
在《DistSQL:像数据库一样使用 Apache ShardingSphere》一文中,Committer 孟浩然为大家介绍了 DistSQL 的设计初衷和语法体系,并通过实战操作展示了一条 SQL 创建分布式数据库表的强大能力,展现了 Apache ShardingSphere 在新形态下的交互体验。
在前文发布后,小助手陆续收到热心读者的私信,询问使用 DistSQL 配置分片规则的细节,以及使用 YAML、Namespace 等形式的配置时,是否可以像 DistSQL 一样快速方便的完成分布式表的配置和创建?本文将为大家解答这些疑问。
作者|江龙滔
SphereEx 中间件研发工程师,Apache ShardingSphere contributor。目前专注于 ShardingSphere 数据库中间件研发及开源社区建设。
背景
Sharding 是 Apache ShardingSphere 的核心特性,也是 ShardingSphere 最被人们熟知的一项能力。在过去,用户若需要进行分库分表,一种典型的实施流程(不含数据迁移)如下:

图1 Sharding 实施流程示意图
在这一过程中,用户需要准确的理解每一张数据表的分片策略、明确的知晓每张表的实际表名和所在数据库,并根据这些信息来配置分片规则。
以上述分库分表场景为例,实际的数据表分布情况可能如下:
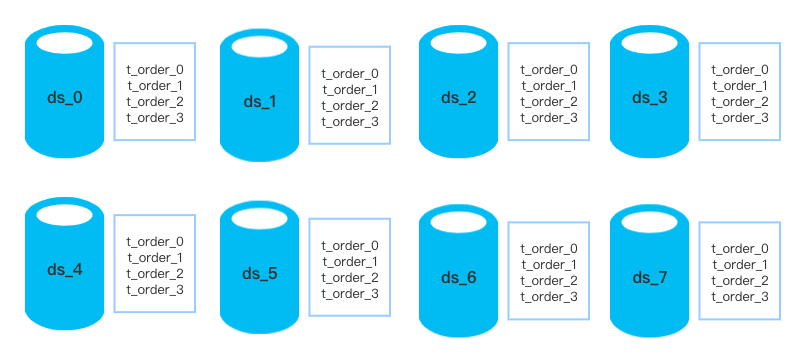
图28 库 * 4 表分布示意图
痛点
在前述的分库分表场景中,作为 Sharding 功能的用户,必须要对数据表的分布情况了然于心,才能写出正确的 actualDataNodes 规则。如上述 t_order 表对应的分片配置如下:
tables:
t_order:
actualDataNodes: ds_${0..7}.t_order_${0..3}
databaseStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: database_inline
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_inline
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${order_id % 8}
table_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 4}
尽管 ShardingSphere 的配置规则已经非常的规范和简洁,但仍有用户在使用中遇到各种麻烦:
-
不理解分片策略或配置规则,无从下手
-
分片配置与数据表实际分布不匹配
-
配置表达式格式不正确
-
等等
如这位用户提出的 issue:

AutoTable 横空出世
为了帮助用户更好的使用分片功能,降低配置复杂度和提升使用体验,Apache ShardingSphere 5.0.0 版本推出了一种新的分片配置方式:AutoTable。
顾名思义,AutoTable 类型的数据表,交由 ShardingSphere 自动管理分片,用户只需要指定分片数量和使用的数据源,无需再关心表的具体分布,配置格式如下:
autoTables:
t_order:
# 指定使用的数据源
actualDataSources: ds_${0..7}
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: mod
shardingAlgorithms:
mod:
type: MOD
props:
# 指定分片数量
sharding-count: 32
通过以上配置,ShardingSphere 识别出逻辑表 t_order 需要分为 32 片且使用 8 个数据源,则自动计算出 8 库 * 4 表的分布关系,实现和传统方式等效的配置结果。
与 DistSQL 结合
通过前一节的配置对比,相信读者已经感受到了 AutoTable 带来的变革。不过,随着 DistSQL 的公开,ShardingSphere 还能带给我们更多。
在使用 DistSQL 进行数据管理的场景下,AutoTable 能够极大的降低分片配置复杂度。并且,与传统文件配置形式相比,通过 DistSQL 来配置分片规则是即时生效的,无需重启,这样也就完全不用担心单张表的规则调整影响其他在线业务。
除了新增分片配置,DistSQL 也提供了修改和删除分片规则的语法,格式如下:
# 新增分片规则
CREATE SHARDING TABLE RULE t_order (
RESOURCES(resource_0,resource_1),
SHARDING_COLUMN=order_id,TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=4))
);
# 修改分片规则
ALTER SHARDING TABLE RULE t_order (
RESOURCES(resource_0,resource_1),
SHARDING_COLUMN=order_id,TYPE(NAME=hash_mod,PROPERTIES("sharding-count"=10))
);
# 移除分片规则
DROP SHARDING TABLE RULE t_order;
*注:若规则修改影响到存量数据,ShardingSphere 还将提供“弹性扩缩容”的功能用作数据迁移,帮助用户方便快捷的管理分布式数据。有关“弹性扩缩容”的具体细节,请关注后续推送。
FAQ
Q1: ShardingSphere-JDBC 中可以使用 AutoTable 分片配置吗?
可以。AutoTable 分片配置方式适用于 ShardingSphere-JDBC 和 ShardingSphere-Proxy,在 Proxy 中更可以通过 DistSQL 进行动态配置,满足各种接入方式的需要。
Q2: AutoTable 支持哪些分片算法?
AutoTable 支持全部的自动分片算法,包括:
-
MOD:取模分片算法
-
HASH_MOD:哈希取模分片算法
-
VOLUME_RANGE:基于分片容量的范围分片算法
-
BOUNDARY_RANGE:基于分片边界的范围分片算法
-
AUTO_INTERVAL:自动时间段分片算法
关于以上算法的更多详细信息,请阅读 Apache ShardingSphere 官方文档-自动分片算法:
除内置算法外,用户也可以通过 SPI 扩展的方式加载自定义的分片算法,满足更加定制化的分片需求。
Q3: 业务已经使用了 YAML 配置分片规则,可以转换为 AutoTable 配置形式吗?
不推荐。如果是已经存在分片规则的数据表,除非能确定切换为 AutoTable 配置后,表分布状态与预期完全一致,否则不建议尝试切换已有配置。
不过若是在原有应用的基础上新增数据表,那么新增的表是可以使用 AutoTable 配置的。
Q4: AutoTable 的推荐使用场景?
无论是在 ShardingSphere-JDBC 还是 ShardingSphere-Proxy 中,AutoTable 都希望为用户带来「管家式」的分片配置体验。即用户只告诉 ShardingSphere 分片数量,不需要关心实际表在哪个库、哪个库有几张表等问题。
因此,若要使用 AutoTable 配置,推荐用户忘却「先建表、再配规则」的传统思维,改为先配置规则再通过 CREATE TABLE 语句创建数据表。把 ShardingSphere 看作分布式数据库的接入点,而不是中间件。
Q5: 数据源名称不是连续的,或数量太多,可以使用 AutoTable 吗?
可以。指定数据源时并不要求名称连续,可以同时使用枚举和 INLINE 表达式,如以下形式:
CREATE SHARDING TABLE RULE t_order (
RESOURCES('resource_${0..9}',resource_12,resource_15,"resource_$->{17..19}"),
...
);
Q6: AutoTable 配置和传统的分片配置可以混合使用吗?
可以。请参考完整的配置样例:
结语
以上就是本次分享的全部内容,如果读者对 Apache ShardingSphere 有任何疑问或建议,欢迎在 GitHub issue 列表提出,也可提交 Pull Request 参与到开源社区,为社区贡献力量。
GitHub issue: