
数据库中间件ShardingSphere-ShardingProxy使用(一)数据分片、读写分离
数据库中间件ShardingSphere-ShardingProxy使用(一)数据分片、读写分离
背景
在数据库中间件ShardingSphere-ShardingJdbc使用(一)数据分片中介绍了数据库中间件的两种代理方式,客户端代理(即数据源代理),服务端代理(代理数据库实例)。
而ShardingJdbc属于数据源代理,目前只有Java语言可用。实际情况中,一个庞大的系统架构,不可能只使用一种语言,Java、C、C++、php、Python等等,都可能会访问数据库,如果对应的数据库都存在分库、分表的情况。如何让其他语言的业务开发同学也享受到不用关心底层分库分表的逻辑就可以开发的福利呢?ShardingProxy的就出现了。
ShardingProxy也就是逻辑上的数据库实例,它背后管理着N个真实的实例
下载/配置
在ShardnigSphere官网中,可以下载对应的ShardingProxy版本。下载对应的tar.gz文件
-
解压
tar -xvf apache-shardingsphere-4.1.1-sharding-proxy-bin.tar.gz -
修改config-配置,进入conf文件下,选择conf-sharding.yaml文件
-
配置数据分片
schemaName: sharding_db dataSources: # 主库1 ds0: url: jdbc:mysql://localhost:3306/dhb?serverTimezone=UTC password: 12345 username: root # 主库1的从库1 ds0-slave0: url: jdbc:mysql://localhost:3307/dhb?serverTimezone=UTC password: 12345 username: root # 主库1的从库2 ds0-slave1: url: jdbc:mysql://localhost:3308/dhb?serverTimezone=UTC password: 12345 username: root # 主库2 ds1: url: jdbc:mysql://localhost:3310/dhb?serverTimezone=UTC password: 12345 username: root # 数据分片配置 shardingRule: # 默认分库策略 defaultDatabaseStrategy: inline: shardingColumn: id algorithmExpression: ds$->{id % 2} # 默认分表策略 defaultTableStrategy: inline: shardingColumn: age algorithmExpression: user_$->{age % 2} # 数据节点 tables: user: actualDataNodes: ds$->{0..1}.user_$->{0..1} # 默认数据库 defaultDataSourceName: ds0 -
配置读写分离
注意:ShardingProxy每一个config-的文件都是一个数据源,所以这里我们只使用一个数据源,在这个数据源中完成数据分片、读写分离等。官方默认带了4个config-配置文件。可根据需要,自行使用。
同时注意:在一个配置文件里,masterSlaveRules要放在shardingRule的下一级。
# 读写分离配置---start masterSlaveRules: ds0: masterDataSourceName: ds0 slaveDataSourceNames: - ds0-slave0 - ds0-slave1 #从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。 #若`load-balance-algorithm-class-name`存在则忽略该配置 loadBalanceAlgorithmType: ROUND_ROBIN #从库负载均衡算法类名称。该类需实现MasterSlaveLoadBalanceAlgorithm接口且提供无参数构造器 #load-balance-algorithm-class-name= # 读写分离配置---end
-
-
修改server配置文件,authentication相当于为逻辑上的数据库实例设置用户、密码。可配置多个。将SQL打印放开,以便稍后验证配置是否正确
authentication: users: root: password: 123456 sharding: password: 123456 authorizedSchemas: sharding_db props: sql.show: true -
进入bin文件夹下启动,使用13306启动proxy
start.sh 13306 -
进入log文件夹下查看有无报错
-
使用Navicat新建连接13306。此时ShardingProxy帮我们管理4个真实的MySQL实例,分别为主库1-3306,主库2-3310,主库1的从库1-3307,主库1的从库2-3308.
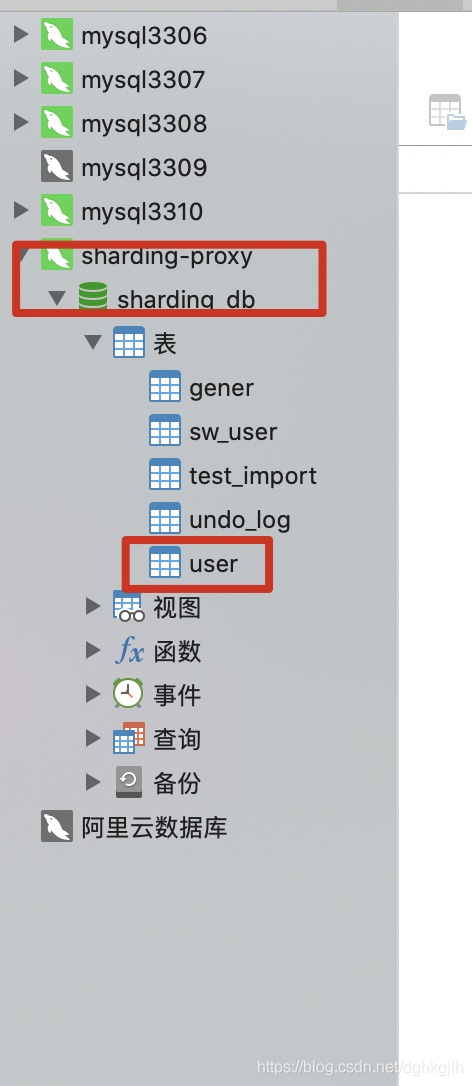
连接成功之后查看,数据库,数据表
可以看到,这里所有的user_N的表都展示位一张user表了。
代码中使用
以上配置好了以后,在实际代码中,不再去连接物理的MySQL实例,而是连接此时启动的逻辑上的MySQL实例,proxy 13306。
此时在程序中配置数据源,这里连接的是逻辑的数据库实例
spring:
application:
name: mybatis-demo
datasource:
url: jdbc:mysql://localhost:13306/sharding_db?serverTimezone=UTC
username: sharding
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
-
验证ShardingProxy配置是否成功
-
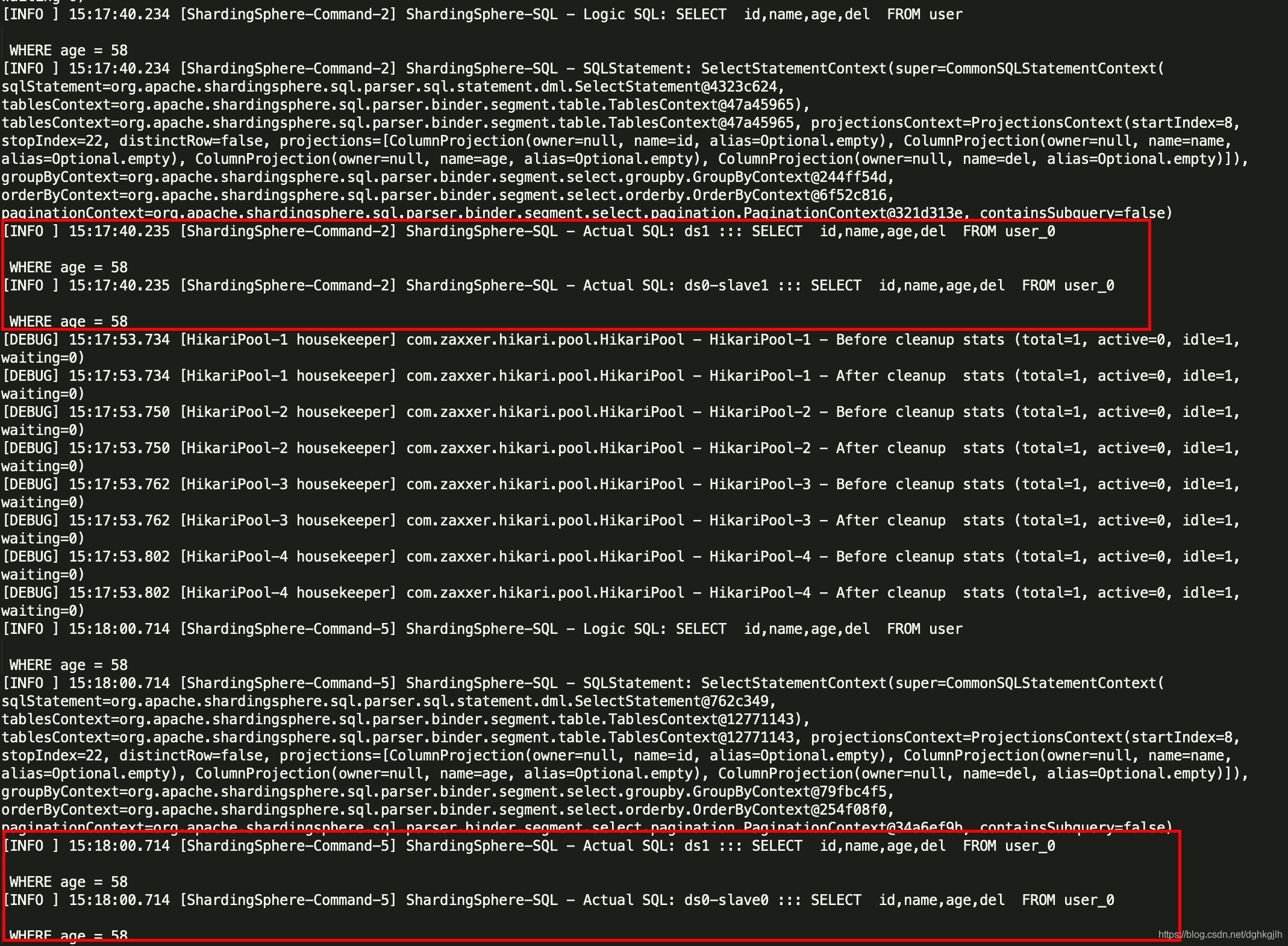
查询数据,正常情况会在3307、3308之间进行轮询查询,因为配置了读写分离
根据日志,查看确实是在两个从库之间轮询查询。 -
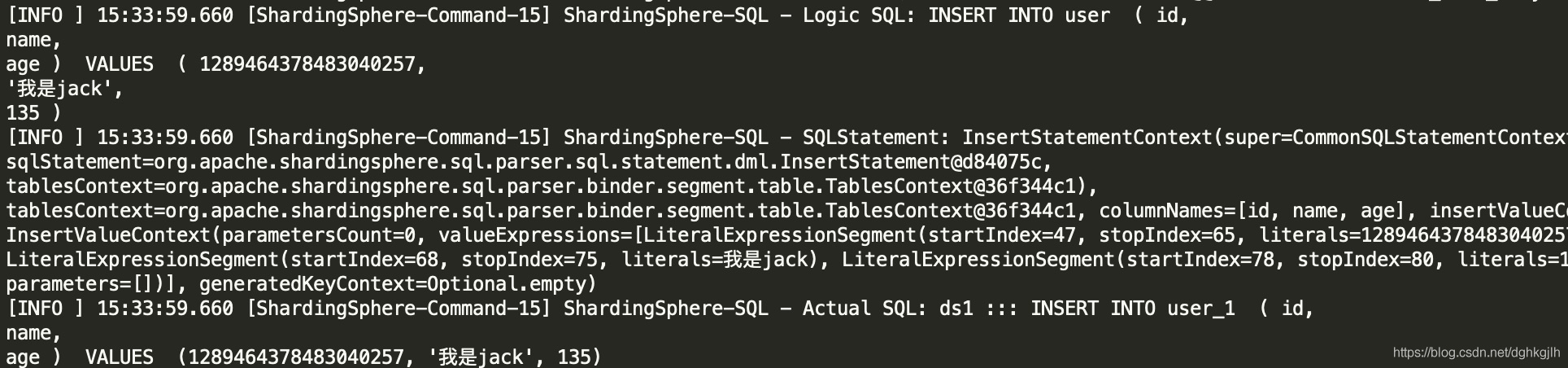
插入数据
-
- 根据id对2求余,定位到主库2上,根据age对库求余,定位到user_1表上
-
-
注意事项
-
如果程序中使用的mysql-connector连接是MySQL8.0的,那么也要讲ShardingProxy下的lib文件夹中加入mysql-connector8.0的jar包
-
如果加入了上述jar包之后还是存在问题,那么检查proxy的版本是多少,4.0.0的话肯定是不行的,目前,社区在4.1.1中已经修复了这个bug,可升级到4.1.1。下载地址,相关issue,相关PR.
发布截图如下

总结
- ShardingProxy不仅支持了多种语言,而且对于程序配置而言,仅仅配置一个逻辑上的数据库实例即可
- 对于DBA来说,减轻了不少压力,不会再根据分库分表规则,算完了之后再去查数据了
- 欢迎大家多多参与ShardingSphere的社区建设,与社区一起成长。
状态:原创(CSDN博主
JackSparrow414)