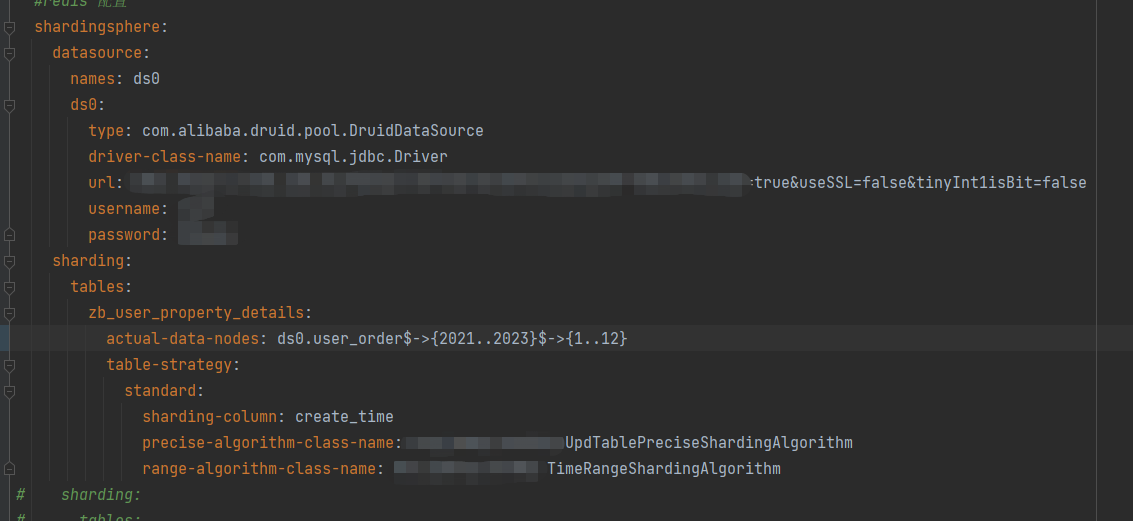
@adam 你好,我使用类似的配置试了下分组聚合,没有复现你反馈的问题。
配置:
shardingRule:
tables:
t_order:
# actualDataNodes: ds_${0..1}.t_order_${0..1}
actualDataNodes: ds_0.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_item_id
bindingTables:
- t_order,t_order_item
defaultDatabaseStrategy:
none:
defaultTableStrategy:
none:
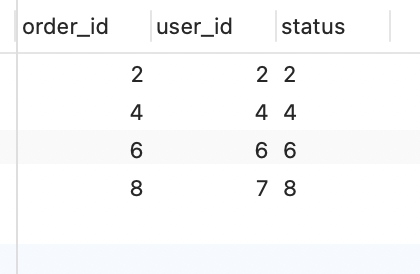
分组聚合结果如下:
mysql> select * from t_order where order_id in (2, 4, 6, 7, 8, 9);
+----------+---------+---------+---------------+-------------+-------------+
| order_id | user_id | content | business_data | create_time | order_money |
+----------+---------+---------+---------------+-------------+-------------+
| 2 | 2 | 22 | NULL | 2021-11-01 | 1 |
| 4 | 4 | 44 | NULL | 2021-11-02 | 3 |
| 6 | 6 | 6666 | NULL | NULL | 17 |
| 8 | 8 | 88888 | NULL | NULL | 11 |
| 7 | 6 | 77777 | NULL | NULL | 13 |
| 9 | 8 | 88888 | NULL | NULL | 7 |
+----------+---------+---------+---------------+-------------+-------------+
6 rows in set (0.01 sec)
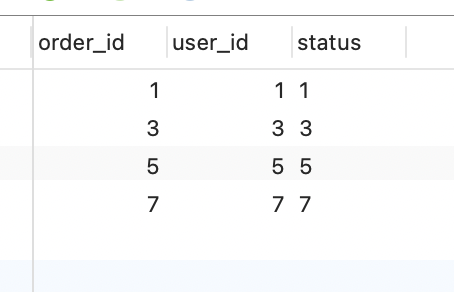
mysql> select user_id, sum(order_money) orderMoeny from t_order where order_id in (2, 4, 6, 7, 8, 9) group by user_id order by orderMoeny ;
+---------+------------+
| user_id | orderMoeny |
+---------+------------+
| 2 | 1 |
| 4 | 3 |
| 8 | 18 |
| 6 | 30 |
+---------+------------+
4 rows in set (0.01 sec)
路由结果如下:
[INFO ] 11:50:18.955 [pool-2-thread-1] ShardingSphere-SQL - Actual SQL: ds_0 ::: select user_id, sum(order_money) orderMoeny from t_order_0 where order_id in (2, 4, 6, 7, 8, 9) group by user_id order by orderMoeny
[INFO ] 11:50:18.955 [pool-2-thread-1] ShardingSphere-SQL - Actual SQL: ds_0 ::: select user_id, sum(order_money) orderMoeny from t_order_1 where order_id in (2, 4, 6, 7, 8, 9) group by user_id order by orderMoeny
如果方便的话,可否提供一个能够复现问题的 demo?