
经过近两年时间的优化和打磨,Apache ShardingSphere 5.0.0 GA 版终于在本月正式发布,相比于 4.1.1 GA 版,5.0.0 GA 版在内核层面进行了大量的优化。**首先,基于可插拔架构对内核进行了全面改造,内核中的各个功能可以任意组合并叠加使用。其次,为了提升 SQL 分布式查询能力,5.0.0 GA 版打造了全新的
Federation执行引擎,来满足用户复杂的业务场景。此外,5.0.0 GA 版在内核功能 API 层面也进行了大量优化,旨在降低用户使用这些功能的成本。**本文将为大家详细解读 5.0.0 GA 版中的这些重大内核优化,并将对比两个 GA 版本中存在的差异,以典型的数据分片、读写分离和加解密整合使用的场景为例,帮助用户更好地理解这些优化并完成版本升级。
作者介绍

端正强
SphereEx 高级中间件开发工程师,Apache ShardingSphere Committer。
2018 年开始接触 Apache ShardingSphere 中间件,曾主导公司内部海量数据的分库分表,有着丰富的实践经验;热爱开源,乐于分享,目前专注于 Apache ShardingSphere 内核模块开发。
可拔插架构内核
Apache ShardingSphere 5.0.0 GA 版提出了全新的 Database Plus 理念,目标是构建异构数据库上层标准和生态,为用户提供精准化和差异化的能力。Database Plus 具有连接、增量、可插拔的特点,具体来说,Apache ShardingSphere 能够连接不同的异构数据库,基于异构数据库的基础服务,提供数据分片、数据加解密及分布式事务等增量功能。另外,通过可插拔平台,Apache ShardingSphere 提供的增量功能能够无限扩展,用户也可以根据需求灵活进行扩展。Database Plus 理念的出现,使得 ShardingSphere 真正意义上从一个分库分表中间件蜕变成为一套强大的分布式数据库生态系统。通过践行 Database Plus 理念,基于可插拔平台提供的扩展点,Apache ShardingSphere 内核也进行了全面地可插拔化改造。下图展示了全新的可插拔架构内核:
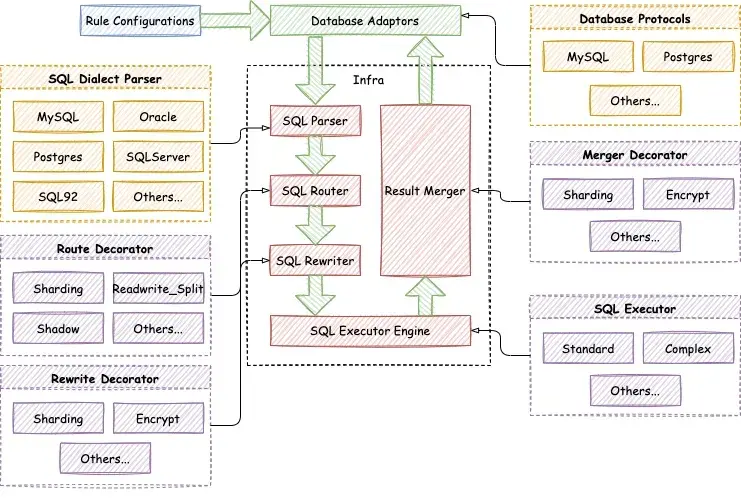
Apache ShardingSphere 内核流程中的元数据加载、SQL 解析、SQL 路由 、SQL 改写、SQL 执行和结果归并,都提供了丰富的扩展点,基于这些扩展点,Apache ShardingSphere 默认实现了数据分片、读写分离、加解密、影子库压测及高可用等功能。
按照扩展点是基于技术还是基于功能实现,我们可以将扩展点划分为功能扩展点和技术扩展点。Apache ShardingSphere 内核流程中,SQL 解析引擎及 SQL 执行引擎的扩展点属于技术扩展点,而元数据加载、SQL 路由引擎、SQL 改写引擎及结果归并引擎的扩展点属于功能扩展点。
SQL 解析引擎扩展点,主要包括 SQL 语法树解析及 SQL 语法树遍历两个扩展点。Apache ShardingSphere 的 SQL 解析引擎,基于这两个扩展点,默认支持了 MySQL、PostgreSQL、Oracle、SQLServer、openGauss 和 SQL92 等数据库方言的解析和遍历。用户也可以基于这两个扩展点,实现 Apache ShardingSphere SQL 解析引擎暂不支持的数据库方言,以及开发诸如 SQL 审计这样的新功能。
SQL 执行引擎扩展点按照不同的执行方式来提供扩展,目前 Apache ShardingSphere SQL 执行引擎已经提供了单线程执行引擎和多线程执行引擎。单线程执行引擎主要用于处理包含事务的语句执行,多线程执行引擎则适用于不包含事务的场景,用于提升 SQL 执行的性能。未来,Apache ShardingSphere 将基于执行引擎扩展点,提供诸如 MPP 执行引擎在内的更多执行引擎,满足分布式场景下 SQL 执行的要求。
基于功能扩展点,Apache ShardingSphere 提供了数据分片、读写分离、加解密、影子库压测及高可用等功能,这些功能根据各自需求,实现了全部或者部分功能扩展点,并且在功能内部,又通过细化功能级扩展点提供了诸如分片策略、分布式 ID 生成及负载均衡算法等内部扩展点。下面是 Apache ShardingSphere 内核功能实现的扩展点:
- 数据分片: 实现了元数据加载、SQL 路由、SQL 改写和结果归并的全部功能扩展点,在数据分片功能内部,又提供了分片算法、分布式 ID 等扩展点;
- 读写分离: 实现了 SQL 路由的功能扩展点,功能内部提供了负载均衡算法扩展点;
- 加解密: 实现了元数据加载、SQL 改写和结果归并的扩展点,内部提供了加解密算法扩展点;
- 影子库压测: 实现了 SQL 路由的扩展点,在影子库压测功能内部,提供了影子算法扩展点;
- 高可用: 实现了 SQL 路由的扩展点。
基于这些扩展点,Apache ShardingSphere 功能的可扩展空间非常大,像多租户和 SQL 审计等功能,都可以通过扩展点无缝地集成到 Apache ShardingSphere 生态中。此外,用户也可以根据自己的业务需求,基于扩展点完成定制化功能开发,快速地搭建出一套分布式数据库系统。关于可插拔架构扩展点的详细说明,可以参考官网开发者手册:
https://shardingsphere.apache.org/document/current/cn/dev-manual/
综合对比来看,5.0.0 GA 版可插拔架构内核和 4.1.1 GA 版内核主要的差异如下:
| 版本 | 4.1.1 GA | 5.0.0 GA |
|---|---|---|
| 定位 | 分库分表中间件 | 分布式数据库生态系统 |
| 功能 | 提供基础功能 | 提供基础设施和最佳实践 |
| 耦合 | 耦合较大,存在功能依赖 | 相互隔离,互无感知 |
| 组合使用 | 固定的组合方式,必须以数据分片为基础,叠加读写分离和加解密等功能 | 功能自由组合,数据分片、读写分离、影子库压测、加解密和高可用等功能可以任意叠加组合 |
首先,从项目定位上来看,5.0.0 GA 版借助可插拔架构实现了从分库分表中间件到分布式数据库生态系统的转变,各个功能都可以通过可插拔架构融入到分布式数据库生态系统中。其次,从项目功能上来看,4.1.1 GA 版只提供一些基础功能,而 5.0.0 GA 版则更加侧重于提供基础设施,以及一些功能的最佳实践,用户完全可以舍弃这些功能,基于内核基础设施开发定制化功能。从功能耦合的角度来看,5.0.0 GA 版的内核功能,做到了相互隔离,互无感知,这样可以最大程度地保证内核的稳定性。最后,从功能组合使用的角度来看,5.0.0 GA 版实现了功能的层级一致,数据分片、读写分离、影子库压测、加解密和高可用等功能,可以按照用户的需求任意组合。而在 4.1.1 GA 版中,用户在组合使用这些功能时,必须以数据分片为中心,再叠加使用其他功能。
通过这些对比可以看出, 5.0.0 GA 版可插拔内核进行了全方位地增强,用户可以像搭积木一样对功能进行叠加组合,从而满足更多业务需求。但是,可插拔架构的调整也导致了内核功能的使用方式出现了很大的变化,在文章的后续内容中,我们会通过实例来详细介绍在 5.0.0 GA 版中如何组合使用这些功能。
Federation 执行引擎
Federation 执行引擎是 5.0.0 GA 版内核的又一大亮点功能,目标是支持那些在 4.1.1 GA 版中无法执行的分布式查询语句,例如:跨数据库实例的关联查询及子查询。Federation 执行引擎的出现,使得业务研发人员不必再关心 SQL 的使用范围,能够专注于业务功能开发,减少了业务层面的功能限制。
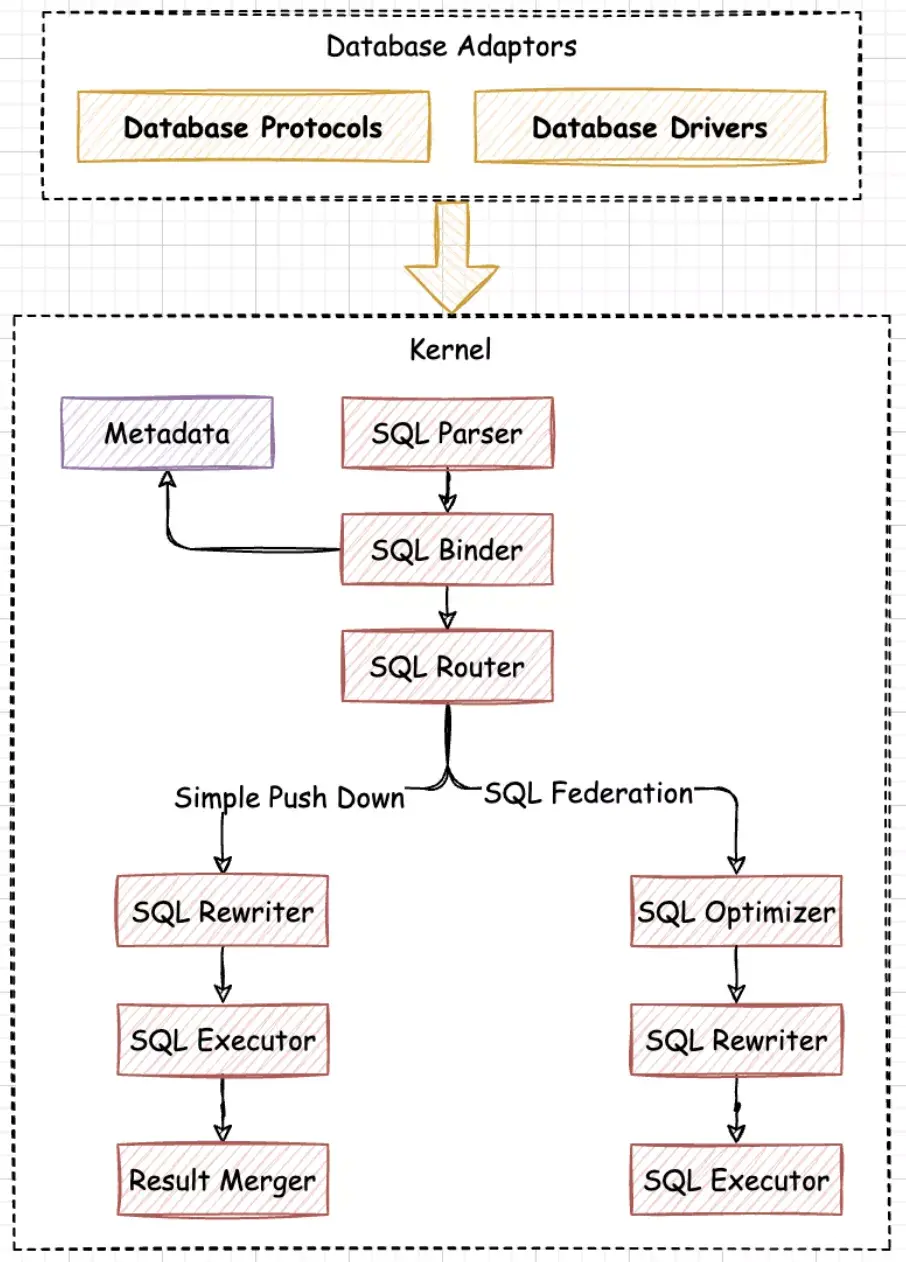
上图展示了 Federation 执行引擎的处理流程,总体上来看,仍然是遵循着 SQL 解析、SQL 路由、SQL 改写、SQL 执行这几个步骤,唯一的区别是 Federation 执行引擎额外引入了 SQL 优化,对分布式查询语句进行 RBO(Rule Based Optimizer) 和 CBO(Cost Based Optimizer) 优化,从而得到代价最小的执行计划。在 SQL 路由阶段,路由引擎会根据 SQL 语句是否跨多个数据库实例,来决定 SQL 是否通过 Federation 执行引擎来执行。
Federation 执行引擎目前处于快速开发中,仍然需要大量的优化,还是一个实验性的功能,因此默认是关闭的,如果想要体验 Federation 执行引擎,可以通过配置 sql-federation-enabled: true 来开启该功能。
Federation 执行引擎主要用来支持跨多个数据库实例的关联查询和子查询,以及部分内核不支持的聚合查询。下面我们通过具体的场景,来了解下 Federation 执行引擎支持的语句。
- 跨库关联查询: 当关联查询中的多个表分布在不同的数据库实例上时,由 Federation 执行引擎提供支持。
例如,在下面的数据分片配置中,t_order 和 t_order_item 表是多数据节点的分片表,并且未配置绑定表规则,t_user 和 t_user_role 则是分布在不同的数据库实例上的单表。
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
t_order_item:
actualDataNodes: ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
由于跨多个数据库实例,下面这些常用的 SQL,会使用 Federation 执行引擎进行关联查询。
SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id WHERE o.order_id = 1;
SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE o.user_id = 1;
SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE o.user_id = 1;
SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE i.user_id = 1;
SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id WHERE i.user_id = 1;
SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE u.user_id = 1;
- 子查询: Apache ShardingSphere 的 Simple Push Down 引擎能够支持分片条件一致的子查询,以及路由到单个分片的子查询。对于子查询和外层查询未同时指定分片键,或分片键的值不一致的场景,需要由 Federation 执行引擎来提供支持。
下面展示了一些由 Federation 执行引擎支持的子查询场景:
SELECT * FROM (SELECT * FROM t_order) o;
SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1;
SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o;
SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id = 2;
- 聚合查询: 对于 Apache ShardingSphere Simple Push Down 引擎暂不支持的一些聚合查询,我们也同样通过 Federation 执行引擎提供了支持。
SELECT user_id, SUM(order_id) FROM t_order GROUP BY user_id HAVING SUM(order_id) > 10;
SELECT (SELECT MAX(user_id) FROM t_order) a, order_id FROM t_order;
SELECT COUNT(DISTINCT user_id), SUM(order_id) FROM t_order;
Federation 执行引擎的出现,使得 Apache ShardingSphere 分布式查询能力得到明显增强,未来 Apache ShardingSphere 将持续优化,有效降低 Federation 执行引擎的内存占用,不断提升分布式查询的能力。关于 Federation 执行引擎支持语句的详细清单,可参考官方文档中的实验性支持的 SQL :
https://shardingsphere.apache.org/document/5.0.0/cn/features/sharding/use-norms/sql/
内核功能 API 调整
为了降低用户使用内核功能的成本,5.0.0 GA 版在 API 层面也进行了大量的优化。首先,针对社区反馈较多的数据分片 API 过于复杂、难以理解的问题,经过社区充分讨论之后,在 5.0.0 GA 版中提供了全新的数据分片 API。同时,随着 Apache ShardingSphere 项目定位的变化——由传统数据库中间件蜕变为分布式数据库生态系统,实现透明化的数据分片功能也变得越发重要。因此,5.0.0 GA 版提供了自动化的分片策略,用户无需关心分库分表的细节,通过指定分片数即可实现自动分片。此外,由于可插拔架构的提出,以及影子库压测等功能的进一步增强,内核功能 API 都进行了相应的优化调整。下面我们将会从不同功能的角度,为大家详细介绍 5.0.0 GA 版 API 层面的调整。
数据分片 API 调整
在 4.x 版中,社区经常反馈数据分片的 API 过于复杂,难以理解。下面是 4.1.1 GA 版中的数据分片配置,分片策略包含了 standard、complex、inline、hint 和 none 5 种策略,不同的分片策略之间参数也大不相同,导致普通用户很难理解和使用。
shardingRule:
tables:
t_order:
databaseStrategy:
standard:
shardingColumn: order_id
preciseAlgorithmClassName: xxx
rangeAlgorithmClassName: xxx
complex:
shardingColumns: year, month
algorithmClassName: xxx
hint:
algorithmClassName: xxx
inline:
shardingColumn: order_id
algorithmExpression: ds_${order_id % 2}
none:
tableStrategy:
...
5.0.0 GA 版对分片 API 中的分片策略进行了简化,首先去除了原有的 inline 策略,只保留了 standard、complex、hint 和 none这四个分片策略,同时将分片算法从分片策略中抽取出来,放到 shardingAlgorithms 属性下进行单独配置,分片策略中通过指定 shardingAlgorithmName 属性进行引用即可。
rules:
- !SHARDING
tables:
t_order:
databaseStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: database_inline
complex:
shardingColumns: year, month
shardingAlgorithmName: database_complex
hint:
shardingAlgorithmName: database_hint
none:
tableStrategy:
...
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ds_${order_id % 2}
database_complex:
type: CLASS_BASED
props:
strategy: COMPLEX
algorithmClassName: xxx
database_hint:
type: CLASS_BASED
props:
strategy: HINT
algorithmClassName: xxx
上面是根据 4.1.1 GA 版分片配置修改后的配置,可以看出新的分片 API 更加简洁清晰。同时为了减少用户的配置量,Apache ShardingSphere 提供了众多内置分片算法供用户选择,用户也可以通过 CLASS_BASED 分片算法进行自定义。更多关于内置分片算法的内容,可以参考官方文档内置算法-分片算法:
除了优化数据分片 API 之外,为了能够实现透明化数据分片,5.0.0 GA 版还提供了自动化的分片策略。下面展示了自动化分片策略配置和手动声明分片策略配置的差异:
rules:
- !SHARDING
autoTables:
# 自动分片策略
t_order:
actualDataSources: ds_0, ds_1
shardingStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: auto_mod
keyGenerateStrategy:
column: order_id
keyGeneratorName: snowflake
shardingAlgorithms:
auto_mod:
type: MOD
props:
sharding-count: 4
tables:
# 手动声明分片策略
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: table_inline
dataBaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
自动化分片策略,需要配置在 autoTables 属性下,用户只需要指定数据存储的数据源,同时通过自动分片算法指定分片数即可,不再需要通过 actualDataNodes 来手动声明数据分布,也无需专门设置分库策略和分表策略,Apache ShardingSphere 将自动实现数据分片管理。
此外,5.0.0 GA 版删除了数据分片 API 中的 defaultDataSourceName 配置。在 5.0.0 GA 版中,Apache ShardingSphere 定位为分布式数据库生态系统,用户可以像使用传统数据库一样,直接使用 Apache ShardingSphere 提供的服务,因此用户无需感知底层的数据库存储。Apache ShardingSphere 通过内置的 SingleTableRule 来管理数据分片之外的单表,帮助用户实现单表的自动加载和路由。
5.0.0 GA 版为了进一步简化用户配置,同时配合数据分片 API 中的 defaultDatabaseStrategy 和 defaultTableStrategy 分片策略,增加了 defaultShardingColumn 配置,作为默认的分片键。当多个表分片键相同时,用户可以不配置 shardingColumn,使用默认的 defaultShardingColumn 配置。下面的分片配置中,t_order 表的分片策略都会使用默认的 defaultShardingColumn 配置。
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingAlgorithmName: table_inline
defaultShardingColumn: order_id
defaultDatabaseStrategy:
standard:
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
读写分离 API 调整
读写分离 API 的基本功能,在 5.0.0 GA 版变化不大,只是由 MasterSlave 调整为ReadWriteSplitting,其他用法基本相同。下面是 4.1.1 GA 版和 5.0.0 GA 版读写分离 API 的对比。
# 4.1.1 GA 读写分离 API
masterSlaveRule:
name: ms_ds
masterDataSourceName: master_ds
slaveDataSourceNames:
- slave_ds_0
- slave_ds_1
# 5.0.0 GA 读写分离 API
rules:
- !READWRITE_SPLITTING
dataSources:
pr_ds:
writeDataSourceName: write_ds
readDataSourceNames:
- read_ds_0
- read_ds_1
此外,在 5.0.0 GA 版中,基于可插拔架构开发了高可用功能,读写分离可以配合高可用功能,提供能够自动切换主从的高可用版读写分离,欢迎大家关注高可用功能后续的官方文档及技术分享。
加解密 API 调整
5.0.0 GA 版对于加解密 API 进行了小幅度优化,增加了 table 级别的 queryWithCipherColumn 属性,方便用户能够对加解密字段的明文、密文切换进行表级别的控制,其他配置和 4.1.1 GA 版基本保持一致。
rules:
- !ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
md5_encryptor:
type: MD5
tables:
t_encrypt:
columns:
user_id:
plainColumn: user_plain
cipherColumn: user_cipher
encryptorName: aes_encryptor
order_id:
cipherColumn: order_cipher
encryptorName: md5_encryptor
queryWithCipherColumn: true
queryWithCipherColumn: false
影子库压测 API 调整
影子库压测 API,在 5.0.0 GA 版中进行了全面调整,首先删除了影子库中的逻辑列,并增加了功能强大的影子库匹配算法,用来帮助用户实现更加灵活的路由控制。下面是 4.1.1 GA 版影子库压测的 API,总体上功能较为简单,根据逻辑列对应的值判断是否开启影子库压测。
shadowRule:
column: shadow
shadowMappings:
ds: shadow_ds
5.0.0 GA 版中影子库压测 API 则更加强大,用户可以通过 enable 属性,控制是否开启影子库压测,同时可以按照表的维度,细粒度控制需要进行影子库压测的生产表,并支持多种不同的匹配算法,例如:列值匹配算法、列正则表达式匹配算法以及 SQL 注释匹配算法。
rules:
- !SHADOW
enable: true
dataSources:
shadowDataSource:
sourceDataSourceName: ds
shadowDataSourceName: shadow_ds
tables:
t_order:
dataSourceNames:
- shadowDataSource
shadowAlgorithmNames:
- user-id-insert-match-algorithm
- simple-hint-algorithm
shadowAlgorithms:
user-id-insert-match-algorithm:
type: COLUMN_REGEX_MATCH
props:
operation: insert
column: user_id
regex: "[1]"
simple-hint-algorithm:
type: SIMPLE_NOTE
props:
shadow: true
foo: bar
在后续的技术分享文章中,我们会对影子库压测功能进行详细介绍,此处就不展开说明,更多影子库匹配算法可以参考官方文档影子算法:影子算法 :: ShardingSphere
5.0.0 GA 升级指南
前面分别从可插拔内核架构、Federation 执行引擎以及内核功能 API 调整三个方面,详细地介绍了 5.0.0 GA 版内核的重大优化。面对两个版本存在的众多差异,大家最关心的莫过于如何从 4.1.1 GA 升级到 5.0.0 GA 版本?下面我们将基于数据分片、读写分离和加解密整合使用这样一个典型的场景,详细介绍下升级 5.0.0 GA 版本需要注意哪些问题。
在 4.1.1 GA 中,组合使用多个功能时,必须以数据分片为基础,然后叠加读写分离和加解密,因此 4.1.1 GA 版中的配置通常如下:
shardingRule:
tables:
t_order:
actualDataNodes: ms_ds_${0..1}.t_order_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
t_order_item:
actualDataNodes: ms_ds_${0..1}.t_order_item_${0..1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_item_${order_id % 2}
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDataSourceName: ds_0
defaultDatabaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ms_ds_${user_id % 2}
defaultTableStrategy:
none:
masterSlaveRules:
ms_ds_0:
masterDataSourceName: ds_0
slaveDataSourceNames:
- ds_0_slave_0
- ds_0_slave_1
loadBalanceAlgorithmType: ROUND_ROBIN
ms_ds_1:
masterDataSourceName: ds_1
slaveDataSourceNames:
- ds_1_slave_0
- ds_1_slave_1
loadBalanceAlgorithmType: ROUND_ROBIN
encryptRule:
encryptors:
aes_encryptor:
type: aes
props:
aes.key.value: 123456abc
tables:
t_order:
columns:
content:
plainColumn: content_plain
cipherColumn: content_cipher
encryptor: aes_encryptor
t_user:
columns:
telephone:
plainColumn: telephone_plain
cipherColumn: telephone_cipher
encryptor: aes_encryptor
从上面的配置文件中可以看出,t_order 和 t_order_item配置了分片规则,并且t_order 表的 content字段同时设置了加解密规则,使用 AES 算法进行加解密。t_user则是未分片的普通表,telephone字段也配置了加解密规则。另外需要注意的是,读写分离规则和加解密规则都是以属性的形式,配置在分片规则中,这也是 4.1.1 GA 中功能依赖的具体体现,其他功能都必须以数据分片为基础。
配置完成之后,我们启动 4.1.1 GA 版 Proxy 接入端,对 t_order、t_order_item 及 t_user表进行初始化。初始化语句执行的结果如下:
CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100));
# Logic SQL: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100))
t_order表分片功能路由改写正常,但加解密功能对应的改写没有能够支持,因为 4.1.1 GA 版本不支持加解密场景下 DDL 语句的改写,因此,需要用户在底层数据库上提前创建好对应的加解密表,DDL 语句支持加解密改写在 5.0.0 GA 版已经完美支持,减少了用户不必要的操作。
t_order_item 表由于不涉及加解密,路由改写的结果正常。t_user 表同样存在加解密 DDL 语句改写的问题,并且 t_user 表被路由到了 ds_0 数据源,这是因为我们在分片规则中配置了 defaultDataSourceName: ds_0,所以对于非分片表,都会使用这个规则进行路由。
对于 t_order 表和 t_user 表,我们通过如下 SQL 在路由结果对应的底层数据库上,手动创建加解密表。
# ds_0 创建 t_order_0、t_order_1 和 t_user
CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone_plain VARCHAR(100), telephone_cipher VARCHAR(100))
# ds_1 创建 t_order_0 和 t_order_1
CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_plain VARCHAR(100), content_cipher VARCHAR(100))
我们重启 Proxy 并向 t_order、t_order_item 和 t_user 表添加数据。t_order 和 t_order_item 表在插入数据过程中,会根据分片键及配置的分片策略,路由到对应的数据节点。t_user 表则根据 defaultDataSourceName 配置路由到 ds_0数据源。
INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_0(order_id, user_id, content_cipher, content_plain) VALUES(2, 2, 'mzIhTs2MD3dI4fqCc5nF/Q==', 'TEST22')
# Actual SQL: ds_1 ::: INSERT INTO t_order_1(order_id, user_id, content_cipher, content_plain) VALUES(1, 1, '3qpLpG5z6AWjRX2sRKjW2g==', 'TEST11'), (3, 3, 'oVkQieUbS3l/85axrf5img==', 'TEST33')
INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_item_0(item_id, order_id, user_id, content) VALUES(2, 2, 2, 'TEST22')
# Actual SQL: ds_1 ::: INSERT INTO t_order_item_1(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (3, 3, 3, 'TEST33')
INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333');
# Logic SQL: INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333')
# Actual SQL: ds_0 ::: INSERT INTO t_user(user_id, telephone_cipher, telephone_plain) VALUES(1, 'jFZBCI7G9ggRktThmMlClQ==', '11111111111'), (2, 'lWrg5gaes8eptaQkUM2wtA==', '22222222222'), (3, 'jeCwC7gXus4/1OflXeGW/w==', '33333333333')
然后再执行几个简单的查询语句,看下读写分离是否生效。根据日志可以看出,t_order 和 t_order_item 表,进行了加解密改写,也正确地路由到了从库。而 t_user 表仍然路由到 ds_0 数据源上执行,规则中配置的读写分离规则没有起到作用。这是由于在 4.1.1 GA 版中,读写分离和加解密都是基于分片功能进行整合,这种方案天然限制了分片之外功能的配合使用。
SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_0 ::: SELECT order_id, user_id, content_plain, content_cipher FROM t_order_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_1 ::: SELECT * FROM t_order_item_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_user WHERE user_id = 1;
# Logic SQL: SELECT * FROM t_user WHERE user_id = 1
# Actual SQL: ds_0 ::: SELECT user_id, telephone_plain, telephone_cipher FROM t_user WHERE user_id = 1
5.0.0 GA 版基于可插拔架构,对内核进行了全面地升级,内核中的各个功能都可以任意组合使用。同时,5.0.0 GA 版删除了需要用户额外配置的 defaultDataSourceName,默认通过 SingleTableRule 实现单表的元数据加载及路由。下面我们来看看相同的功能,在 5.0.0 GA 版中是如何配置和使用的,具体配置如下:
rules:
- !SHARDING
tables:
t_order:
actualDataNodes: ms_ds_${0..1}.t_order_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_inline
t_order_item:
actualDataNodes: ms_ds_${0..1}.t_order_item_${0..1}
tableStrategy:
standard:
shardingColumn: order_id
shardingAlgorithmName: t_order_item_inline
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_config
defaultDatabaseStrategy:
standard:
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: ms_ds_${user_id % 2}
t_order_inline:
type: INLINE
props:
algorithm-expression: t_order_${order_id % 2}
t_order_item_inline:
type: INLINE
props:
algorithm-expression: t_order_item_${order_id % 2}
- !READWRITE_SPLITTING
dataSources:
ms_ds_0:
writeDataSourceName: ds_0
readDataSourceNames:
- ds_0_slave_0
- ds_0_slave_1
loadBalancerName: ROUND_ROBIN
ms_ds_1:
writeDataSourceName: ds_1
readDataSourceNames:
- ds_1_slave_0
- ds_1_slave_1
loadBalancerName: ROUND_ROBIN
- !ENCRYPT
encryptors:
aes_encryptor:
type: AES
props:
aes-key-value: 123456abc
tables:
t_order:
columns:
content:
plainColumn: content_plain
cipherColumn: content_cipher
encryptor: aes_encryptor
t_user:
columns:
telephone:
plainColumn: telephone_plain
cipherColumn: telephone_cipher
encryptor: aes_encryptor
首先,从配置上来看,5.0.0 GA 版和 4.1.1 GA 版最大的区别在于不同功能之间的关系,它们是一个平级关系,不存在 4.1.1 GA 中的功能依赖,每个功能都可以通过可插拔的方式灵活加载和卸载。其次,这些功能在整合使用时,使用类似于管道的传递方式,例如:读写分离规则基于两组主从关系,聚合出两个逻辑数据源,分别是 ms_ds_0 和 ms_ds_1。数据分片规则基于读写分离聚合出的逻辑数据源,配置数据分片规则,从而又聚合出逻辑表 t_order。加解密功能则关注于列和值的改写,面向数据分片功能聚合出的逻辑表,配置加解密规则。读写分离、数据分片和加解密功能层层传递,通过装饰模式,不断对功能进行增加。
为了对比 4.1.1 GA 版功能,我们执行同样的初始化语句、插入语句和查询语句对 5.0.0 GA 版进行测试。
CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order(order_id INT(11) PRIMARY KEY, user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_0(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_1(order_id INT(11) PRIMARY KEY, user_id INT(11), content_cipher VARCHAR(100), content_plain VARCHAR(100))
CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100));
# Logic SQL: CREATE TABLE t_order_item(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_0(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
# Actual SQL: ds_0 ::: CREATE TABLE t_order_item_1(item_id INT(11) PRIMARY KEY, order_id INT(11), user_id INT(11), content VARCHAR(100))
CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100));
# Logic SQL: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone VARCHAR(100))
# Actual SQL: ds_1 ::: CREATE TABLE t_user(user_id INT(11) PRIMARY KEY, telephone_cipher VARCHAR(100), telephone_plain VARCHAR(100))
在 5.0.0 GA 版中,增加了对加解密 DDL 语句改写的支持,因此在创建 t_order 过程中,不论是数据分片、读写分离还是加解密,路由和改写都能够正常执行。t_user 表从日志来看,被路由到 ds_1 数据源执行,在 5.0.0 GA 版中,t_user 属于单表,无需用户配置数据源,在执行建表语句时,会随机选择一个数据源进行路由。对于单表,我们需要保证它在逻辑库中唯一,从而保证路由结果的准确性。
INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order(order_id, user_id, content) VALUES(1, 1, 'TEST11'), (2, 2, 'TEST22'), (3, 3, 'TEST33')
# Actual SQL: ds_1 ::: INSERT INTO t_order_1(order_id, user_id, content_cipher, content_plain) VALUES(1, 1, '3qpLpG5z6AWjRX2sRKjW2g==', 'TEST11'), (3, 3, 'oVkQieUbS3l/85axrf5img==', 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_0(order_id, user_id, content_cipher, content_plain) VALUES(2, 2, 'mzIhTs2MD3dI4fqCc5nF/Q==', 'TEST22')
INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33');
# Logic SQL: INSERT INTO t_order_item(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (2, 2, 2, 'TEST22'), (3, 3, 3, 'TEST33')
# Actual SQL: ds_1 ::: INSERT INTO t_order_item_1(item_id, order_id, user_id, content) VALUES(1, 1, 1, 'TEST11'), (3, 3, 3, 'TEST33')
# Actual SQL: ds_0 ::: INSERT INTO t_order_item_0(item_id, order_id, user_id, content) VALUES(2, 2, 2, 'TEST22')
INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333');
# Logic SQL: INSERT INTO t_user(user_id, telephone) VALUES(1, '11111111111'), (2, '22222222222'), (3, '33333333333')
# Actual SQL: ds_1 ::: INSERT INTO t_user(user_id, telephone_cipher, telephone_plain) VALUES(1, 'jFZBCI7G9ggRktThmMlClQ==', '11111111111'), (2, 'lWrg5gaes8eptaQkUM2wtA==', '22222222222'), (3, 'jeCwC7gXus4/1OflXeGW/w==', '33333333333')
在对 t_user表执行数据插入时,会根据元数据中存储的信息来进行自动路由,由于前一个步骤中t_user路由到了ds_1数据源,因此其他语句会根据t_user: ds_1这样的元数据进行路由处理。
SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_0 ::: SELECT `t_order_1`.`order_id`, `t_order_1`.`user_id`, `t_order_1`.`content_cipher` AS `content` FROM t_order_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1;
# Logic SQL: SELECT * FROM t_order_item WHERE user_id = 1 AND order_id = 1
# Actual SQL: ds_1_slave_1 ::: SELECT * FROM t_order_item_1 WHERE user_id = 1 AND order_id = 1
SELECT * FROM t_user WHERE user_id = 1;
# Logic SQL: SELECT * FROM t_user WHERE user_id = 1
# Actual SQL: ds_1_slave_0 ::: SELECT `t_user`.`user_id`, `t_user`.`telephone_cipher` AS `telephone` FROM t_user WHERE user_id = 1
在执行查询语句时,我们可以发现,t_user表被路由到了ds_1_slave_0数据源,实现了单表的读写分离。在 5.0.0 GA 版中,Apache ShardingSphere 内核通过元数据加载,内部维护了单表的数据分布信息,并充分考虑了不同功能组合使用的场景,使得单表也能够完美支持。
5.0.0 GA 版中还有很多新功能,升级指南中的案例只是挑选了两个 GA 版本中都能够支持的一些功能进行对比,期望能够帮助大家理解新功能,并顺利地实现功能升级。如果大家对可插拔架构、Federation 执行引擎或者其他的新功能感兴趣,欢迎参考官方文档进行测试使用。
结语
历经两年时间的打磨,Apache ShardingSphere 以全新的姿态展示在大家面前,可插拔架构内核为所有的开发者提供了无限的可能性,未来,我们将基于可插拔架构内核,不断开拓新的功能,丰富 Apache ShardingSphere 生态系统。Federation 执行引擎则打开了分布式查询的大门,后续我们将专注于内存及性能的优化,为大家提供更可靠、更高效的分布式查询能力。最后,也欢迎大家能够积极地参与进来,共同推动 Apache ShardingSphere 的发展。
参考文档
 Apache ShardingSphere Release Note: Releases · apache/shardingsphere · GitHub
Apache ShardingSphere Release Note: Releases · apache/shardingsphere · GitHub
 Brand new sharding configuration API of Release 5.x: [DISCUSS] Brand new sharding configuration API of Release 5.x · Issue #5017 · apache/shardingsphere · GitHub
Brand new sharding configuration API of Release 5.x: [DISCUSS] Brand new sharding configuration API of Release 5.x · Issue #5017 · apache/shardingsphere · GitHub
 Automatic Sharding Strategies for Databases and Tables: [New API] Automatic Sharding Strategies for Databases and Tables · Issue #5937 · apache/shardingsphere · GitHub
Automatic Sharding Strategies for Databases and Tables: [New API] Automatic Sharding Strategies for Databases and Tables · Issue #5937 · apache/shardingsphere · GitHub
 从中间件到分布式数据库生态,ShardingSphere 5.x 革新变旧
从中间件到分布式数据库生态,ShardingSphere 5.x 革新变旧
 ShardingSphere X openGauss,将会产生怎样的化学反应
ShardingSphere X openGauss,将会产生怎样的化学反应
 贡献指南: 参与和贡献 :: ShardingSphere
贡献指南: 参与和贡献 :: ShardingSphere
 中文社区:
中文社区: