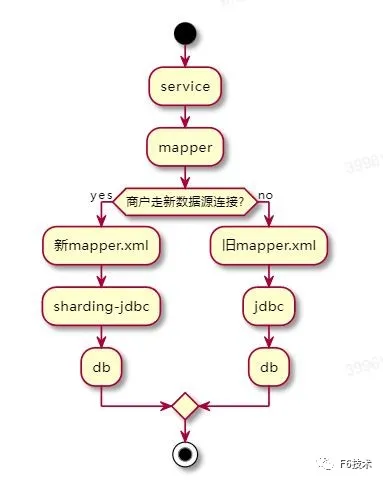
历史数据同步
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
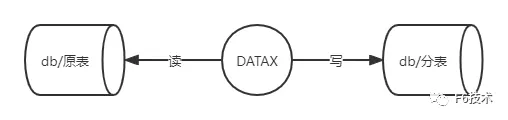
同步数据校验
- 使用定时任务对比原表和分表的数据条数
- 使用定时任务对比关键字段的值
业务读写切换分表
在业务正式读写分表之前,我们需要配置好增量数据的同步。
增量数据同步
使用otter工具进行同步,otter 基于数据库增量日志解析,准实时同步到本机房或异地机房的mysql/oracle数据库. 一个分布式数据库同步系统(https://github.com/alibaba/otter),使用过程中需要注意以下事项:
-
mysql数据库必须开启binlog,且模式为ROW;同步的表必须有主键;
-
用户必须要有binlog的查询权限,申请单独的otter用户
-
目前dms数据库的binlog只保存3天,otter可以自定义binlog同步的起始位置,增量同步的起点,查看方法:sql平台上选择slave-testDb,用sql语句“show master status”即可查询,特别注意下:master和slave的“show master status”执行结果不一样,如果设置的话需要拿主库的执行结果。这个功能特别好用,当我们再用otter同步数据出错的时候,我们可以重设点位,从头开始在同步一次。
-
otter停用会自动记录同步的最后点位信息,下次会继续从这个点位开始同步。
-
otter支持业务自定义处理过程,比如我们控制商户同步数据的方向分表到总表还是总表到分表,数据路由规则等
-
otter停用启动不会使otter自定义处理过程里面定义的缓存失效,解决办法是:修改代码注释重新保存
读写切分表
灰度切换方案如下:
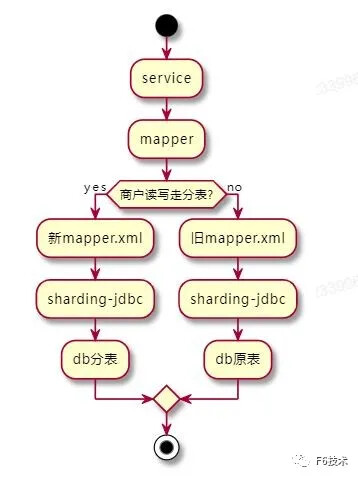
由于是灰度切换,需要保障分表和原表的数据都是实时更新的,所以数据需要双向同步,商户灰度开关开的门店,读写走分表,数据通过otter实时同步到原表。商户灰度开关关闭的门店,读写走原表,数据通过otter实时同步到分表。
七、分库
准备工作
主键
主键需要为自增类型(分表需要全局自增)或者接入全局唯一递增主键发号服务(不依赖DB的server_id),像表自增生成主键的方法或者使用uuid_short生成主键的方法需要切换。
存储过程、函数、触发器、EVENT
如果有,尽量先安排去掉;如果下不掉,提前在新数据库新建好
数据同步
数据同步采用的DTS或者sqldump(历史数据)+otter(增量数据)进行同步
DTS:数据传输服务DTS(Data Transmission Service)是阿里云提供的实时数据流服务,支持RDBMS、NoSQL、OLAP等,集数据迁移/订阅/同步于一体,为您提供稳定安全的传输链路。https://www.aliyun.com/product/dts/
otter:上文已介绍过
切库步骤
为避免可能的性能问题和兼容性问题,切库方案必须满足两个准则
- 灰度切换:流量逐步切换到rds(阿里云关系型数据库,简称 RDS),随时观察数据库性能
- 快速回滚:出现问题能快速切换,不影响用户使用
现状: 四个应用实例+db一主两从
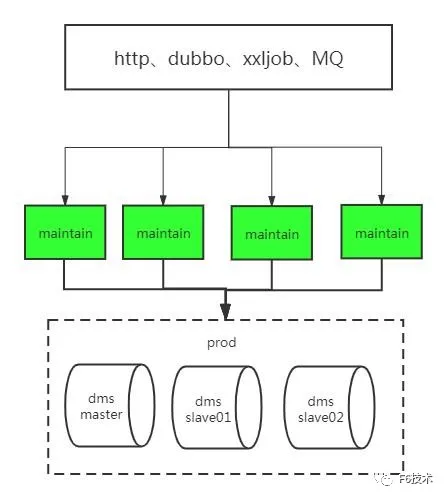
步骤一: 新增加一个应用实例,切读到rds库,写还是走dms master库,dms master的数据会通过otter实时同步到rds
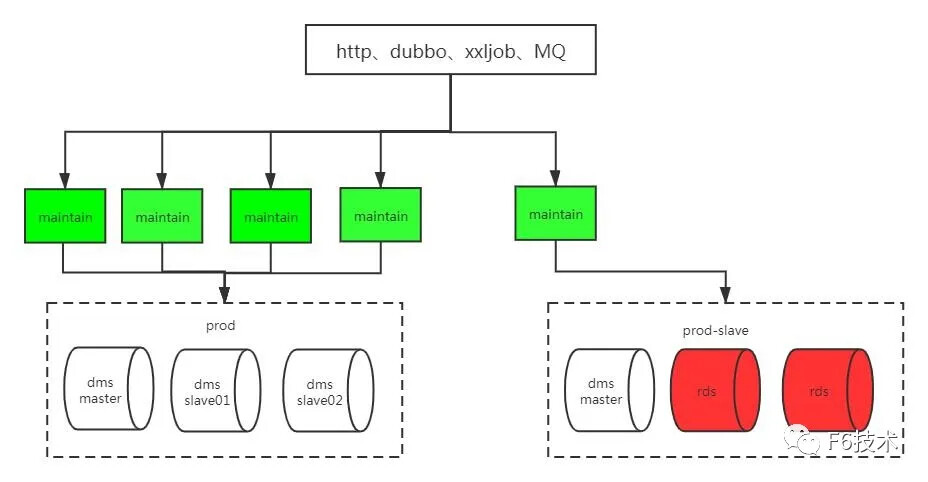
步骤二: 再增加到3个应用实例,切50%流量的读到rds库
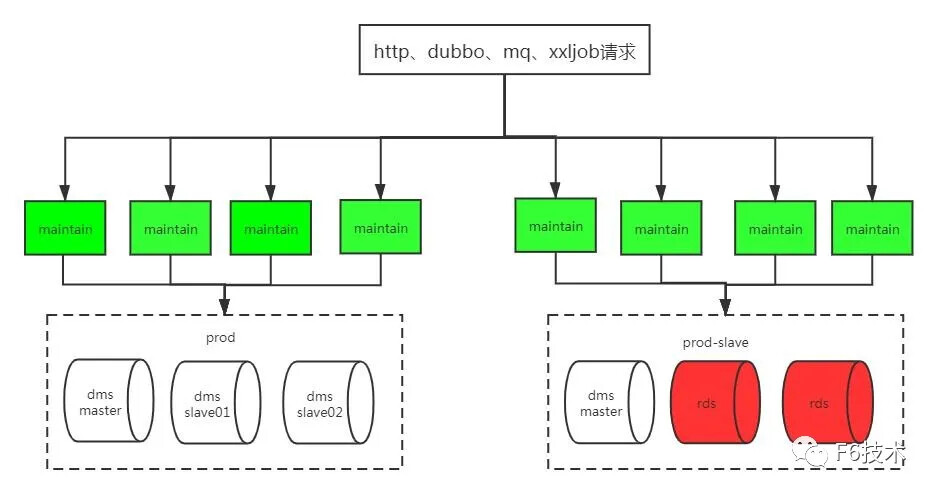
步骤三: 摘掉原来的四个实例流量,全部读切到rds实例,写还是走dms master库
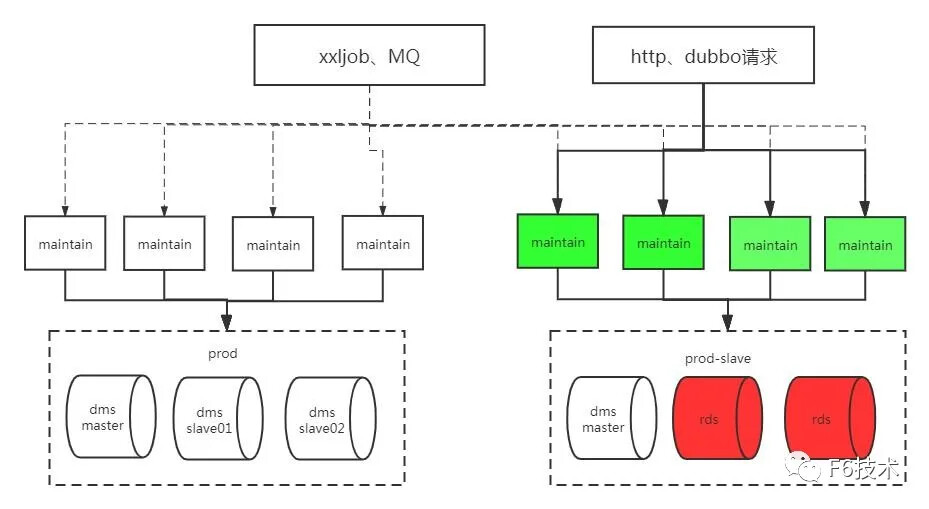
步骤四: 切主库到rds,为了方便切流量回滚,此时rds的数据会通过otter反向同步到dms master库
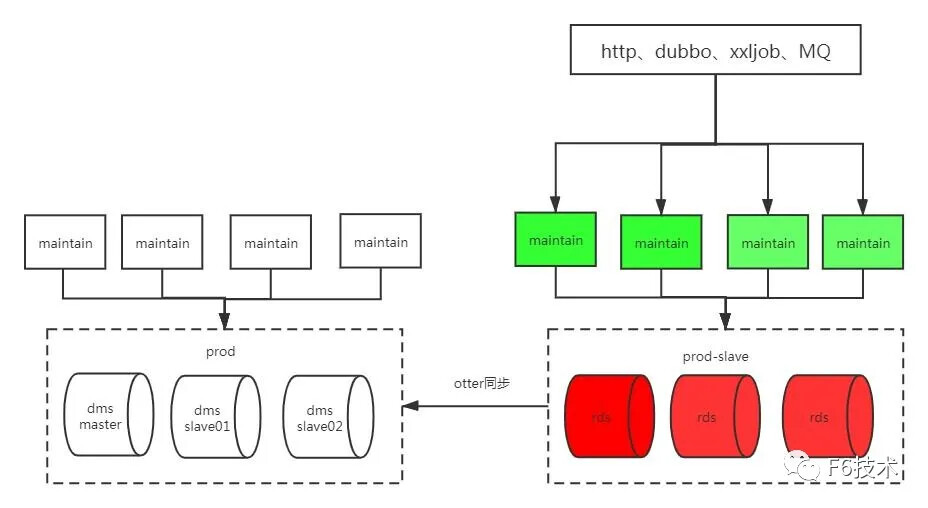
步骤五: 完成
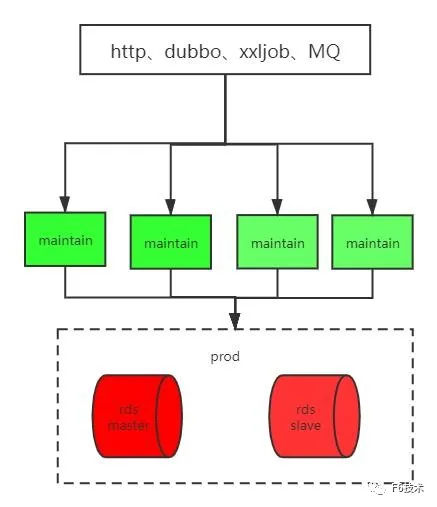
上述每一个步骤都可以通过切换流量快速进行回滚,保障系统的可用性和稳定性。
八、分库分表扩容
当单库的性能达到瓶颈时,我们可以通过修改分库路由算法和迁移数据来达到库的扩容。
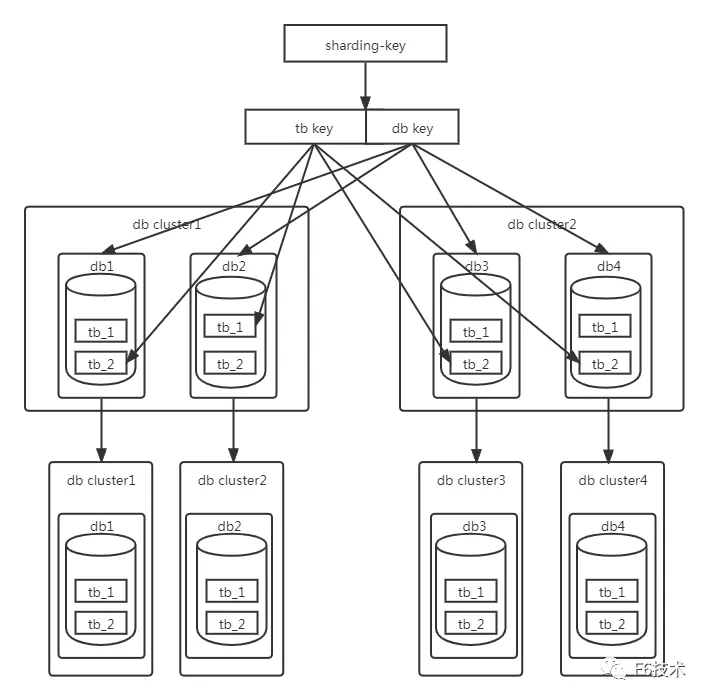
当单表的容量达到瓶颈时,我们可以通过修改分表路由算法和迁移数据来达到分表的扩容。

FAQ
1、otter接收到binlog数据之后再去反查数据库偶尔查不到数据?
解答: 我们MySQL为了兼容其它非事务引擎的复制,在server层面引入了 binlog, 它可以记录所有引擎中的修改操作,因而可以对所有的引擎使用复制功能;然而这种情况会导致redo log与binlog的一致性问题;MySQL通过内部XA机制解决这种一致性的问题。
第一阶段:InnoDB prepare, write/sync redo log;binlog不作任何操作;
第二阶段:包含两步,1> write/sync Binlog;2> InnoDB commit (commit in memory);
当然在5.6之后引入了组提交的概念,可以在IO性能上进行一些提升,但总体的执行顺序不会改变。
当第二阶段的第1步执行完成之后,binlog已经写入,MySQL会认为事务已经提交并持久化了(在这一步binlog就已经ready并且可以发送给订阅者了)。在这个时刻,就算数据库发生了崩溃,那么重启MySQL之后依然能正确恢复该事务。在这一步之前包含这一步任何操作的失败都会引起事务的rollback。
第二阶段的第2大部分都是内存操作,比如释放锁,释放mvcc相关的read view等等。MySQL认为这一步不会发生任何错误,一旦发生了错误那就是数据库的崩溃,MySQL自身无法处理。这个阶段没有任何导致事务rollback的逻辑。在程序运行层面,只有这一步完成之后,事务导致变更才能通过API或者客户端查询体现出来。
binlog发送在前,db commit在后,所以才出现上述问题。我们解决此问题是通过查询重试解决。
2、同一个查询请求查询不同表时,偶尔部分表查不到数据?
解答: Sharding-JDBC主从路由策略如下:
选择走主库的场景:
-
包含lock语句的sql,比如select for update(4.0.0.RC3版本)
-
非select语句
-
同一个线程前面已经走过主库了
-
代码指定走主库
多个从库选择算法:
- 轮询
- 负载均衡策略
当没有配置默认的负载均衡策略的时候就默认使用轮询策略。同一个查询可能走不同的从库,也有可能走主库和从库,当主从延迟或者多个从库延迟时间不一样时就会发生此问题。
3、流量怎么摘除?
解答: 1) http流量通过nginx摘除upstream去掉;
-
dubbo通过其内部提供的qos模块执行offline/online命令摘除流量;
-
xxljob通过手动录入执行器的执行ip指定具体的实例执行;
-
MQ通过阿里云提供的api启动或者关闭消费者bean。
参考文档: