
ShardingSphere-ShardingJDBC实现思路解析
这里使用的版本为ShardingJDBC 4.1.1版本。
传统JDBC的使用
方式1-通过DriverManager
Class.forName("com.mysql.cj.jdbc.Driver");
Connection connection = DriverManager.getConnection(url, user, password);
PreparedStatement preparedStatement = connection.prepareStatement("insert into t_user (id, name) values (?, ?)");
preparedStatement.setInt(1, 12);
preparedStatement.setString(2, "this is paramter");
preparedStatement.executeUpdate();
// 如果执行的是查询,还要关闭ResultSet
// resultSet.close();
preparedStatement.close();
connection.close();
方式2-通过DataSource
DruidDataSource datasource = new DruidDataSource();
dataSource.setDriverClassName(driver);
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement("select * from t_user");
ResultSet resultSet = preparedStatement.executeQuery();
while(resultSet.next()) {
int id = resultSet.getInt(1);
int gener = resultSet.getInt(2)
}
resultSet.close();
preparedStatement.close();
connection.close();
以上两种方式,现在基本上会采用第二种方式了。通过连接池管理数据源,做到连接的复用,节省资源。但是上面两种方式的核心步骤是一样的。即
- 加载驱动
- 获取连接-Connection
- 获取StateMent-PreparedStatement
- 为SQL赋值-PreparedStatement.setXXX(paramterIndex, value)
- 执行SQL-PreparedStatement.executeXXX();
- 获得结果集-ResultSet
- 依次关闭各种连接-XXX.close();
SharingJdbc流程解析
-
启动时,加载所有数据源(DBCP数据源、Druid数据源、C3P0数据源)配置,将其作为Map,设置为具体数据源(分片数据源、主从数据源、影子数据源)的属性。此数据源为==逻辑上的数据源==。为什么说是逻辑上的数据源呢?后面会解释。
流程详解:
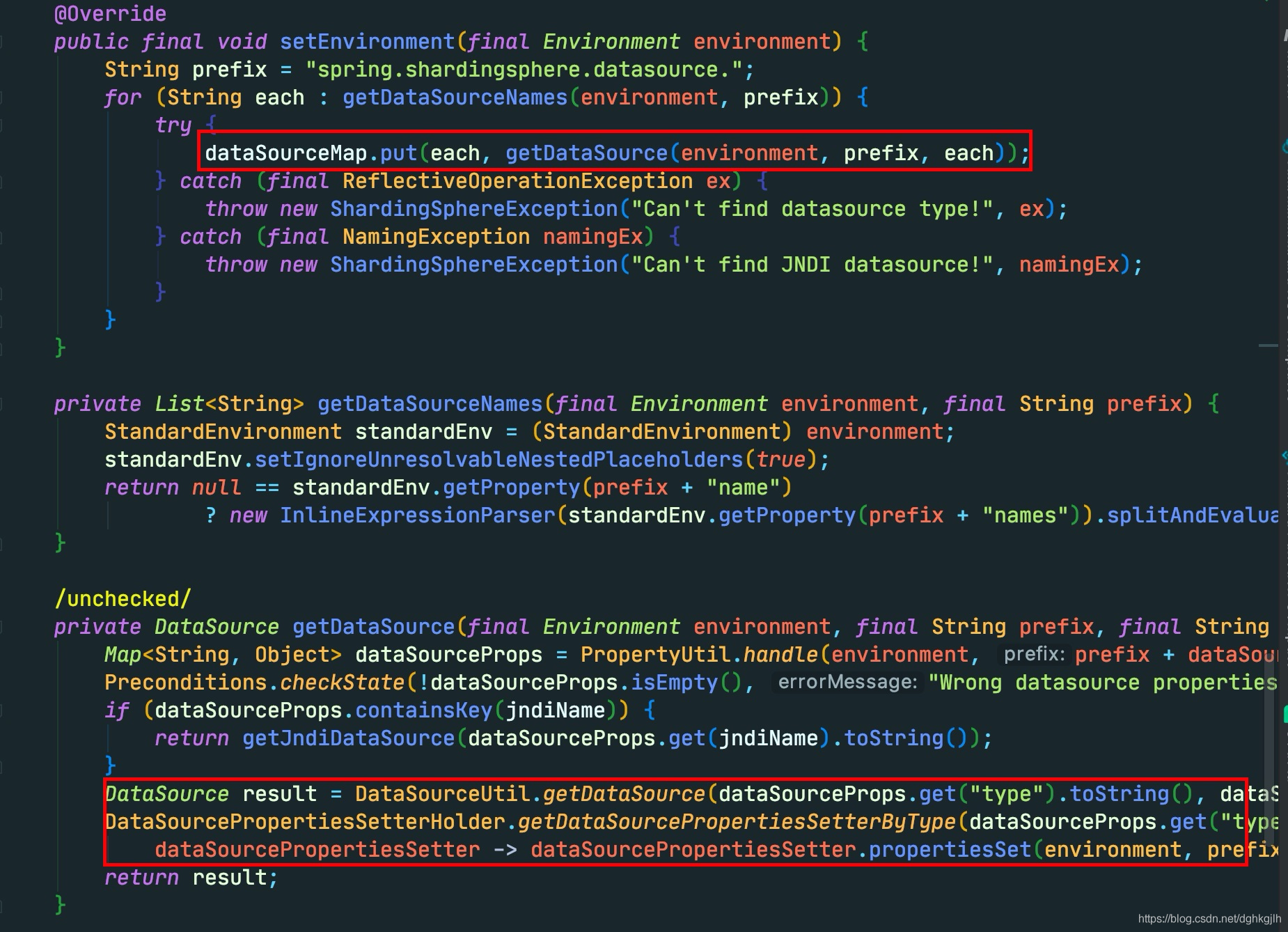
SpringBootConfiguration这个类继承了EnvironmentAware接口(一般实现这个接口都是为了读取具体配置文件里的属性),实现了setEnvironment(Environment environment)方法。
完成的操作是将所有在配置文件中配置的数据源放到一个Map<数据源名字, 数据源实例>中。主要看下这里实例化数据源的步骤,拿到配置文件下每一个数据源的type,假定这里type是 com.alibaba.druid.pool.DruidDataSource
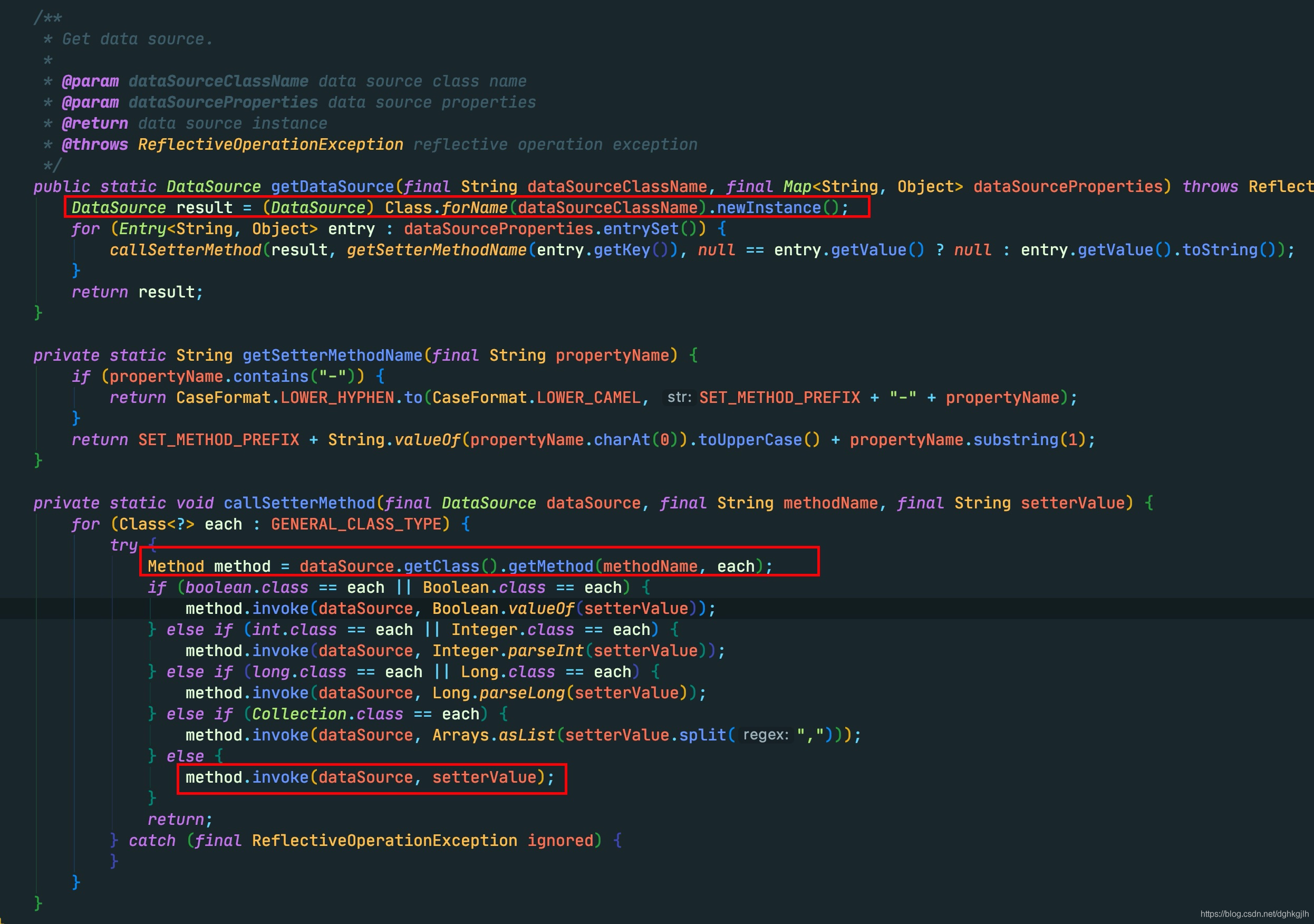
可以看到直接通过Class.forName().newInstance();方法具体实例化每一个数据源。实例化之后,要将其他属性设置进数据源中,这里首先通过字符串拼接某些属性的Set方法,如,数据源里配置的url,这里拼接完成为setUrl.下一步通过callSetterMethod方法,进行反射调用set方法,将配置文件的具体数据源的其他属性赋值。完成这些之后,会放到上面的Map中。执行完setEnvironment方法之后,执行其他代码。
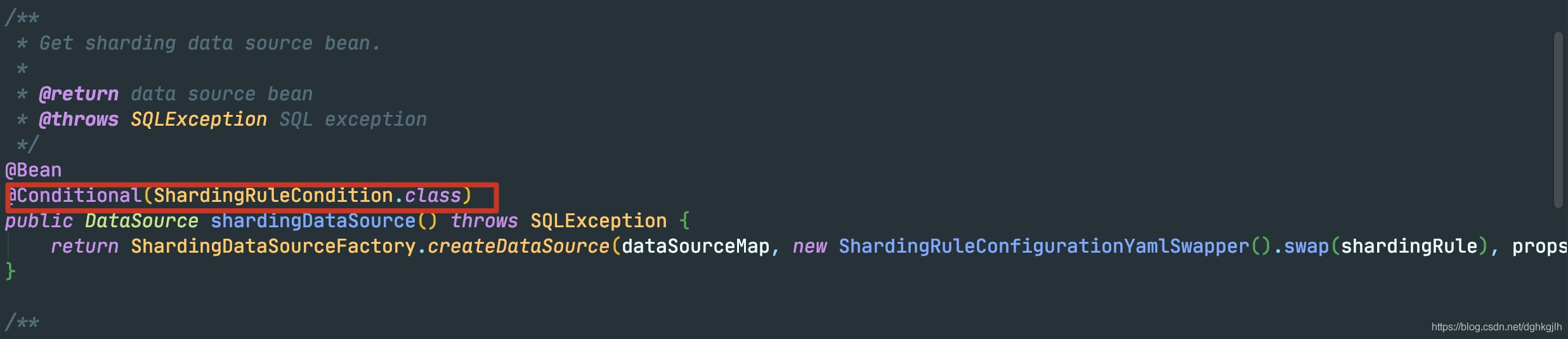
当==@Conditional==条件满足时,会认为当前配置的为分片操作。于是new一个ShardingDataSource,将刚才设置好的map当做一个属性设置进去。
为什么要自定义数据源?既然拿到了具体的数据源为什么还要自定义一个数据源?
原因1-如果在使用Mybatis,Mybatis的SqlSessionFactoryBean要进行数据源的设置(setDataSource方法),如果此时没有数据源,在afterPropertiesSet()方法里会进行数据源的检查,如果为null,则会报错。(因为SqlSessionFactoryBean实现了==InitializingBean==接口,所以要实现afterPropertiesSet()方法)
-
开始进行分片查询、新增、删除、更新。执行SQL前的准备
以使用Mybatis的插入操作为例。
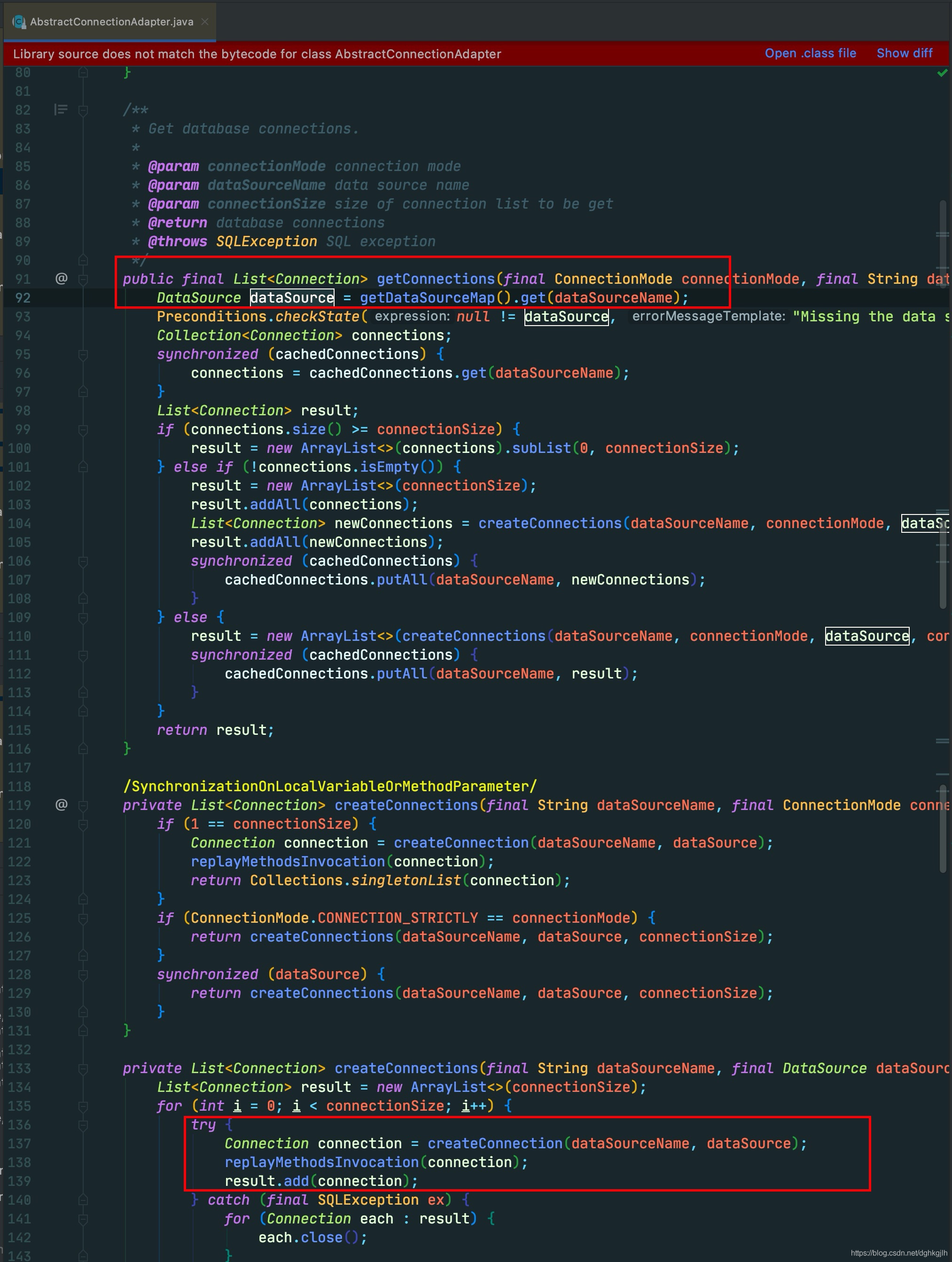
Mybatis插入的核心操作在SimpleExector.doUpdate方法中,这个方法里要获取Connection、Statement、设置参数。prepareStatement方法中this.getConnectoin().里面会调用openConnection()方法,最终会调用当前DataSource.getConnection方法。也就是调用ShardingDataSource.getConnection.返回一个ShardingConnection.
为什么要返回一个自定义的Connection呢?后面会说。
拿到connection之后,还要获得Statement,调用handler.prepare方法,最终会调用instantiateStatement方法中通过connection.prepareStatement方法获得。这里调用ShardingConnection.prepareStatement方法返回一个ShardingPreparedStatement.
为什么要返回一个自定义的PreparedStatement呢?
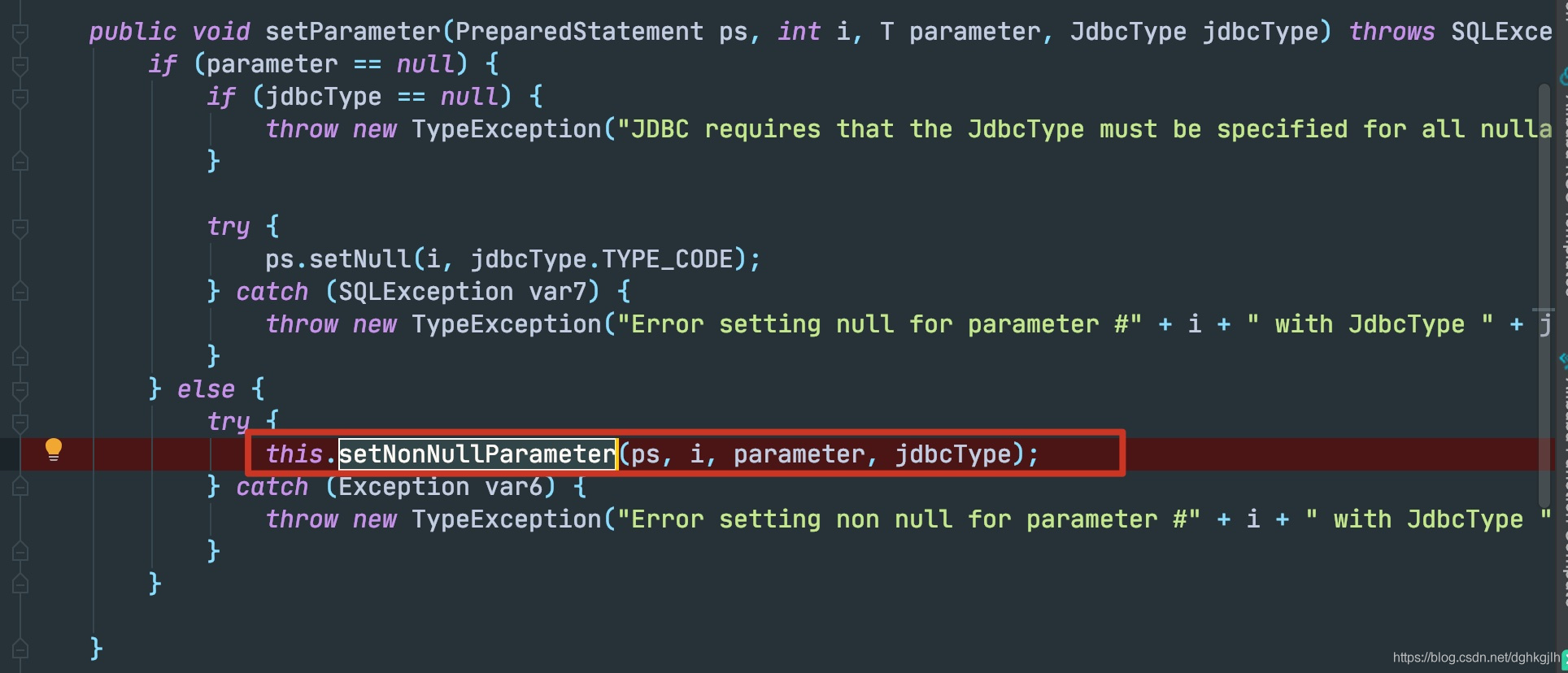
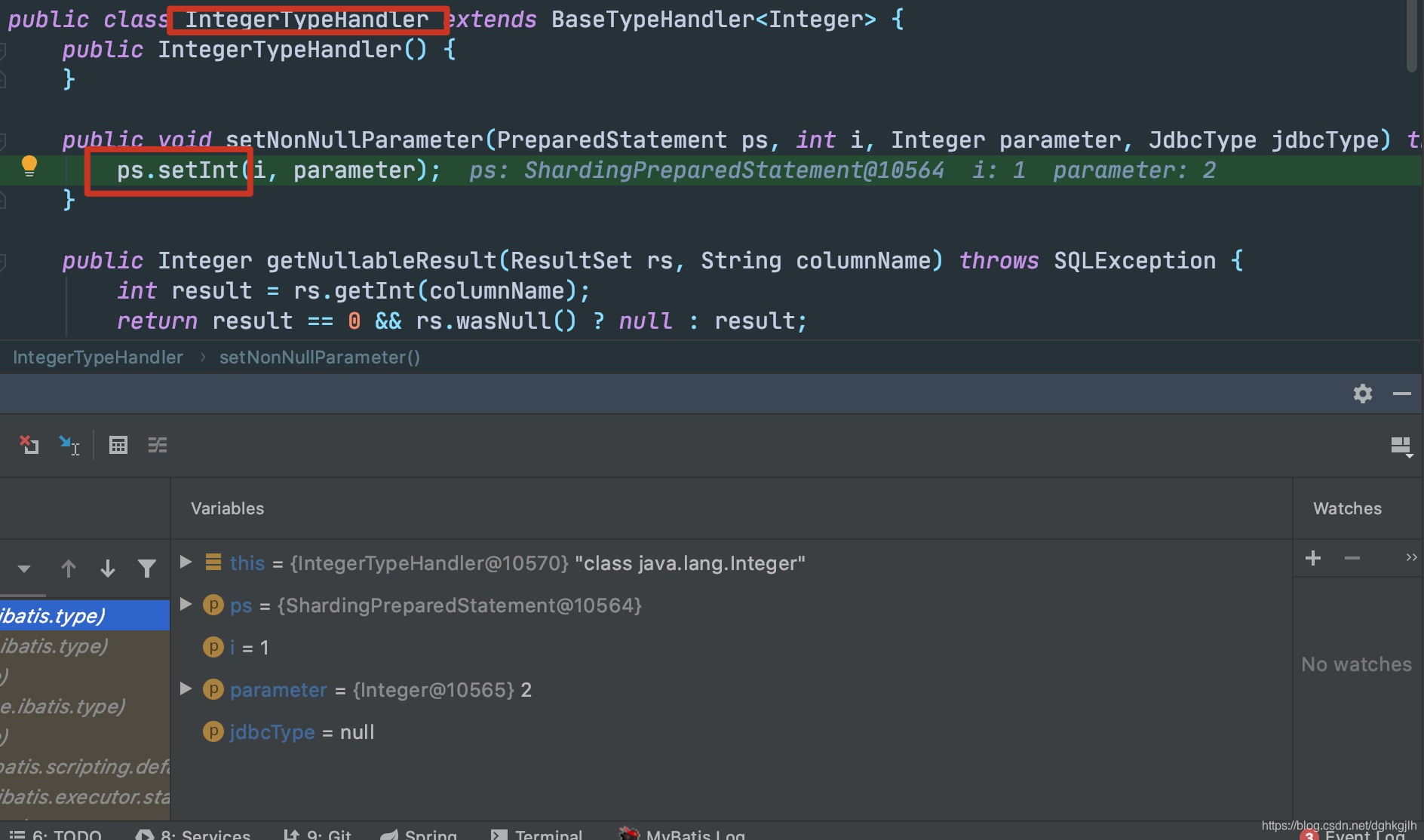
拿到Statement之后,自然就是为SQL的参数赋值。调用handler.parameterize方法,接着会调用DefaultParameterHandler.setParameters方法,为不同的参数类型,选择不同的TypeHandler,最后会调用BaseTypeHandler.setParameter().setNonNullParameter方法,根据不同的TypeHandler执行PreparedStatement.setInt或者setString或者其他setXXX方法.
调用前面返回的SharingPreparedStatement.setInt()方法
正常的PreparedStatement接口的实现类,例如MySQL的ClientPreparedStatement的setInt会进行设置参数和值的绑定,但是这里ShardingPreparedStatement却没有
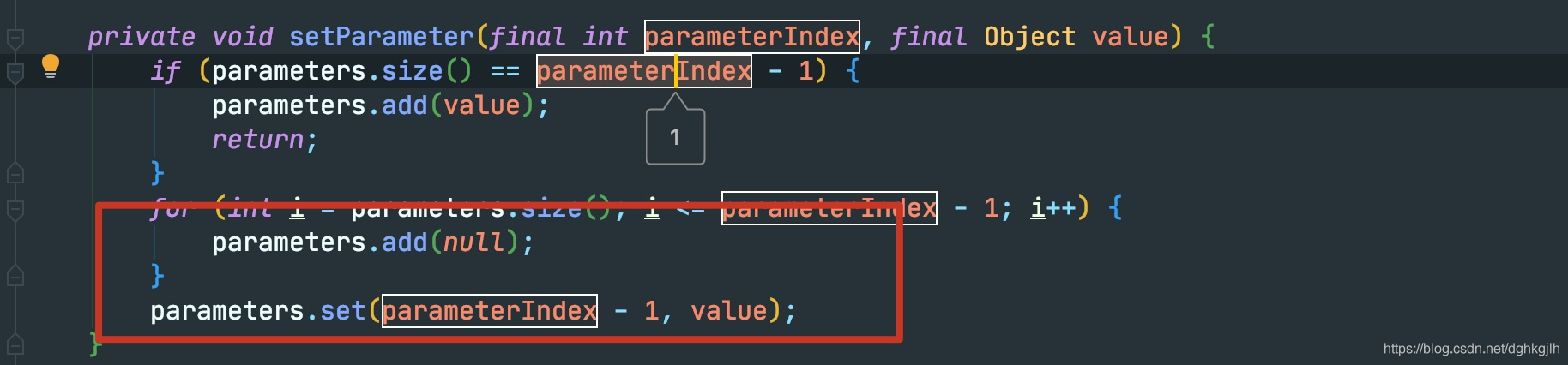
这里仅仅是将其放到了一个List中。其他setString、setXXX也一样。就返回了。
值得注意的是,到完成这一步,在Mybatis的角度来看,已经拿到了connection、statement、为SQL设置好了值。接下来就是最后一步,执行SQL就行了。但是,这里拿到的只不过是ShardingJDBC自定义的几个类的对象。连真正拿到connection的地方都还看到。
-
开始进行执行SQL
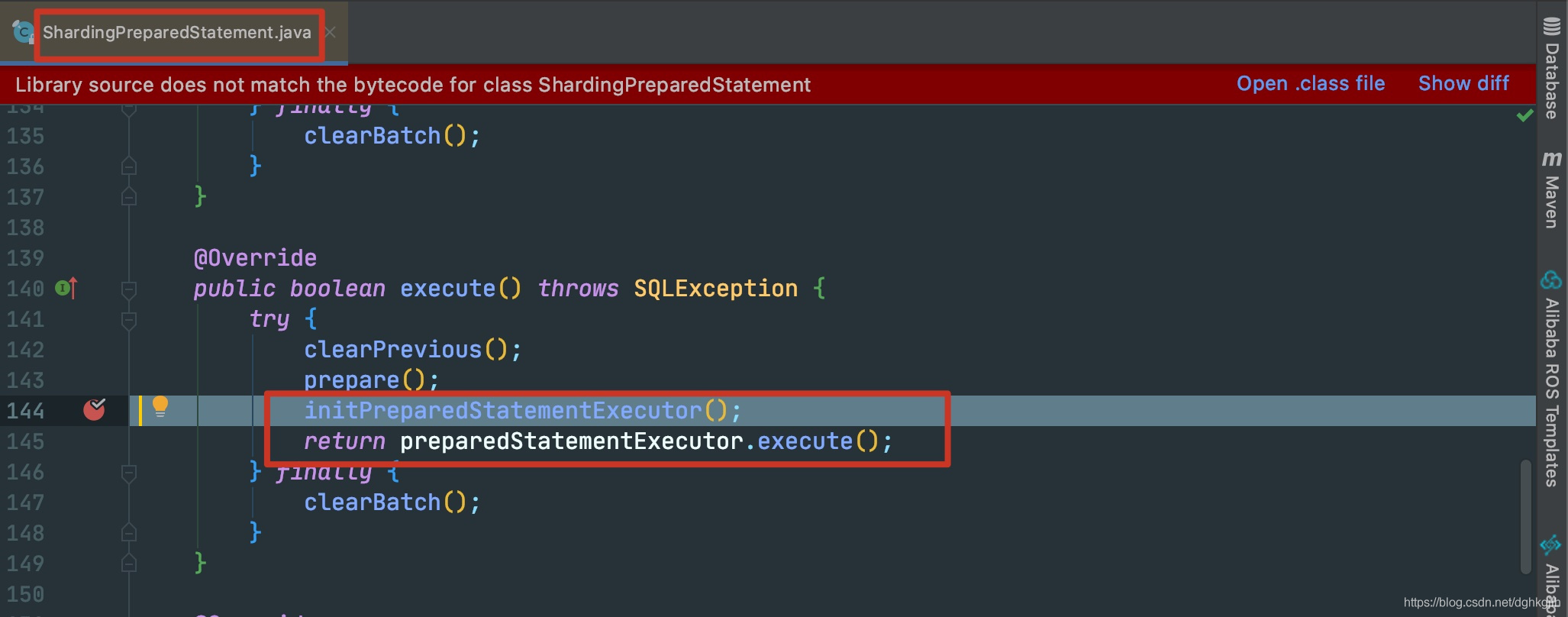
Mybatis认为一切准备就绪,最终会执行ps.execute()方法。这行代码的最终执行依旧还是ShardingPreparedStatement的execute方法。因为前面拿到的就是它。
prepare方法进行的是根据分片、主从、影子的规则进行SQL改写。也就是核心的功能。这里不做讨论。
进入144行方法
有三个子方法
preparedStatementExecutor.init(executionContext); setParametersForStatements(); replayMethodForStatements();第一个方法:
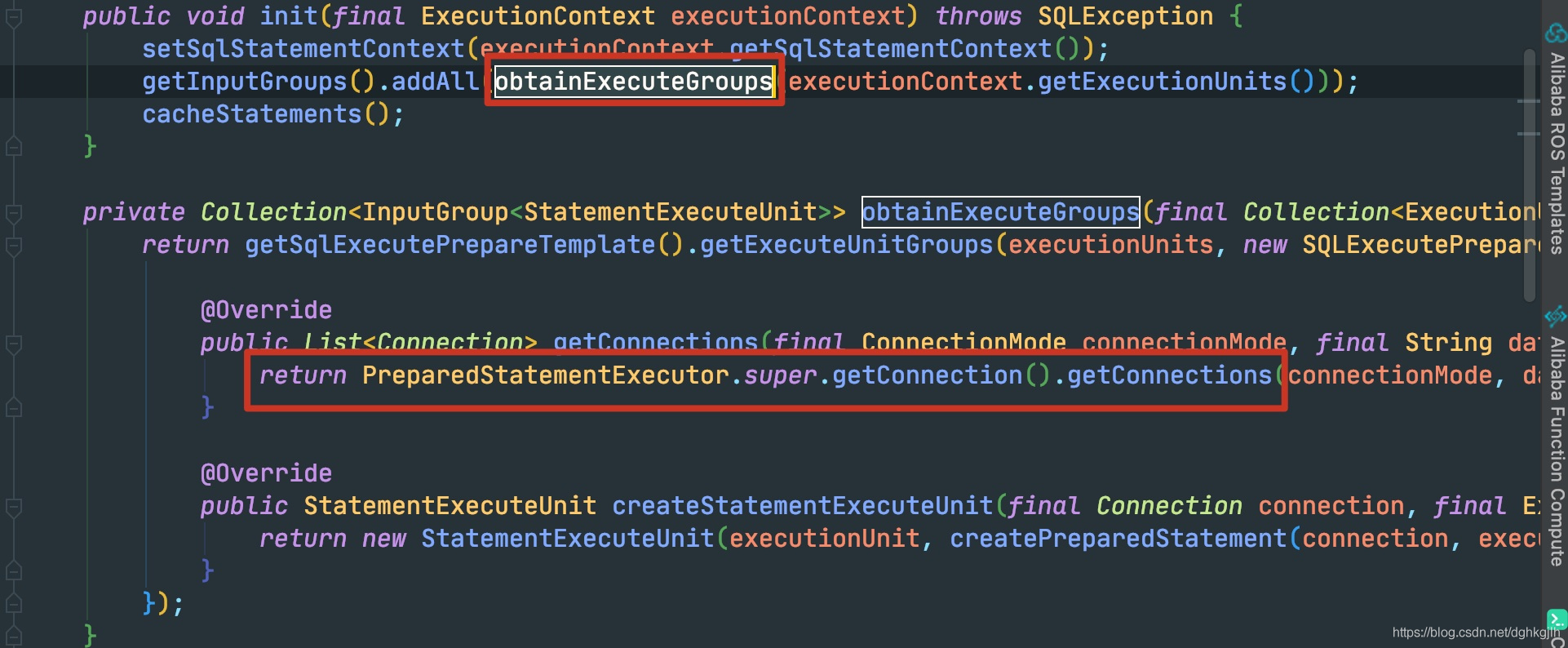
此时才是真正去拿connection的地方
可以看到,这里根据具体的配置文件里的datasource名字,去刚才启动时候的map里去找对应的已经实例好的DataSource.最后会根据dataSource.getConnection方法获得真正的connection.获得connection之后,还会执行上面截图的createdPreparedStatement方法去获取真正的Statement。==也就是调用真正connection的connection.prepareStatement==
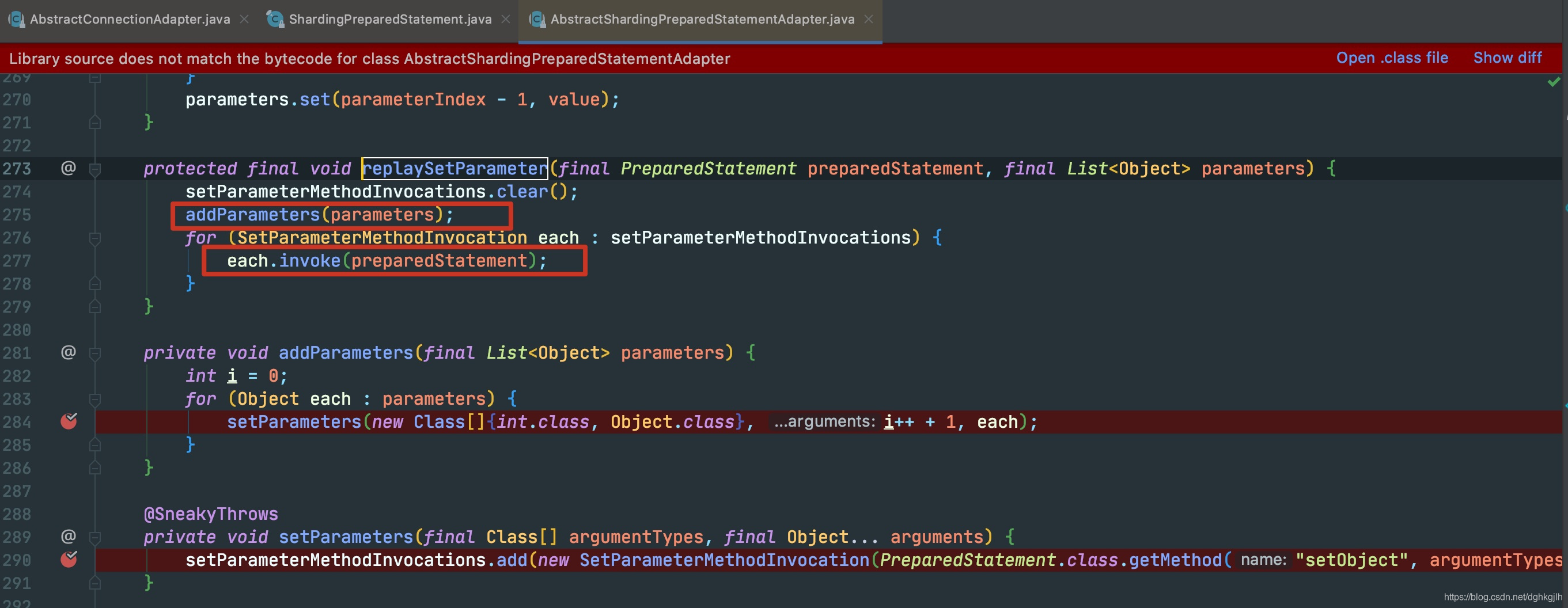
第二个子方法:获得connection、statement之后。进入setParametersForStatements方法
通过反射调用PreparedStatement.setObject方法,对参数设置,这里的循环的是刚才Mybatis设置参数时所放进去的list。 -
最终执行SQL
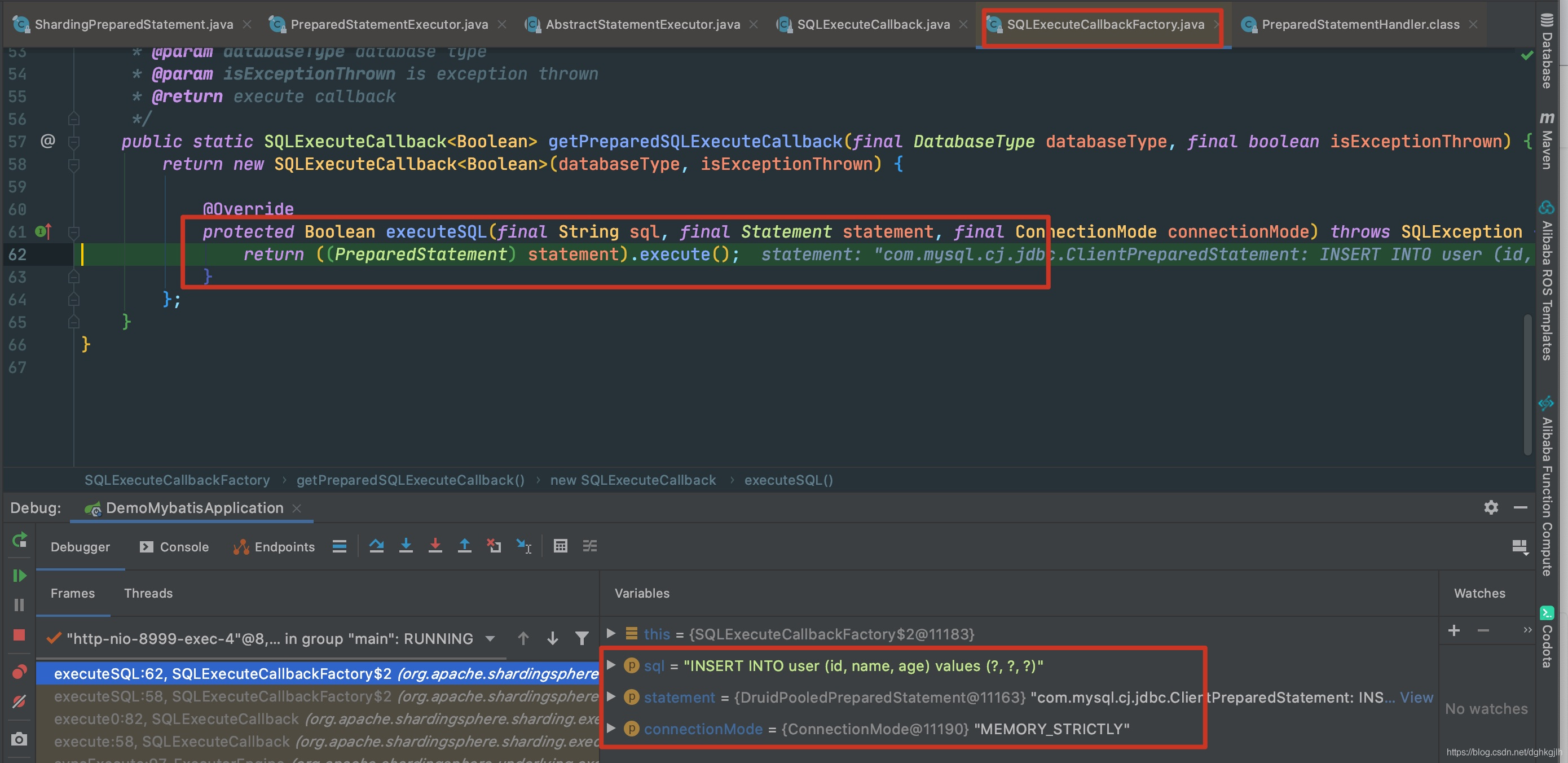
准备完毕之后,即路由、改写SQL之后,获取连接、statement、参数赋值之后,终于执行了preparedStatementExecutor.execute()方法,最终会执行org.apache.shardingsphere.sharding.execute.sql.execute.SQLExecuteCallback#executeSQL方法
这里拿到的不再是ShardingConnection或者ShardingPreparedStatement而是真正数据源的connection、statement。进行执行
-
结果集的处理
Mybatis的核心ps.execute执行完毕之后,会对结果集进行处理。
==注意== :此时的ps是ShardingPreparedStatement,因为具体的PreparedStatement是在上一步ps.execute里面才拿到的。
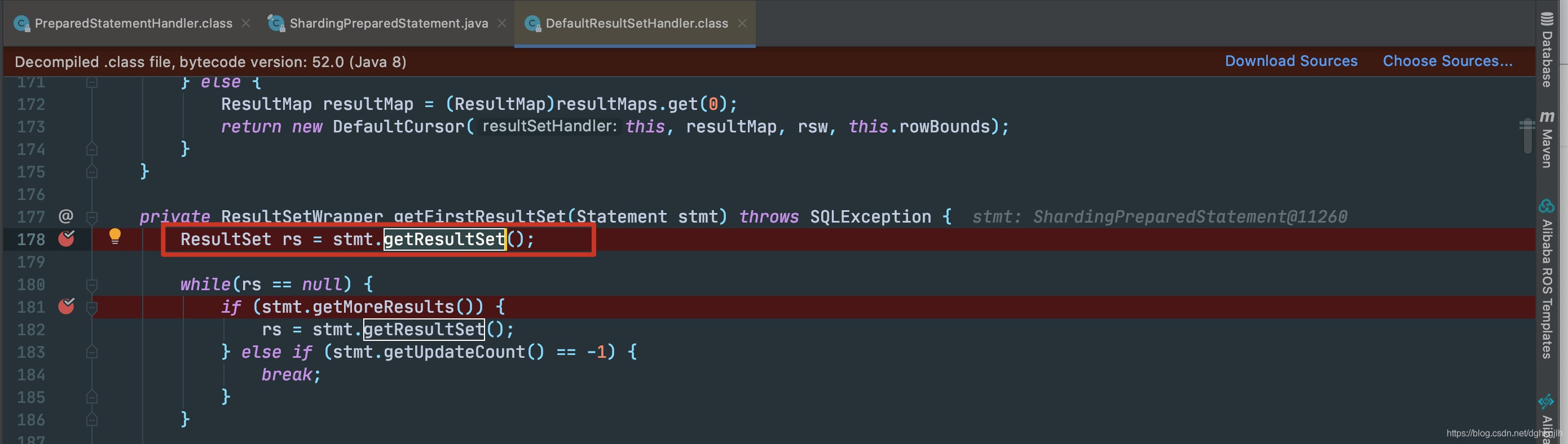
最终会在DefaultResultSetHandler里进行获取resultSet
调用ShardingPreparedStatement的具体getResultSet方法
这里的each是真正的PreparedStatement。直接调用getResultSet即可获得结果集。获得结果集之后,ShardingJdb会对结果集进行合并,也是核心功能。这里不做讨论

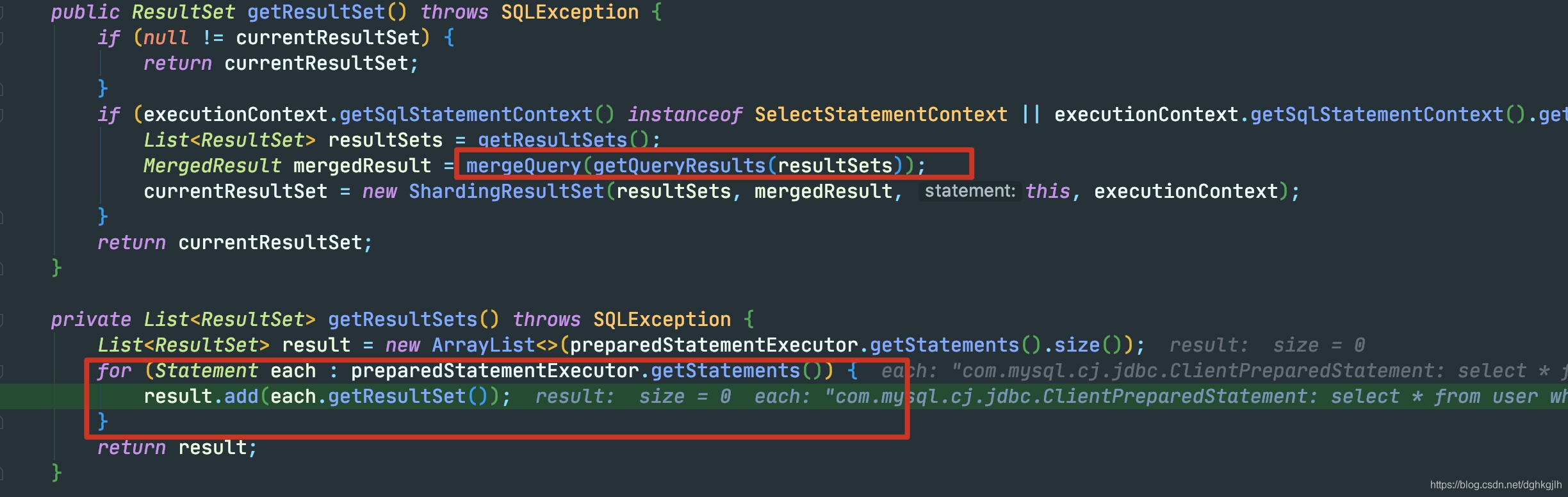
到此为止,ShardingJDBC的工作流程解析完毕,再看前面几个问题,为什么要自定义datasource(最上面说的逻辑数据源)、connection、statement、result?
为了和各种ORM框架的进行==兼容==(正因为有了这些自定义的类,Mybatis的正常流程才不受阻碍),同时不开发重复功能,只专注于核心功能的实现。ShardingJDBC将JDBC的核心步骤全部下沉到最底层的execute方法中。在底层execute方法执行之前,借助于自定义的类,完成自身核心功能(分片、主从、加解密、影子)的实现。对于其他框架来说,ShardingJDBC的这些类就是”可用的“,可以说,这些自定义的类在充当傀儡的同时(让其他框架以为自己拿到的就是真的),还实现了自身核心功能。
模拟ShardingJdbc执行过程
走完上面的流程,简单自定义模拟一下上述过程
自定义DataSource-MyDataSource
自定义Connection-Myconnection
自定义PreparedStatement-MyPreparedStatement
容器启动时,创建自定义MyDataSource
public class DataSourceConfiguration implements EnvironmentAware {
private Environment environment;
@Override
public void setEnvironment(final Environment environment) {
this.environment = environment;
}
@Bean
@SneakyThrows
public DataSource createDataSource() {
Map<String, Object> property = getDataSourcePropertyByPrefix("spring.datasource");
Preconditions.checkState(CollectionUtil.isNotEmpty(property));
Map<String, DataSource> dataSourceMap = new HashMap<>(1);
DataSource dataSource = (DataSource) Class.forName(property.get("type").toString()).newInstance();
property.remove("type");
Iterator<Entry<String, Object>> iterator = property.entrySet().iterator();
while (iterator.hasNext()) {
Entry<String, Object> entry = iterator.next();
// 通过反射调用各个属性的set方法,设置必要属性
callSetterMethod(dataSource, getSetterMethodName(entry.getKey()), entry.getValue().toString());
}
// 将dataSource设置进去
dataSourceMap.put("master", dataSource);
return new MyDataSource(dataSourceMap);
}
@SneakyThrows
private void callSetterMethod(final DataSource dataSource, final String setterMethodName, final String value) {
Method method = dataSource.getClass().getMethod(setterMethodName, String.class);
method.invoke(dataSource, value);
}
private String getSetterMethodName(final String key) {
return key.contains("-") ? CaseFormat.LOWER_HYPHEN.to(CaseFormat.LOWER_CAMEL, "set-" + key) : "set" + String.valueOf(key.charAt(0)).toUpperCase() + key.substring(1);
}
private Map getDataSourcePropertyByPrefix(String prefix) {
// 利用Binder获取配置文件的信息
Binder binder = Binder.get(environment);
BindResult<Map> bind = binder.bind(prefix, Bindable.of(Map.class));
return bind.get();
}
}
DataSource.getConnection()方法,返回自定义MyConnection
public class MyDataSource implements DataSource {
/**
* 自定义dataSourceMap,里面放置了各种DataSource,如Druid,C3P0.
*/
private final Map<String, DataSource> dataSourceMap;
public MyDataSource(final Map<String, DataSource> dataSourceMap) {
this.dataSourceMap = dataSourceMap;
}
/**
* 获取连接,仅仅返回一个MyConnection对象.
*/
@Override
public Connection getConnection() throws SQLException {
return new MyConnection(dataSourceMap);
}
}
MyConnection.prepareStatement返回自定义MyPreparedStatement
@Getter
public class MyConnection implements Connection {
private final Map<String, DataSource> dataSourceMap;
public MyConnection(final Map<String, DataSource> dataSourceMap) {
this.dataSourceMap = dataSourceMap;
}
@Override
public Statement createStatement() throws SQLException {
return null;
}
@Override
public PreparedStatement prepareStatement(final String sql) throws SQLException {
return new MyPreparedStatement(this, sql);
}
}
在自定义的MyPreparedStatement方法中真正执行JDBC核心流程
@Getter
public class MyPreparedStatement implements PreparedStatement {
private final MyConnection myConnection;
private final String sql;
private ResultSet resultSet;
private final List<Object> parameters = new ArrayList<>();
public MyPreparedStatement(final MyConnection myConnection, final String sql) {
this.myConnection = myConnection;
this.sql = sql;
}
// ....省略部分方法
@Override
public void setInt(final int parameterIndex, final int x) throws SQLException {
// Mybatis TypeHandler处理的时候,现将参数存放在list中
// list必须有值,才可以调用set方法
parameters.add(null);
parameters.set(parameterIndex - 1, x);
}
/**
* 真正执行获取Connection-连接、获取PreparedStatement并且执行的地方.
*/
@Override
public boolean execute() throws SQLException {
// 获取具体数据源
DataSource dataSource = this.myConnection.getDataSourceMap().get("master");
// 获取具体数据源的connection
Connection connection = dataSource.getConnection();
// 真正获取preparedStatement的地方
PreparedStatement preparedStatement = connection.prepareStatement(this.sql);
// 通过反射 调用 设置属性值
final AtomicInteger loop = new AtomicInteger(0);
parameters.forEach(item -> {
Method method = null;
try {
// 第一种方式: 直接通过preparedStatement.setObject 设置参数值
preparedStatement.setObject(loop.get()+1, item);
// 第二种方式: 通过反射调用,也是调用preparedStatement.setObject
// method = PreparedStatement.class.getMethod("setObject", int.class, Object.class);
//method.invoke(preparedStatement, loop.get()+1, item);
// NoSuchMethodException | IllegalAccessException | InvocationTargetException |
} catch ( SQLException e) {
e.printStackTrace();
}
loop.getAndIncrement();
});
preparedStatement.execute();
ResultSet statementResultSet = preparedStatement.getResultSet();
this.resultSet = statementResultSet;
// 不关闭资源,还有handler要拿下面的资源进行结果集的处理
//statementResultSet.close();
// preparedStatement.close();
//connection.close();
return true;
}
@Override
public ResultSet getResultSet() throws SQLException {
return this.resultSet;
}
}
以上流程基本模拟了ShardingJDBC所完成的整体的流程。全部实现JDBC的DataSource、Connection、Statement接口的方法。还少一个资源的关闭,没有添加例子
备注
- 以上所有示例代码,均已放到GitHub上,如有需要自取
- 以上涉及到Mybatis的执行流程的细节,没有特别细致的分析,可参考相关Mybatis分析相关博客
状态:原创(CSDN博主
JackSparrow414)