
数据库中间件ShardingSphere-ShardingJdbc使用(三)数据脱敏
背景:
对于用户的个人敏感信息,如密码、身份证号、家庭住址等信息,在进行存储数据库之前,都需要进行加密。使得即使存入数据库之后,数据库的管理员看到的数据也是加密的。这一过程叫做数据脱敏。
一些安全框架如shiro、spring security都提供了加密的手段。这里ShardingJdbc也提供了内置的加密方式,MD5、AES。
关于数据脱敏的详细文档参考官方数据脱敏部分
配置:
这里使用前两篇的配置(数据分片、读写分离)基础上再加上数据脱敏配置
server:
port: 8999
spring:
application:
name: mybatis-demo
shardingsphere:
datasource:
# 数据库的别名
names: ds0,ds1,ds0-slave0,ds0-slave1
# 主库1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/dhb?serverTimezone=UTC
password: 12345
username: root
# 主库1的从库1
ds0-slave0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3307/dhb?serverTimezone=UTC
password: 12345
username: root
# 主库1的从库2
ds0-slave1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3308/dhb?serverTimezone=UTC
password: 12345
username: root
# 主库2
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3310/dhb?serverTimezone=UTC
password: 12345
username: root
# 数据分片配置---start
sharding:
# 默认分库策略
default-database-strategy:
inline:
sharding-column: id
algorithm-expression: ds$->{id % 2}
# 默认分表策略
default-table-strategy:
inline:
sharding-column: age
algorithm-expression: user_$->{age % 2}
# 数据节点
tables:
user:
actual-data-nodes: ds$->{0..1}.user_$->{0..1}
# 默认数据库
default-data-source-name: ds0
# 数据分片配置---end
# 读写分离配置---start
master-slave-rules:
ds0:
master-data-source-name: ds0
slave-data-source-names: ds0-slave0,ds0-slave1
#从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。
#若`load-balance-algorithm-class-name`存在则忽略该配置
load-balance-algorithm-type: ROUND_ROBIN
#从库负载均衡算法类名称。该类需实现MasterSlaveLoadBalanceAlgorithm接口且提供无参数构造器
#load-balance-algorithm-class-name=
# 读写分离配置---end
# 数据脱敏规则配置---start
encrypt-rule:
encryptors:
encryptor_aes:
# 加密、解密器的名字,内置的为MD5,aes.
# 可以自定义,实现
# org.apache.shardingsphere.encrypt.strategy.spi.Encryptor
# 或者
# org.apache.shardingsphere.encrypt.strategy.spi.QueryAssistedEncryptor
# 这两个接口即可
type: aes
props:
aes.key.value: 123456abc
tables:
# 数据库,对应上面分片的tables
user:
columns:
# 逻辑列,就是写SQL里面的列,因为实体类的名字和数据库的加密列一致,所以这里都是name
name:
# 密文列,用来存储密文数据
cipherColumn: name
# 加密器名字
encryptor: encryptor_aes
# 数据脱敏规则配置---end
props:
# 打印SQL
sql.show: true
check:
table:
metadata: true
# 是否在启动时检查分表元数据一致性
enabled: true
query:
with:
cipher:
column: true
aop:
proxy-target-class: false
# 因为Druid数据源和默认的数据源冲突,添加此配置
main:
allow-bean-definition-overriding: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
logic-not-delete-value: 0
logic-delete-value: 1
mapper-locations: classpath:/mapper/*.xml
typeAliasesPackage: com.example.mybatis.demomybatis.entity
[image]
测试:
1、插入一条数据
[image]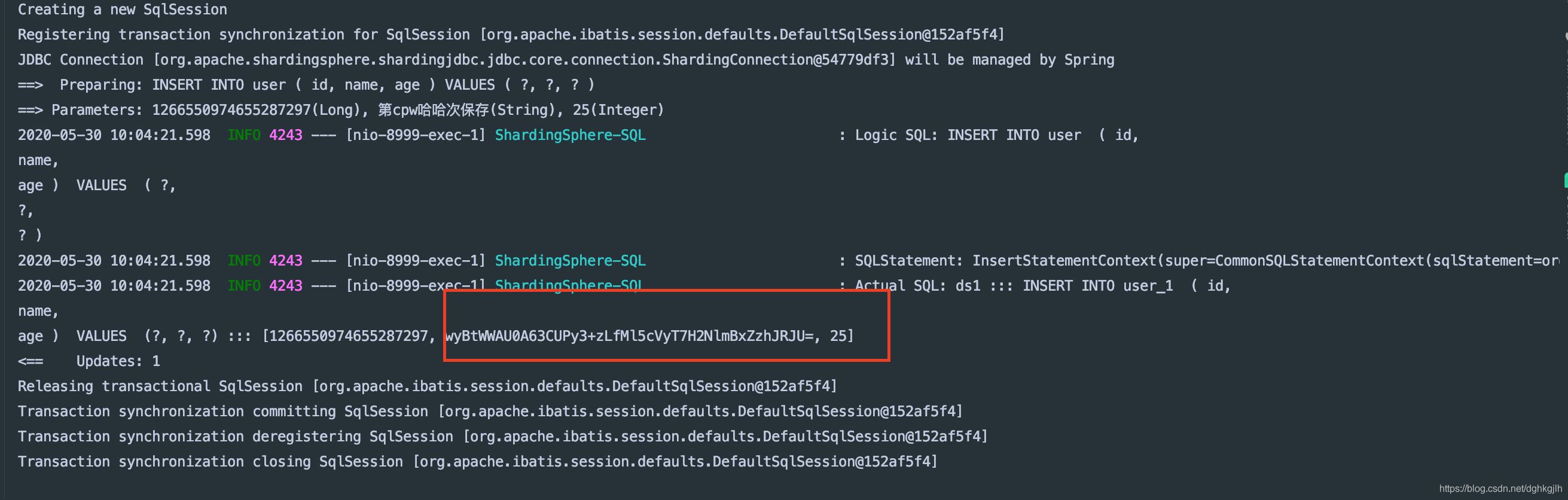
可以看到,根据之前的分片规则,将这条数据路由到ds1(3310实例)的user_1表中,并且插入之前,将name字段进行加密了
2、查询刚刚插入的数据
[image]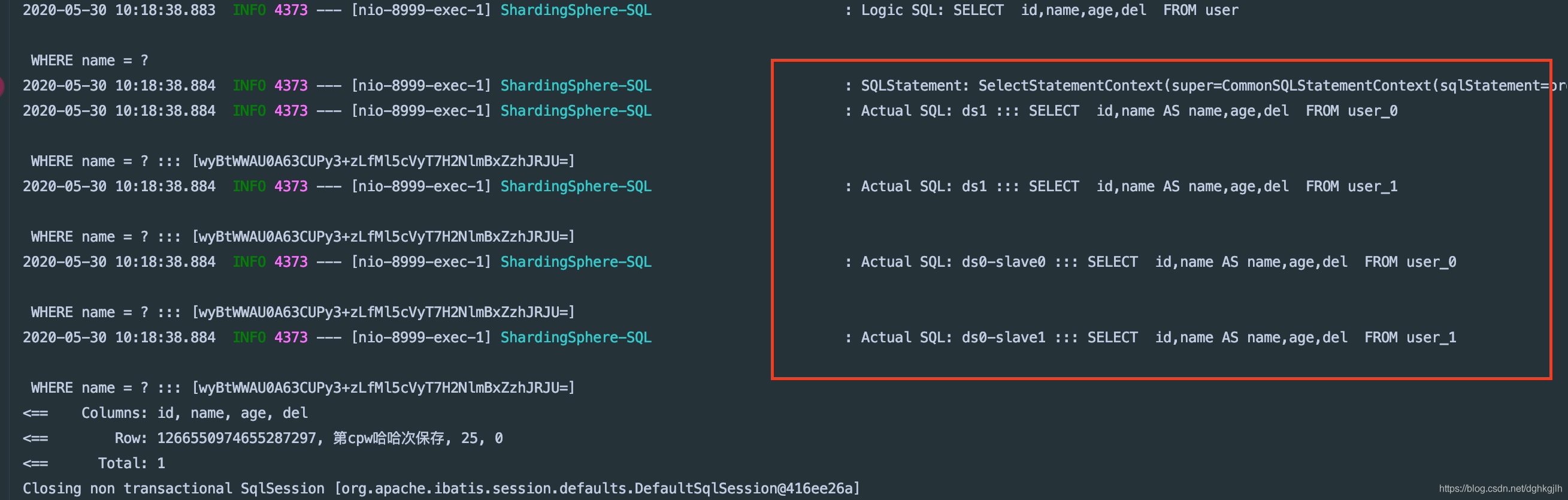
可以看到,查询出来的name也是被解密的。这样数据脱敏就完成了。
问题1:这里为什么查询了四张表?
回答:因为前面文章配置的数据分片,是id(分库策略)、age(分表策略),而查询name属性并没有配置为分片键,这时候会进行全路由即查询所有表,实际生产环境万万不可这样写
问题2:既然是全路由,不是一共配置了八张表(每个数据库下都要user_0,user_1两张表)吗,为什么查了四张表?
回答:因为前面文章配置的读写分离(ds0-slave0、ds0-slave1)是ds的从库,默认读写分离是读都走从库,所以这里应该是两个从库+一个主库,应该是6张表,但是这里却是四张表。这里我确实是有疑惑,已经在GitHub上提了问题,看看官方会不会解答一下。
文章涉及到的代码、配置已经全部放到GitHub上了,如有需要,自取。地址
6月1日更新:
官方已经回复了,全路由是对于分片而言的,如果数据分片+主从架构 这种场景下,在不同的数据库下相同的表名,则被视为同一张表
状态:原创(CSDN博主
JackSparrow414)