
场景:近期做es分组聚合统计时候发现 top n场景es统计不准确
sql:SELECT count(_id) as todayTotalOrderNum FROM vem_orderinfo_index_2021
group by pointId order by todayTotalOrderNum desc limit 200 当limit越大越精确。
ss思想:Merger Engine :: ShardingSphere
总结:感觉分片、分库分表没有一种算法有性能好,有精确的统计 微信:ppgou88 谁了解可以讨论下
问题:是否有性能高、有准确的算法思想?
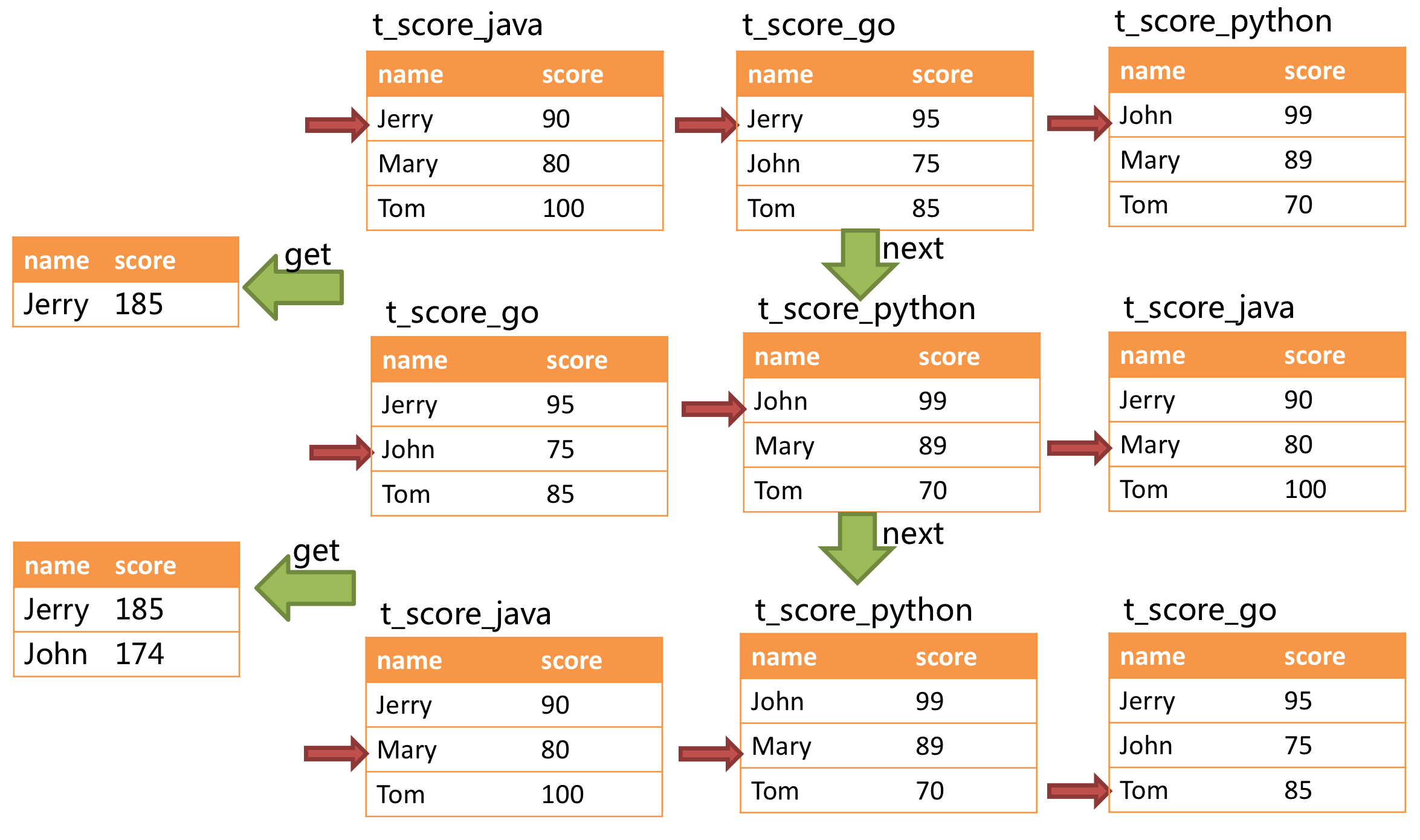
不准确原因图片:

不是特别理解不准确的原因,能否描述的再清楚些。
至于性能,目前 ShardingSphere 的解决方案性能还是挺高的,一切以实际测试结果为准,可以试一下。
分布式统计导致统计不准确。这个是算法绕不开的问题。1、要么全量计算,2、要么分片全量计算,然后全量聚合。ss看文档采用的是全量计算。不过我担心自己见识不够,是不是有其他更好的方法。华为的解决办法:https://bbs.huaweicloud.com/blogs/detail/180535
我主要不关心结果,我关心算法
单纯算法只是纸上谈兵,论文都是靠实验结果为依据的
看文档是优化的全量内存,只不过是通过stream迭代优化处理了对吧。
主要是es为啥不用这个策略,这个问题他们肯定发现了,主要他们还是为了性能。
stream 是通过游标的方式取数据,服务器压力和数据量的大小没有直接关系。
合并也是 stream 的方式去做的,每次都只从游标中获取一个数据,对内存没有影响。
es 是 map reduce 的方式,和 ShardingSphere 这种本身有序的方式是不同的。
归根结底来说, AP 和 TP 的计算方式也不同,一个面向吞吐量,一个面向延时敏感。
@stream 是通过游标的方式取数据,服务器压力和数据量的大小没有直接关系 回答:能stream的前提是每个表要把查询结果查询回来,需要内存存放这些记录吧。
不是的,那个叫 Memory 模式
@亮哥 Memory怎么做到呢?你意识你把查询结果放在mysql,然后自己stream mysql的结果集? 我感觉做不到啊。 我理解必须把每个表查询的结果集down到服务器然后才能操作。我见识不够,请详细指点。 就算你用虚拟内存、mmp内存映射方案,但是结果肯定要进来的。
你可以再看看这个文档哈,我觉得应该写清楚了。信息量大,如果文档解释不清,很难在这里两三句话说清楚
你说的是shardingjdbc还是ShardingSphere-Proxy,我立即如果数据不到应用服务器,无法操作的
使用迭代的方式,遍历result时,result中只会存一部分数据缓存,当遍历完后,result会根据位移或者其他定位逻辑拉取一部分数据,一般的处理大数据量都是这么实现的。
Note:result不只是数据的集合,是一个迭代器,有缓存和拉取数据的功能。
1 个赞
你是说limit 2147483647吗? 这个只是说要查询2147483647条记录,不代表一次性查出来,这个语句返回的resultset就是一个迭代器
你怎么迭代数据在人家mysql哪里。无法控制。
cursor 本身就有这个功能