
现状描述:项目启动后,根据用户操作,动态新增表,怎么可以将新增的表添加到 actualDataNodes 中
目前唯一的渠道是通过 Proxy 执行 DistSQL,动态修改规则。
未来我们会努力在 JDBC 中也支持 DistSQL 语句,不过这还是个远期目标,面临不少困难。
折中的办法是部署一个 Proxy 给 JDBC 访问,需要动态修改规则的 SQL,发往 Proxy 执行。
有没有办法修改规则后,自动建表?例如按月分表,我先配置了今年的,再将规则改为今年和明年,这个时候会自动创建明年的表吗
你好,我似乎也遇到了这个问题,但是我这个问题好像有些奇怪!
我使用的是自定义分表策略,通过重写StandardShardingAlgorithm类型doSharding动态的新增表和collection节点,单表可以执行任何增删改查操作不会有异常
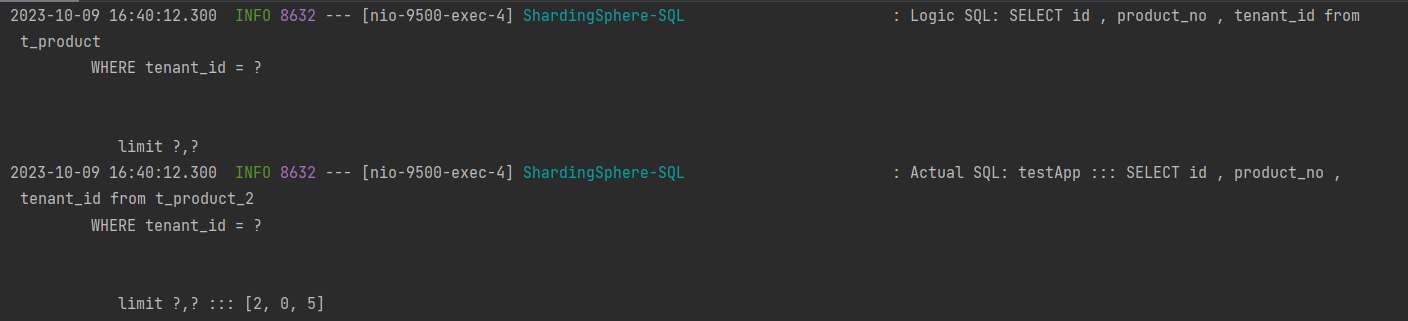
但是连接查询将遇到问题,报子表没有配置节点,我该怎么去修改呢。
@Component
@Slf4j
public class DataShardingAlgorithm implements StandardShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
return collection;
}
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
StringBuilder resultTableName = new StringBuilder();
String logicTableName = preciseShardingValue.getLogicTableName();
// 拼接的tenantId,格式为 表名_{tenant_id}
resultTableName.append(logicTableName).append("_").append(preciseShardingValue.getValue());
String newTableName = resultTableName.toString().toLowerCase();
if (!collection.contains(newTableName)) {
// 动态新增节点
ShardingAlgorithmTool.copyTable(logicTableName,newTableName);
collection.add(newTableName);
}
return newTableName;
}
@Override
public String getType() {
return null;
}
@Override
public void init(Properties properties) {
}
}
dataSources:
testApp:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/app_test
username: root
password: 123456
rules:
- !TRANSACTION
defaultType: XA
providerType: Atomikos
- !SHARDING
tables:
t_member: # 分表,逻辑表名
# 节点表添加下初始的表,后续会在新增租户的时候新增表且刷新节点
actualDataNodes: testApp.t_member
tableStrategy: # 配置分表策略
standard: # 用于单分片键的标准分片场景
shardingColumn: tenant_id
shardingAlgorithmName: real-data-inline
t_product: # 分表,逻辑表名
# 节点表添加下初始的表,后续会在新增租户的时候新增表且刷新节点
actualDataNodes: testApp.t_product
tableStrategy: # 配置分表策略
standard: # 用于单分片键的标准分片场景
shardingColumn: tenant_id
shardingAlgorithmName: real-data-inline
t_order: # 分表,逻辑表名
# 节点表添加下初始的表,后续会在新增租户的时候新增表且刷新节点
actualDataNodes: testApp.t_order
tableStrategy: # 配置分表策略
standard: # 用于单分片键的标准分片场景
shardingColumn: tenant_id
shardingAlgorithmName: real-data-inline
t_order_item: # 分表,逻辑表名
# 节点表添加下初始的表,后续会在新增租户的时候新增表且刷新节点
actualDataNodes: testApp.t_order_item
tableStrategy: # 配置分表策略
standard: # 用于单分片键的标准分片场景
shardingColumn: tenant_id
shardingAlgorithmName: real-data-inline
# 分片算法配置
shardingAlgorithms:
real-data-inline: # 分片算法名称
type: CLASS_BASED #自定义策略
props:
strategy: standard
# 包名+类名
algorithmClassName: com.hcyl.cloud.test.utils.DataShardingAlgorithm
bindingTables:
- t_member,t_product,t_order,t_order_item
props:
sql-show: true
mode:
type: Standalone
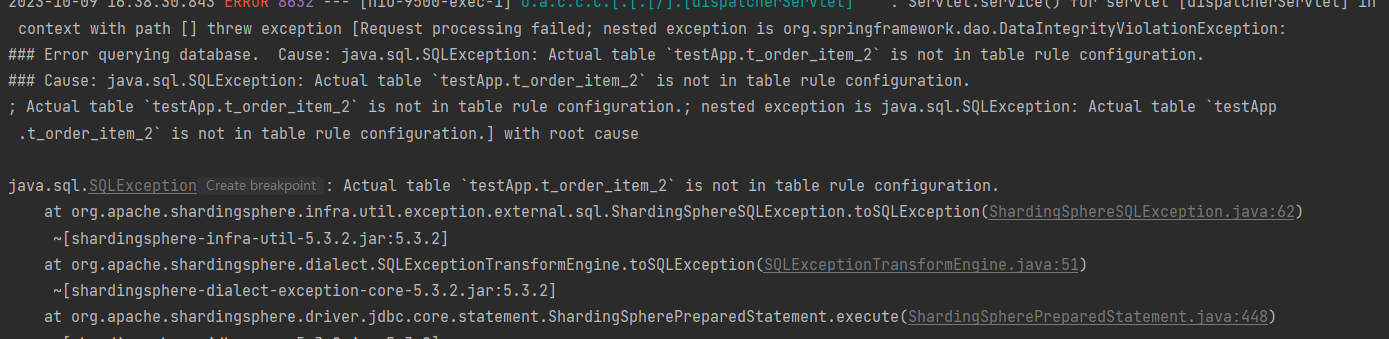
但是如果我把全部节点配置上 将不会出现这个异常,为什么单表似乎可以自己加载节点呢,我有其他的办法去实现这个东西吗
您好,这个问题解决了吗,我尝试在某个实例上创建并刷新了doSharding方法的availableTargetNames集合,但是无法解决多节点同步的问题