
数据库中间件ShardingSphere-ShardingJdbc使用(一)数据分片
背景:
我们实际开发中,总有几张和业务相关的大表,这里的大表是指数据量巨大。如用户表、订单表,又或者公司业务中的主表,可能很快这种表的数据就达到了百万、千万、亿级别的规模,并且增长规模一直很快。这种情况下,单表已经满足不了了存储需求了,同时,这么大的数据量,即使搭配合理的索引,数据库查询也是很慢的。这时就需要对这些大表进行分库、分表。
例如:
user表现在数据增长很快,这时对user库、表。通过部署多个MySQL实例来进行拓展。每个MySQL实例上都会有user库,每个user库里又有user_N(N为0,1…),N张数据结构一致,只不过表名不同的user表,来存储数据。
分库、分表的基本原则为:
建议每个表的数据量不超过1000万行数据
分表的数目选择:
N =(未来3到5年内总共的记录行数) / 单张表建议记录行数 (单张表建议记录行数 = 1000万)
N就是每个库的分表数。建议一次分够,如果因为分不够造成的扩容,是很麻烦的,特别是分表的键是采用hash算法分的
分库的数目选择:
按照存储容量来计算 = (3到5年内的存储容量)/ 单个库建议存储容量 (单个库建议存储容量 <300G以内)
使用ShardingSphere的原因是,原来很多的数据库中间件都已不再维护,如mycat、tddl,只有ShardingSphere一直维护,并且今年成功从Apache毕业,成为顶级项目。美团开源的Zebra的配置和ShardingSphere相比,太过复杂.
对数据库中间件设计的文章感兴趣的同学,可以看下美团这篇文章
数据库中间件有两种代理方案,客户端代理(DataSource)、服务端代理(数据库代理),以下内容引用自美团文章
- 服务端代理(proxy:代理数据库)中: 我们独立部署一个代理服务,这个代理服务背后管理多个数据库实例。而在应用中,我们通过一个普通的数据源(c3p0、druid、dbcp等)与代理服务器建立连接,所有的sql操作语句都是发送给这个代理,由这个代理去操作底层数据库,得到结果并返回给应用。在这种方案下,分库分表和读写分离的逻辑对开发人员是完全透明的。
- 客户端代理(datasource:代理数据源): 应用程序需要使用一个特定的数据源,其作用是代理,内部管理了多个普通的数据源(c3p0、druid、dbcp等),每个普通数据源各自与不同的库建立连接。应用程序产生的sql交给数据源代理进行处理,数据源内部对sql进行必要的操作,如sql改写等,然后交给各个普通的数据源去执行,将得到的结果进行合并,返回给应用。数据源代理通常也实现了JDBC规范定义的API,因此能够直接与orm框架整合。在这种方案下,用户的代码需要修改,使用这个代理的数据源,而不是直接使用c3p0、druid、dbcp这样的连接池
ShardingSphere-jdbc属于客户端(数据源代理)
ShardingSpehere将分库、分表统称为数据分片
一、添加依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.0</version>
</dependency>
[image]
二、配置
server:
port: 8999
spring:
application:
name: mybatis-demo
shardingsphere:
datasource:
# 数据库的别名
names: ds0,ds1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/dhb?serverTimezone=UTC
password: 12345
username: root
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3310/dhb?serverTimezone=UTC
password: 12345
username: root
sharding:
# 默认分库策略
default-database-strategy:
inline:
sharding-column: id
algorithm-expression: ds$->{id % 2}
# 默认分表策略
default-table-strategy:
inline:
sharding-column: age
algorithm-expression: user_$->{age % 2}
# 数据节点
tables:
user:
actual-data-nodes: ds$->{0..1}.user_$->{0..1}
# 默认数据库
default-data-source-name: ds0
props:
# 打印SQL
sql.show: true
check:
table:
metadata:
# 是否在启动时检查分表元数据一致性
enabled: true
# 因为Druid数据源和默认的数据源冲突,添加此配置
main:
allow-bean-definition-overriding: true
[image]
配置说明:
本地有两个MySQL实例,分别为3306、3310,每个数据库下都有dhb数据库,每个数据库都有user_0、user_1两张user表,如下图:
[image]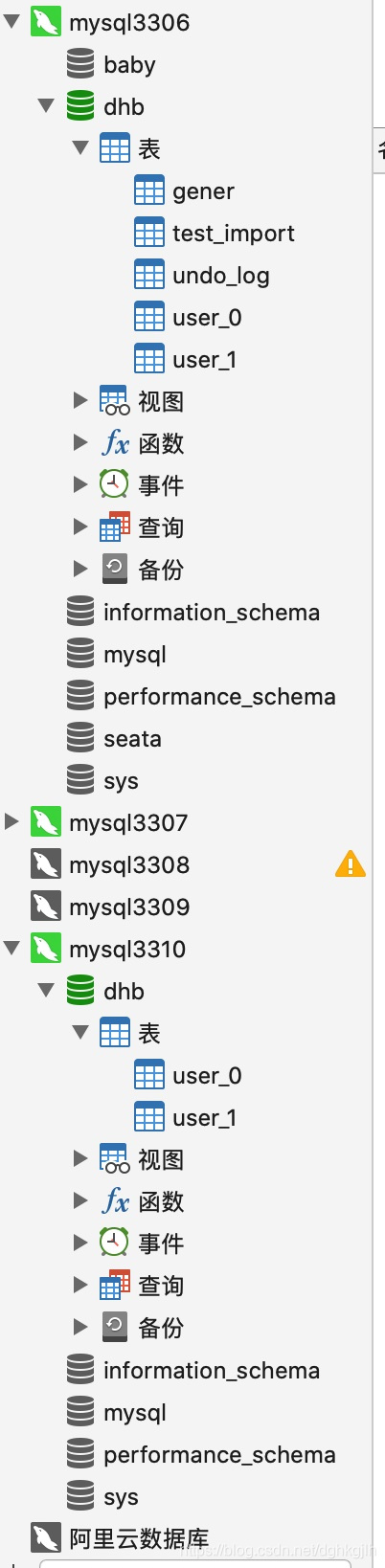
配置文件说明:
配置文件中的分库策略是将根据id %2 ,结果如果是0,则走ds0,实例3306的数据库;结果是1,则走ds1,实例3310的数据库。
选择了数据库之后,怎么选择入哪一张表呢?根据age % 2,如果为0,则走user_0,如果是1,则走user_1。
关于逻辑表、真实表、数据节点概念参见官方文档
配置文件中分片,属于行表达式分片,实际业务中,可以自己实现官方的接口,实现自己业务需要的分库、分表算法,具体实现的4个接口参见分片。StandardShardingStrategy、ComplexShardingStrategy、HintShardingStrategy
关于行表达式的写法可见官方example
特别注意:
如果使用了阿里的Druid数据源,启动的时候会报数据源冲突,则使用上述配置文件的最后一行配置即可。
三、实体类,使用、Lambok和Mybatis-plus简化操作,这里的table名字是逻辑表名字-user,实际对应的表有ds0.user_0、ds0.user_1、ds1.user_0、ds1.user_1四张表
@Data
@TableName(value = "user")
public class UserItem {
@TableId
private Long id;
private String name;
private Integer age;
private Integer del;
}
[image]
四、使用。插入一条数据
控制台打印SQL入下
[image]
最终shardingsphere-jdbc最终根据配置的分库、分表策略将数据写入ds0-3306实例库中的user_1表中。
当查询的时候,如果条件是根据分片键查询,那么最终定位到某一个库的某一个表,如果条件中没有分片键,则会进行全路由,也就是四个库都查
ShardingSphere-jdbc为我们做了,根据配置的分片策略,进行 SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并 工作。具体文档见内核剖析
以上仅仅是一个使用小例子,实际业务场景比这更复杂,如主子表的分片、分片表和为分片的表join查询等等
状态:原创(CSDN博主
JackSparrow414)