
以下文章来源于携程技术,作者瑞华
作者简介
瑞华,携程高级后端开发工程师,关注系统架构、分库分表、微服务、高可用等。
一、前言
随着国际火车票业务的高速发展,订单量快速增长,单数据库瓶颈层面的问题逐渐显露,常规的数据库优化已无法达到期望的效果。同时,原先的底层数据库设计,也存在一些历史遗留问题,比如存在部分无用字段、表通过自增主键关联和各个应用直连数据库等问题。
为此,经过讨论后,我们决定对订单库进行分库分表,同时对订单表进行重构,进而从根本上解决这些问题。
二、问题挑战
目标确定后,实践起来可不轻松,出现了很多的问题和挑战。这里列举一些典型问题,大致可以分为两大类:分库分表通用问题、具体业务关联问题。
分库分表通用问题
-
如何切分,垂直分还是水平分?分片的键,如何选取?
-
如何根据键值路由到对应库、对应表?
-
采用什么中间件,代理方式还是中间件的方式?
-
跨库操作等问题,如跨库事务和跨库关联?
-
数据扩容问题,后续如何进行扩容?
具体业务关联问题
-
各个应用直连数据如何解决?
-
如何进行平滑过渡?
-
历史数据如何恰当迁移?
三、方案选型
3.1 如何切分
切分方式,一般分为垂直分库、垂直分表、水平分库和水平分表四种,如何选择,一般是根据自己的业务需求决定。
我们的目标是要从根本上解决数据量大、单机性能问题等问题,垂直方式并不能满足需求,所以我们选取了水平分库+水平分表的切分方式。
3.2 分片键选取
一般是根据自己的实际业务,来选择字段来作为分片的键,同时可以结合考虑数据的热点问题 、分布问题。比如订单系统,不能根据国家字段进行分片,否则可能会出现某些国家很多的订单记录,某些国家几乎没有订单记录,进而数据分布不均。相对正确的方式,比如订单类系统,可以选择订单 ID;会员系统,可以选择会员 ID。
3.3 如何路由
选定了分片的键之后,接下来需要探讨的问题,就是如何路由到具体的数据库和具体的表。以分片键路由到具体某一个数据库为例,常见的路由方式如下:
映射路由
映射路由,即新增一个库,新建一个路由映射表,存储分片键值和对应的库之间的映射关系。比如,键值为 1001,映射到 db01 这个数据库,如下图所示:

映射方式,优点是映射方式可任意调整,扩容简单,但是存在一个比较严重的不足,就是映射库中的映射表的数据量异常巨大。我们本来的目标是要实现分库分表的功能,可是现在,映射库映射表相当于回到了分库分表之前的状态。所以,我们在实践中,没有采取这种方式。
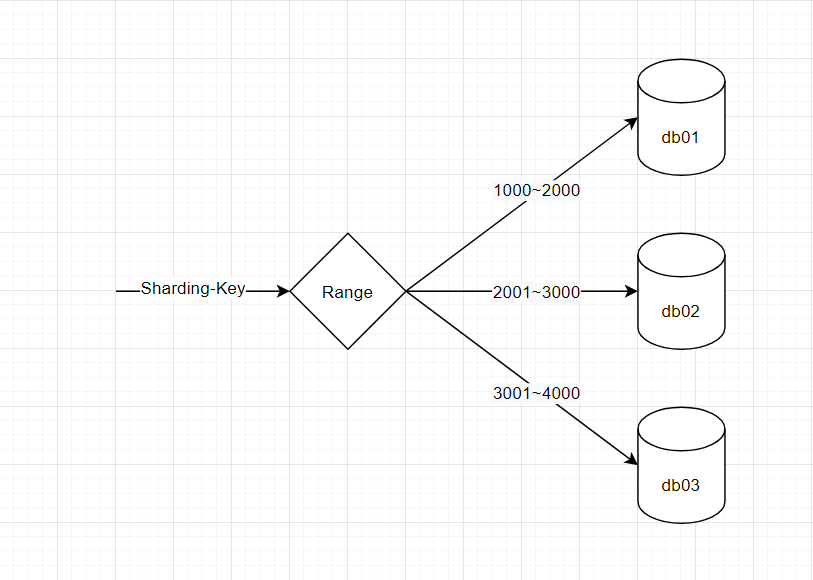
分组路由
分组路由,即对分片的键值,进行分组,每组对应到一个具体的数据库。比如,键值为 1000 到 2000,则存储到 db01 这个数据库,如下图所示:
分组方式,优点是扩容简单,实现简单,但是也存在一个比较严重的不足,是数据分布热点问题,比如在某一个时间内,分片键值为 2001,则在将来一段时间内,所有的数据流量,全部打到某一个库(db02)。这个问题,在互联网环境下,也比较严重,比如在一些促销活动中,订单量会有一个明显的飙升,这时候各个数据库不能达到分摊流量的效果,只有一个库在接收流量,会回到分库分表之前的状态。所以,我们也没有采取这种方式。
哈希路由
哈希路由,即对分片的键值,进行哈希,然后根据哈希结果,对应到一个具体的数据库。比如,键值为 1000,对其取哈希的结果为 01,则存储到 db01 这个数据库,如下图所示:
哈希方式,优点是分布均匀,无热点问题,但是反过来,数据扩容比较麻烦。因为在扩容过程中,需要调整哈希函数,随之带出一个数据迁移问题。互联网环境下,迁移过程中往往不能进行停服,所以就需要类似多库双写等方式进行过渡,比较麻烦。所以,在实践中也没有采取这种方式。
分组哈希路由
分组哈希路由,即对分片的键值,先进行分组,后再进行哈希。如下图所示:
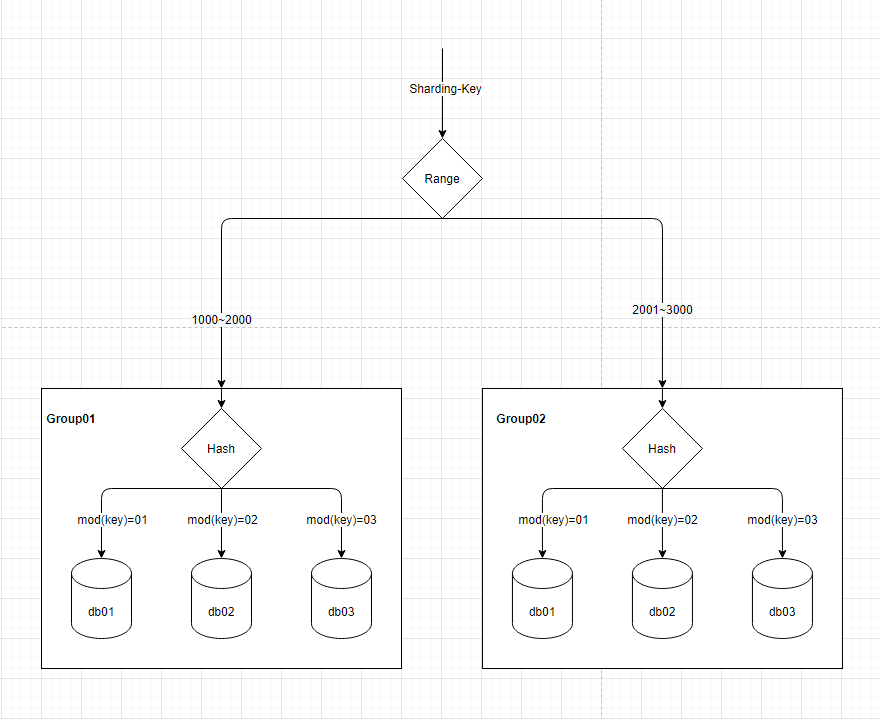
在实践中,我们结合了前面的几种方式,借鉴了他们的优点不足,而采用了此种方式。因为分组方式,能很方便的进行扩容,解决了数据扩容问题;哈希方式,能解决分布相对均匀,无单点数据库热点问题。
3.4 技术中间件
分库分表的中间件选取,在行业内的方案还是比较多的,公司也有自己的实现。根据实现方式的不同,可以分为代理和非代理方式,下面列举了一些业界常见的中间件,如下表(截至于 2021-04-08):
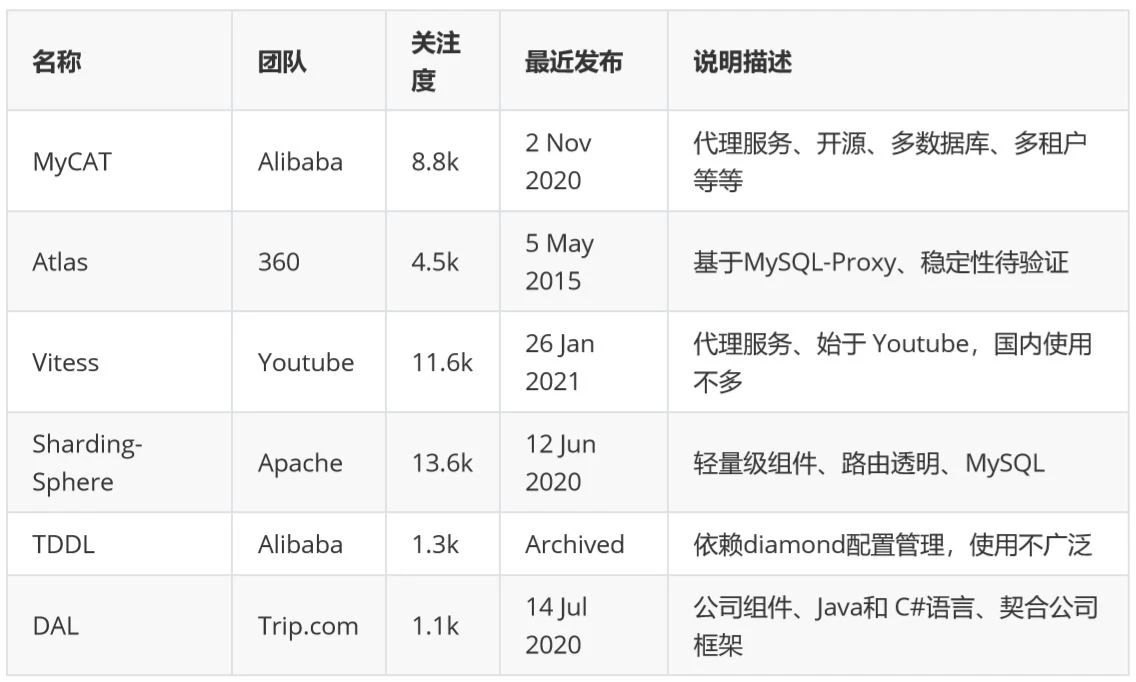
我们为什么最终选择了 ShardingSphere 呢?主要从这几个因素考虑:
技术环境
-
我们团队是 Java 体系下的,对 Java 中间件有一些偏爱
-
更偏向于轻量级组件,可以深入研究的组件
-
可能会需要一些个性定制化
专业程度
-
取决于中间件由哪个团队进行维护,是否是名师打造,是否是行业标杆
-
更新迭代频率,最好是更新相对频繁,维护较积极的
-
流行度问题,偏向于流行度广、社区活跃的中间件
-
性能问题,性能能满足我们的要求
使用成本
-
学习成本、入门成本和定制改造成本
-
弱浸入性,对业务能较少浸入
-
现有技术栈下的迁移成本,我们当前技术栈是 SSM 体系下
运维成本
-
高可用、高稳定性
-
减少硬件资源,不希望再单独引入一个代理中间件,还要考虑运维成本
-
丰富的埋点、完善的监控
四、业务实践
在业务实践中,我们经历了从新库新表的设计,分库分表自建代理、服务收口、上游订单应用迁移,历史数据迁移等过程。
4.1 新表模型
为了建立分库分表下的关联关系,和更加合理有效的结构,我们新申请了订单分库分表的几个库,设计了一套全新的表结构。表名以年份结尾、规范化表字段、适当增删了部分字段、不使用自增主键关联,采用业务唯一键进行关联等。
表结构示例如下图:

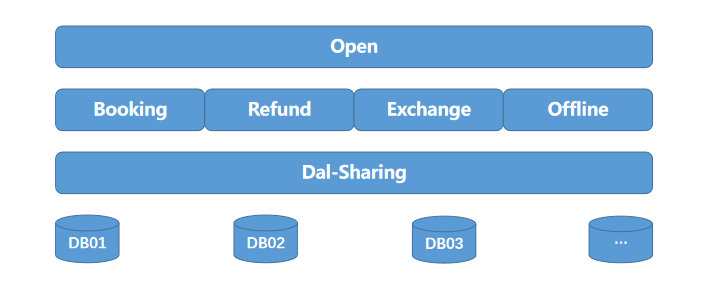
4.2 服务收口
自建了一个分库分表数据库的服务代理 Dal-Sharding。每一个需要操作订单库的服务,都要通过代理服务进行操作数据库,达到服务的一个收口效果。同时,屏蔽了分库分表的复杂性,规范数据库的基本增删改查方法。
4.3 平滑过渡
应用迁移过程中,为了保证应用的平滑过渡,我们新增了一些同步逻辑,来保证应用的顺利迁移,在应用迁移前后,对应用没有任何影响。未迁移的应用,可以读取到迁移后应用写入的订单数据;迁移后的应用,能读取到未迁移应用写入的订单数据。同时,统一实现了此逻辑,减少各个应用的迁移成本。
新老库双读
顾名思义,就是在读取的时候,两个库可能都要进行读取,即优先读取新库,如果能读到记录,直接返回;否则,再次读取老库记录,并返回结果。
双读的基本过程如下:
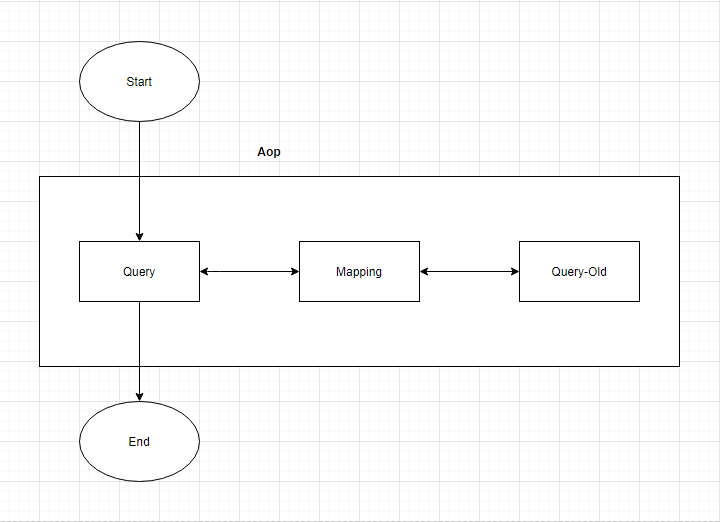
新老库双读,保证了应用迁移过程中读取的低成本,上游应用不需要关心数据来源于新的库还是老的库,只要关心数据的读取即可,减少了切换新库和分库分表的逻辑,极大的减少了迁移的工作量。
实践过程中,我们通过切面实现双读逻辑,将双读逻辑放入到切面中进行,减小新库的读取逻辑的侵入,方便后面实现对双读逻辑的移除调整。
同时,新增一些配置,比如可以控制到哪些表需要进行双读,哪些表不需要双读等。
新老库双写
新老库双写,就是在写入新库成功后,异步写入到老库中。双写使得新老库都同时存在这些订单数据,尚未迁移通过代理服务操作数据库的应用得以正常的运作。
双写的基本过程如下:
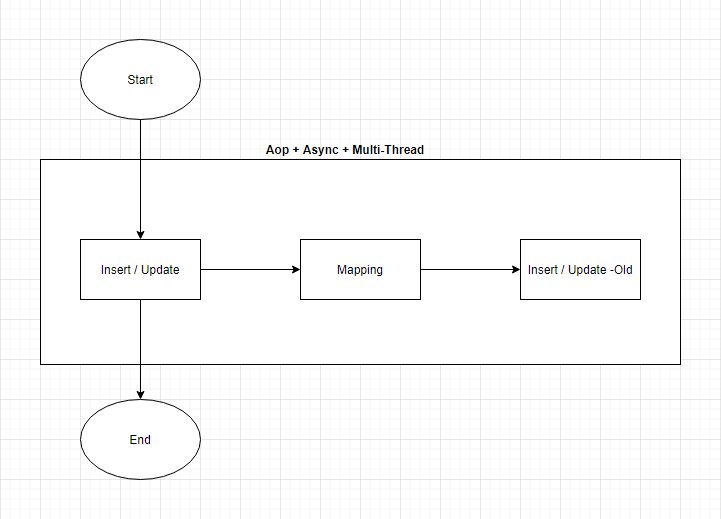
双写其实有较多的方案,比如基于数据库的日志,通过监听解析数据库日志实现同步;也可以通过切面,实现双写;还可以通过定时任务进行同步;另外,结合到我们自己的订单业务,我们还可以通过订单事件(比如创单成功、出票成功、退票成功等),进行双写,同步数据到老库中。
目前,我们经过考虑,没有通过数据库日志来实现,因为这样相当于把逻辑下沉到了数据库层面,从实现上不够灵活,同时,可能还会涉及到一些权限、排期等问题。实践中,我们采取其他三种方式,互补形式,进行双写。异步切面双写,保证了最大的时效性;订单事件,保证了核心节点的一致性;定时任务,保证了最终的一致性。
跟双读一样,我们也支持配置控制到哪些表需要进行双写,那些表不需要双写等。
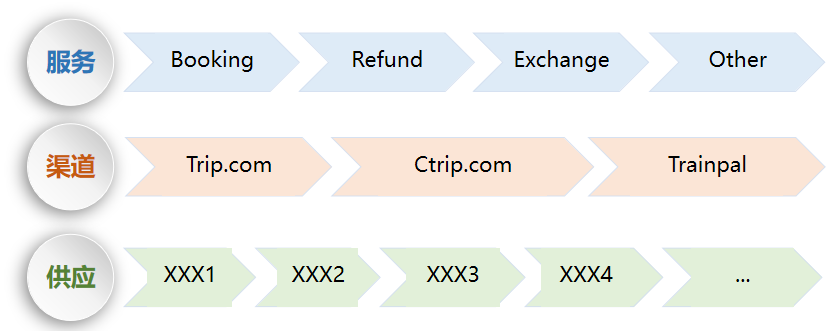
过渡迁移
有了前面的双读双写作为基础,迁移相对容易实行,我们采取逐个迁移的方式,比如,按照服务、按照渠道和按照供应进行迁移,将迁移工作进行拆解,减少影响面,追求稳健。一般分为三步走方式:
1)第一阶段,先在新对接的供应商中进行迁移新库,因为新上线的供应商,订单量最少,同时哪怕出现了问题,不至于影响到之前的业务。
2)再次迁移量比较少的线上业务,此类订单,有一些量,但是追求稳定,不能因为切换新库而产生影响。所以,将此类业务放到了第二阶段中进行。
3)最后一步是,将量较大的业务,逐渐迁移到新库中,此类业务,需要在在有前面的保证后,方能进行迁移,保证订单的正常进行。
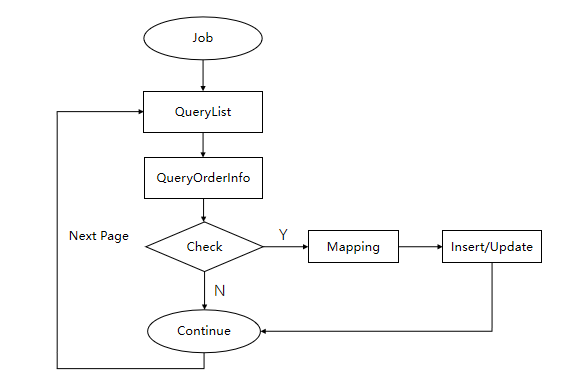
4.4 数据迁移
数据迁移,即将数据,从老库迁移到新库,是新老库切换的一个必经过程。迁移的常规思路,一般是每个表一个个进行迁移,结合业务,我们没有采取此做法,而是从订单维度进行迁移。
举个例子:假如订单库有 Order 表、OrderStation 表、OrderFare 表三个表,我们没有采取一个一个表分别进行迁移,而是根据订单号,以每一个订单的信息,进行同步。
大致过程如下:
1)开启一个定时任务,查询订单列表,取得订单号等基本订单信息。
2)根据这个订单号,去分别查询订单的其他信息,取得一个完整的订单信息。
3)校验订单是否已经完成同步,之前完成同步了则直接跳过,否则继续执行下一个订单号。
4)将老库的完整的订单信息,映射成新库的对应的模型。
5)将新的订单信息,同步写入到新库各个表中。
6)继续执行下一个订单号,直到所有的订单号都完全同步结束。
4.5 完成效果
订单库经过一个全新的重构,目前已经在线上稳定运行,效果显著,达到了我们想要的效果。
-
服务收口,将分库分表逻辑,收口到了一个服务中;
-
接口统一管理,统一对敏感字段进行加密;
-
功能灵活,提供丰富的功能,支持定制化;
-
分库分表路由透明,且基于主流技术,易于上手;
-
完善的监控,支持到表维度的监控;
五、常见问题总结
5.1 分库分表典型问题
问题1:如何进行跨库操作,关联查询,跨库事务?
回答:对于跨库操作,在订单主流程应用中,我们目前是禁止了比如跨库查询、跨库事务等操作的。对于跨库事务,因为根据订单号、创建年份路由,都是会路由到同一个数据库中,也不会存在跨库事务。同样对于跨库关联查询,也不会存在,往往都是根据订单来进行查询。同时,也可以适当进行冗余,比如存储车站编码的同时,多存储一个车站名称字段。
问题2:如何进行分页查询?
回答:目前在订单主流程应用中的分页查询,我们直接采用了 Sharding-JDBC 提供的最原始的分页方式,直接按照正常的分页 SQL,来进行查询分页即可。理由:主流程订单服务,比如出票系统,往往都是查询前面几页的订单,直接查询即可,不会存在很深的翻页。当然,对于要求较高的分页查询,可以去实现二次查询,来实现更加高效的分页查询。
问题3:如何支持很复杂的统计查询?
回答:专门增加了一个宽表,来满足那些很复杂查询的需求,将常用的查询信息,全部落到此表中,进而可以快速得到这些复杂查询的结果。
5.2 API 方法问题
问题:服务收口后,如何满足业务各种不同的查询条件?
回答:我们的 API 方法,相对固定,一般查询类只有两个方法,根据订单号查询,和根据 Condition 查询条件进行查询。对于各种不同的查询条件,则通过新增 Condition 的字段属性来实现,而不会新增各种查询方法。
5.3 均匀问题
问题:在不同 group 中,数据会存在分布不均匀,存在热点问题?
回答:是的,比如运行 5 年后,我们拓展成了 3 个 group,每一个 group 中存在 3 个库,那么此时,读写最多的应该是第三个 group。不过这种分布不均匀问题和热点问题,是可接受的,相当于前面的两个 group,可以作为历史归档 group,目前主要使用的 group 为第三个 group。
随着业务的发展,你可以进行调配,比如业务发展迅速,那么相对合理的分配,往往不会是每个 group 是 3 个库,更可能是应该是,越往后 group 内的库越多。同时,因为每个 group 内是存在多个库,与之前的某一个库的热点问题是存在本质差别,而不用担心单数据库瓶颈问题,可以通过加库来实现扩展。
5.4 Group 内路由问题
问题:对于仅根据订单号查询,在 group 内的路由过程是读取 group 内所有的表吗?
回答:根据目前的设计,是的。目前是按年份分组,订单号不会存储其他信息,采用携程统一方式生成,也就是如果根据订单号查询,我们并不知道是存在于哪个表,则需要查询 group 内所有的表。对于此类问题,通常推荐做法是,可以适当增加因子,在订单号中,存储创建年份信息,这样就可以知道对应那个表了;也可以年份适当进行延伸,比如每 5 年一次分表,那么这样调整后,一个 group 内的表应该相对很少,可以极大加快查询效能。
5.5 异步双写问题
问题:为什么双写过程,采用了多种方式结合的方式?
回答:首先,切面方式,能最大限度满足订单同步的时效性。但是,在实践过程中,我们发现,异步切面双写,会存在多线程并发问题。因为在老库中,表的关联关系依赖于数据库的自增 ID,依赖于表的插入顺序,会存在关联失败的情况。所以,单纯依靠切面同步还不够,还需要更加稳健的方式,即定时任务(订单事件是不可靠消息事件,即可能会存在丢失情况)的方式,来保证数据库的一致性。
关于作者
我们是携程火车票研发团队,负责火车票业务的开发以及创新。火车票研发在多种交通线路联程联运算法、多种交通工具一站式预定、高并发方向不断地深入探索和创新,持续优化用户体验,提高效率,致力于为全球人民买全球火车票。
