
数据库中间件ShardingSphere-ShardingJdbc使用(二)读写分离
背景:
简单的分库、分表有时候并不能有效抵挡大流量的查询,除去缓存的存在,仅仅考虑数据库层面上。可以搭建主从复制架构,可以使写操作在主库进行,主库和从库之间通过异步复制、半同步复制保持数据一致。所有的读操作都在主库的N个从库上进行。通过负载均衡使得每一次查询均匀的落在每一个从库上
由于硬件资源有限,为了模拟主从读写分离,在一台机器上搭建多个MySQL实例,并配置主从关系。如果不知道怎么部署、配置,可参考单机部署MySQL多实例和主从复制搭建
上一篇文章已经有了两个主库,3306、3310。为3306实例部署两个从库,3307、3308。
Sharding-Jdbc读写分离也仅需要简单的配置即可使用
一、配置文件修改:
server:
port: 8999
spring:
application:
name: mybatis-demo
shardingsphere:
datasource:
# 数据库的别名
names: ds0,ds1,ds0-slave0,ds0-slave1
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/dhb?serverTimezone=UTC
password: 12345
username: root
ds0-slave0:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3307/dhb?serverTimezone=UTC
password: 12345
username: root
ds0-slave1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3308/dhb?serverTimezone=UTC
password: 12345
username: root
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3310/dhb?serverTimezone=UTC
password: 12345
username: root
sharding:
# 默认分库策略
default-database-strategy:
inline:
sharding-column: id
algorithm-expression: ds$->{id % 2}
# 默认分表策略
default-table-strategy:
inline:
sharding-column: age
algorithm-expression: user_$->{age % 2}
# 数据节点
tables:
user:
actual-data-nodes: ds$->{0..1}.user_$->{0..1}
# 默认数据库
default-data-source-name: ds0
master-slave-rules:
ds0:
master-data-source-name: ds0
slave-data-source-names: ds0-slave0,ds0-slave1
#从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。
#若`load-balance-algorithm-class-name`存在则忽略该配置
load-balance-algorithm-type: ROUND_ROBIN
#从库负载均衡算法类名称。该类需实现MasterSlaveLoadBalanceAlgorithm接口且提供无参数构造器
#load-balance-algorithm-class-name=
props:
# 打印SQL
sql.show: true
check:
table:
metadata:
# 是否在启动时检查分表元数据一致性
enabled: true
aop:
proxy-target-class: false
# 因为Druid数据源和默认的数据源冲突,添加此配置
main:
allow-bean-definition-overriding: true
mybatis-plus:
configuration:
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
logic-not-delete-value: 0
logic-delete-value: 1
mapper-locations: classpath:/mapper/*.xml
typeAliasesPackage: com.example.mybatis.demomybatis.entity
[image]
读写分离主要配置在master-salve-rules配置下面,关于读数据时的从库负载均衡策略可使用 ROUND_ROBIN、RANDOM两种。如果这两种不能满足需求,还可以自定义负载均衡算法,实现MasterSlaveLoadBalanceAlogorithm接口。更多细节可参考官方读写分离文档部分
二、测试:
分别进行四次查询,可以看到sharding-jdbc每一次都是在两个从库之间切换,如下图:
[image]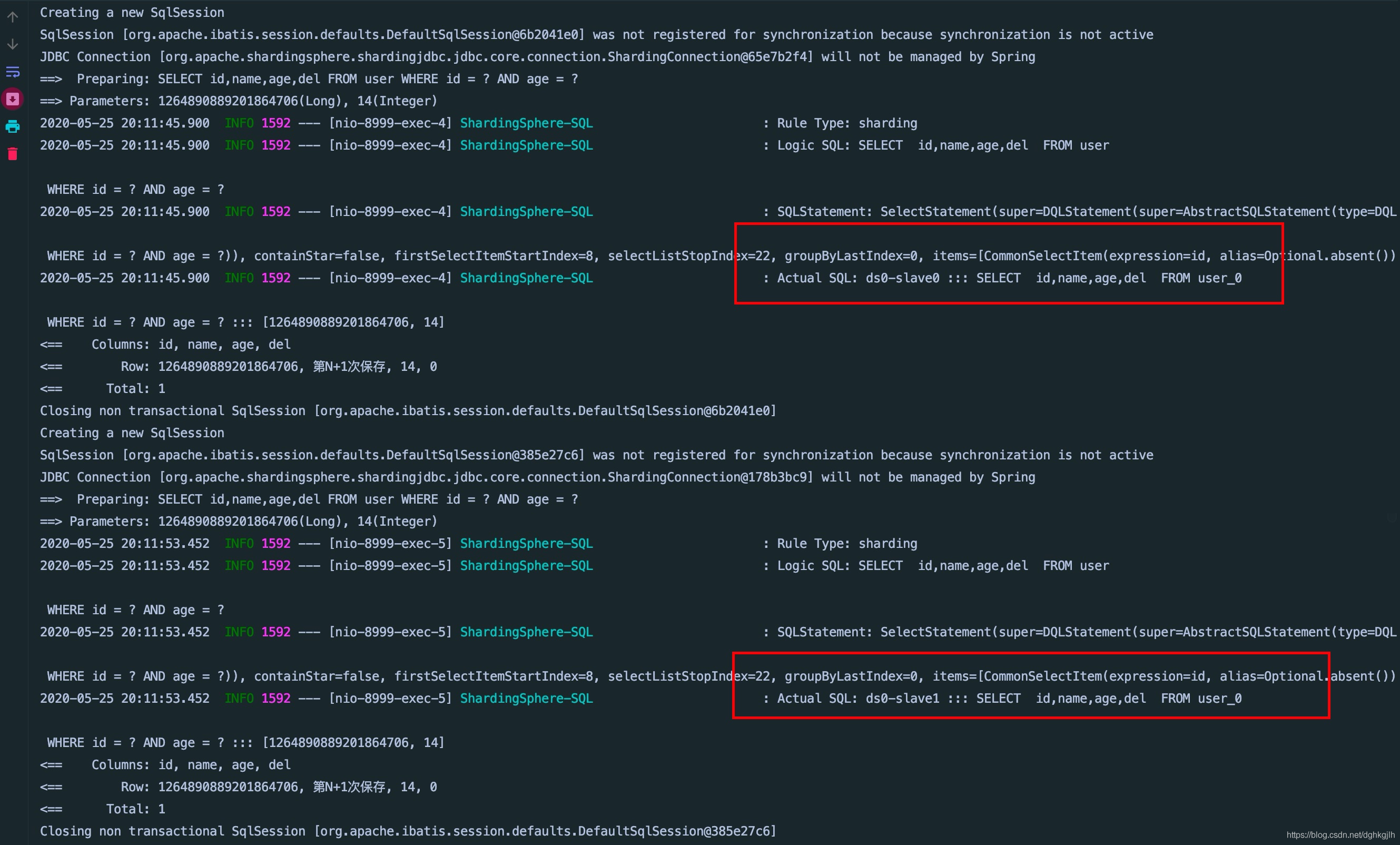
总的来说,无论是数据分片、还是读写分离,sharding-sphere都帮我们屏蔽了底层细节,并且让我们使用起来就像对单表操作一样。特别方便
疑惑:
在读写分离时,第一次的查询总是很慢,目前还不知道什么原因,哪位同学知道原因希望留言一下,十分感谢!
示例代码已放到GitHub上,如有需要,请自取。示例代码地址
状态:原创(CSDN博主
JackSparrow414)