
本文译自 ShardingSphere PMC 潘娟发表于 InfoQ 海外技术文章 “Creating a Secure Distributed Database Cluster Leveraging Your Existing Database Management System”。
背景
十年来,数据业务增长速度前所未有、势头强劲,数据业务的指数级增长引领我们步入了大数据时代:移动应用、社交网络、客户数据库、物联网设备……可以说,大数据无处不在。大数据的面世同样意味着我们应将注意力集中于掌握新兴科技、接受全新挑战、学习新的技能,着力跟上全新数据库技术开发的步伐。
目前,面对创新数据库解决方案,所谓“传统型数据库”逐渐式微。当数据湖成为大数据首选存储方案之后,建立在关系型数据库(传统数据库)基础上的传统数据仓库只能存储结构化数据,传统数仓只能苦苦挣扎。而通常来说,数据湖往往是基于 Hadoop 集群、NoSQL 数据库来实现的。
本文将探讨在互联网成为主流之后,大数据为现代企业数据库应用带来了哪些挑战,并针对数据分布和安全问题为读者呈现解决方案思路和实操指南。
由于数据分布和安全与大数据的各个领域都息息相关,人们不由自主地会联想到可能使用到的数据库数量。简而言之,本文着眼于如何使用安全的分布式特性升级 MySQL、PostgreSQL、SQL Server 等传统型数据库。这一解决方案可以将数据库集群转换为分布式分片系统,并通过数据加密、流量治理等功能进行增强。此外,更新迁移数据库集群还可提升性价比。
通过阅读本篇文章,你将会了解到
了解大数据的五大特征,以及大数据为数据库带来的改变和挑战;
学习如何解决大数据所带来的挑战,让传统关系型数据库焕新与重生;
了解一种适用于任意数据库的全新技术理念 Database Plus,从而消除转换成本、避免供应商锁定;
利用 Apache ShardingSphere 开源生态轻松创建分布式加密数据库;
学习如何使用 Aurora 数据库作为存储节点,同时使用 ShardingSphere 作为运行在 EC2 的计算节点,在 AWS 上建立一个分布式数据库。
大数据给数据库带来的挑战
实操之前,我们需要了解大数据的五大特征及其带来的挑战:
-
数量大: 海量的数据导致用户难以从中抽取出有价值的信息并进行有效管理和应用;
-
种类多: 数据类型广泛,包括结构化数据、非结构化数据、混合型数据等众多类型;
-
速度快: 互联网流量爆发导致业务所产生的数据体量快速增长;
-
准确性: 决定企业进行业务决策时的底气及其发展前景;
-
价值高: 数据累计分析提供了新的机遇,有助于企业挖掘全新业务市场和产品、做出更明智的决策。
上述五大特征中,“准确性”和“价值高”与数据分析的相关度更高,因此不作为本文的讨论重点。针对前三个特征,多数跨行业企业纷纷在探寻以下问题的解决方案:
-
如何存储及高效管理空前的数据量?
-
如何灵活扩展数据库实例?
-
针对多个来源的数据整合为一条结果的情况,如何同时管理结构化和非结构化数据?
-
在在线系统中,如何在重构量最低的前提下保护用户隐私?
针对上述问题的解决方案有很多,例如寻找新的数据库供应商、开发中间件或插件等。不过对于正在使用或考虑使用传统开源数据库管理系统的用户来说,可以参考下文所描述的方法来对原有系统进行演进,或者利用传统 DBMS 创建一个安全的分布式数据库系统。而倾向于使用 PostgreSQL、MySQL、RDS 的用户可直接应用以下步骤。
架构介绍
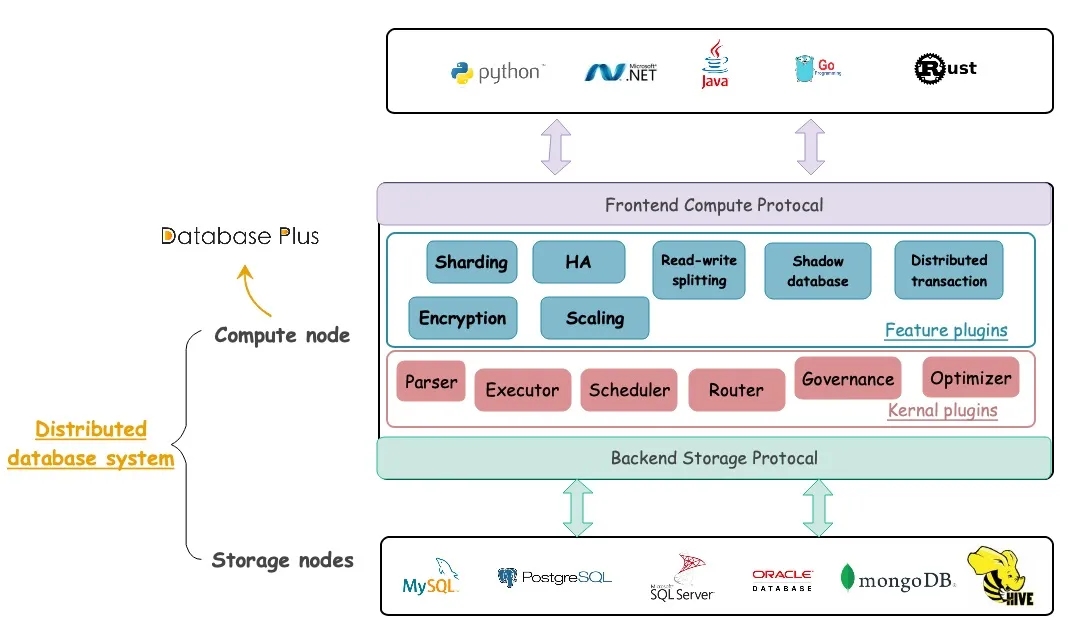
Apache ShardingSphere 作为一款开源分布式数据库生态项目,可以将任意数据库转换为分布式数据库系统,并通过数据分片、弹性伸缩、加解密等特性提供增强功能。
从项目定义不难看出,ShardingSphere 用于将现有数据库转换为分布式数据库,提供诸多功能强大的特性,最终提升新系统的性能。
操作步骤也非常简单,你只需要将该项目引入数据库系统(以此创建一个分片式数据库系统),按需灵活进行扩容,加密数据以保护隐私即可。下图为上述架构的直观概述。
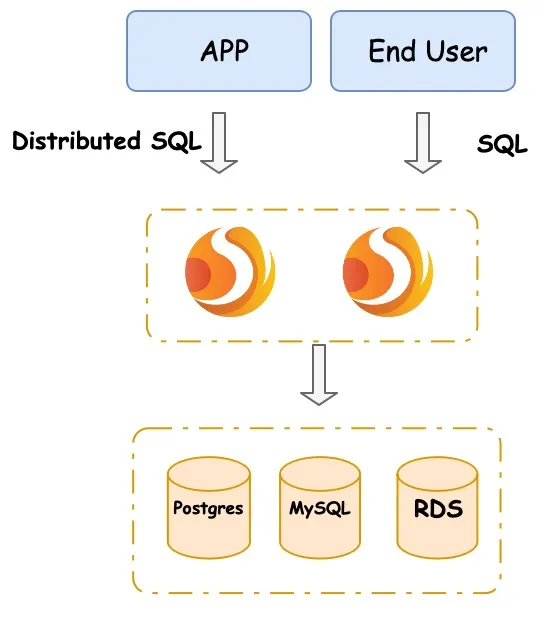
如上图所示,我们的分布式数据库系统由 Apache ShardingSphere(此处为 ShardingSphere-Proxy)组成,位于应用程序和 MySQL、PostgreSQL、Aurora 或任何其他 SQL92 数据库之间。
在该系统中,ShardingSphere 作为计算节点接收用户请求,而数据库作为存储节点存储数据并执行部分本地计算的工作。连接的应用程序将向 ShardingSphere 发送查询,其方式与向 DBMS 发送查询相同。
传统意义上,SQL 的功能主要是用于查询数据库。但是由于我们的分布式数据库系统中增加了众多新功能(如弹性伸缩、加密、SQL 审计),对于用户来说也需要一种类似 SQL 的语言来快速操作这些新功能。
为满足这一要求,同时避免制造新的障碍或增加学习难度,该项目使用分布式 SQL(DistSQL)实现无缝过渡。用户只需登录 ShardingSphere,输入 SQL 和 DistSQL 就可以创建一张分片表、加密表或启动一个扩缩容作业。下文将集中展示这一神奇之处。
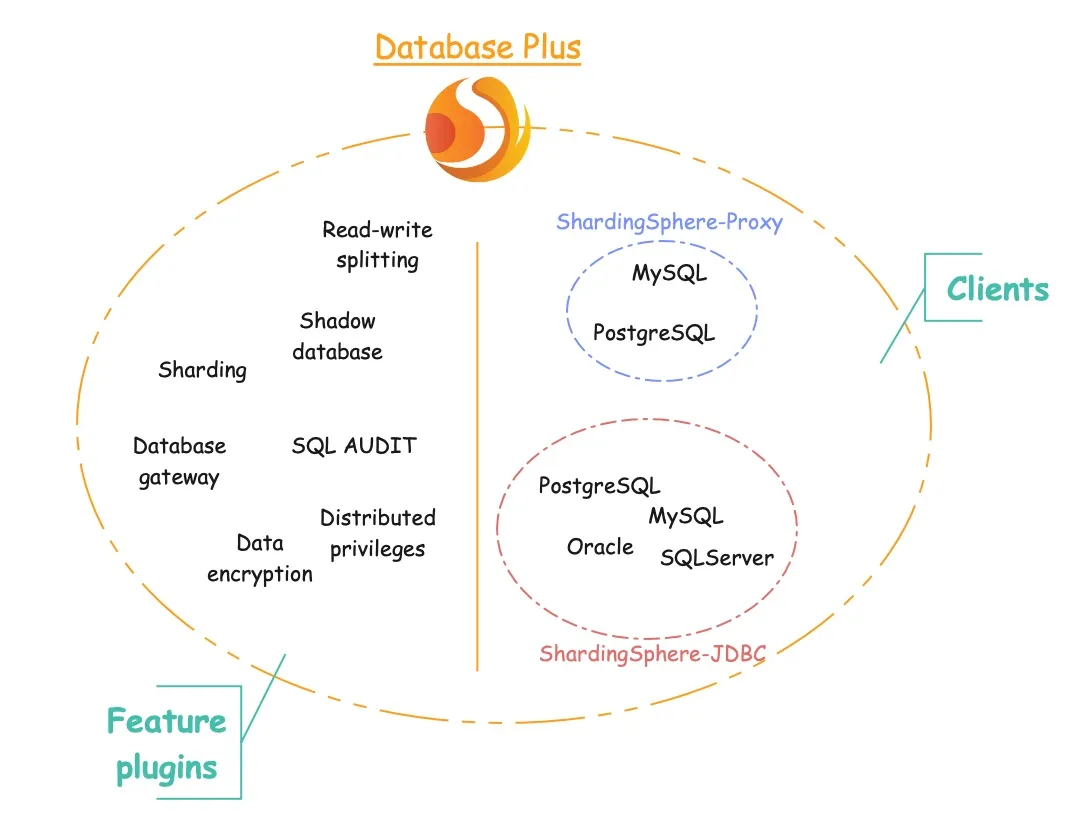
(ShardingSphere 深度概览)
如上图所示,ShardingSphere 不仅作为分布式数据库系统中的计算节点,还包含一系列功能强大的特性以及 ShardingSphere-Proxy 和 ShardingSphere-JDBC 两个客户端。
Database Plus
Database Plus 是 Apache ShardingSphere 项目的设计理念,理念核心为分布式数据库系统,而不仅仅包含数据分片。
Database Plus 旨在碎片化的异构数据库上层构建标准层和生态,提供统一的 SQL 操作服务,最大化减少数据库之间的差异。在该理念下,应用程序与标准化服务进行连接,不需要为匹配不同的数据库进行调整。ShardingSphere 利用传统的 DBMS 和 NoSQL 数据库(计划中)为终端用户提供标准化数据库服务。
功能插件
Database Plus 中“功能插件”一词指所有功能既可以单独使用,也能够并发运行。
ShardingSphere 目前提供数据分片、读写分离、数据库网关、加解密、分布式事务、影子库等功能。此外,Database Plus 基于数据库系统,具备灵活适配且可插拔的特性,用户使用多功能插件时更为简单。
客户端
系统包含 ShardingSphere-Proxy 与 ShardingSphere-JDBC 两个客户端,支持独立或混合部署。
-
ShardingSphere-Proxy 的定位为透明化的数据库代理,也可作为数据库服务器,且应独立部署于服务器。目前支持使用 MySQL 与 PostgreSQL。
-
ShardingSphere-JDBC 定位为轻量级 Java 框架,扩展了 Java JDBC 层,可集成到 JDBC 应用程序中。
目前上述两个客户端支持混合部署,ShardingSphere-JDBC 充当高性能驱动,ShardingSphere-Proxy 则作为管理客户端。
如何利用 DBMS 构建安全的分布式数据库集群
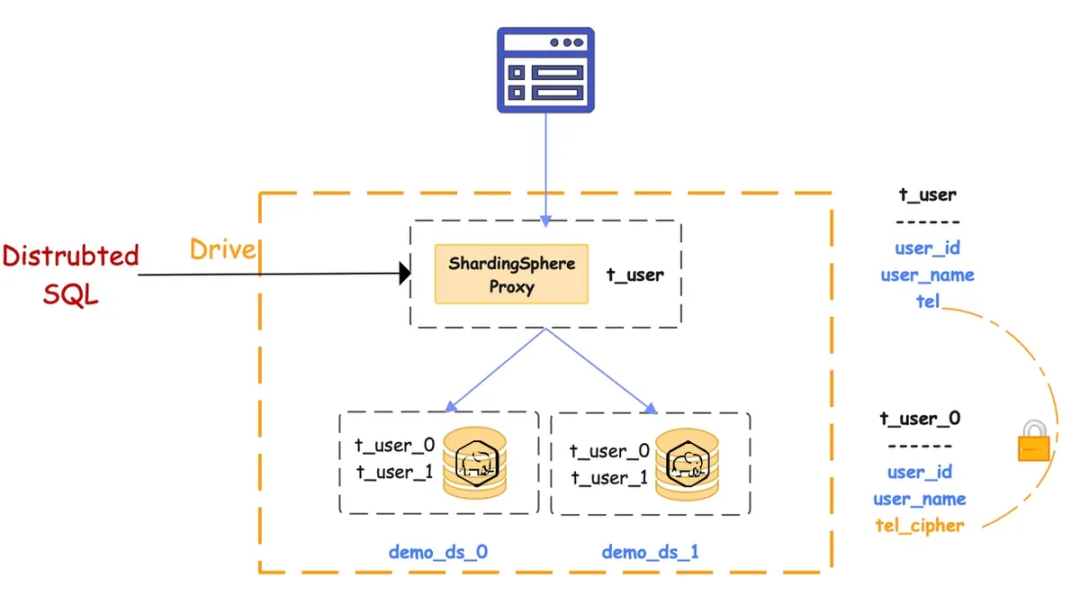
对架构有全面了解之后,下文将详细展示如何构建一个安全的分片式 Aurora 数据库系统。我们会使用 ShardingSphere 的分片插件、数据加密插件以及 ShardingSphere-Proxy + PostgreSQL 来构建一个分布式数据库系统。整体结构如下图所示:
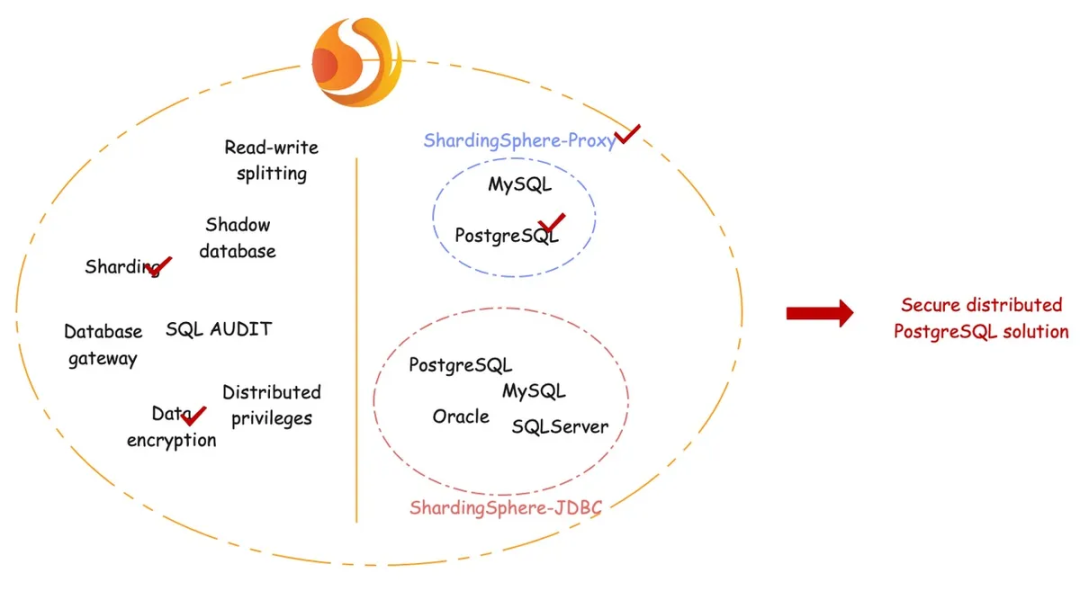
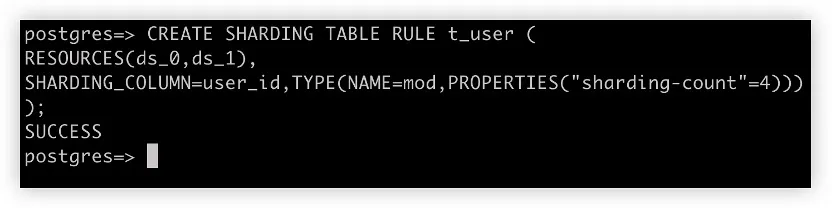
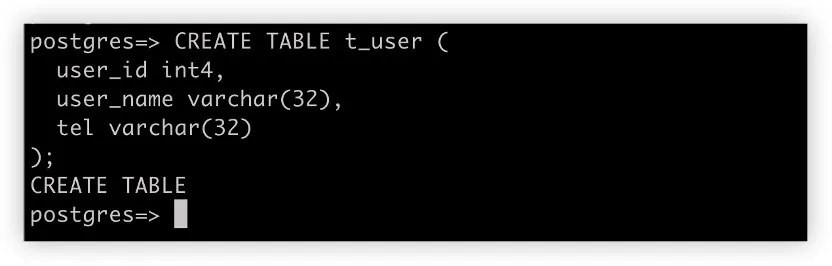
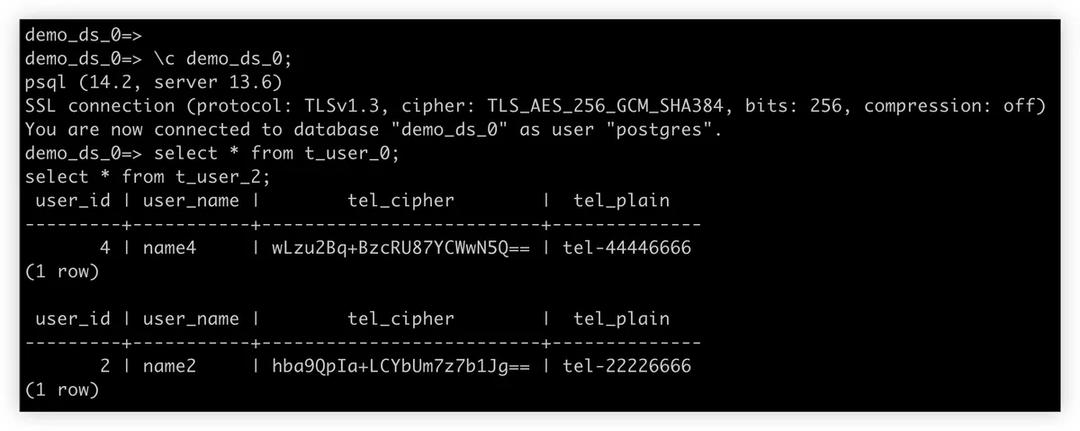
应用将 ShardingSphere + PostgreSQL 实例看作为一个分布式数据库,同等看待 ShardingSphere 和 PostgreSQL。从用户角度来看,只有一个逻辑表 t_user。但是,该表由 t_user_0 到 t_user_3 共四个实际表组成,位于两个不同的 PostgreSQL 实例中。
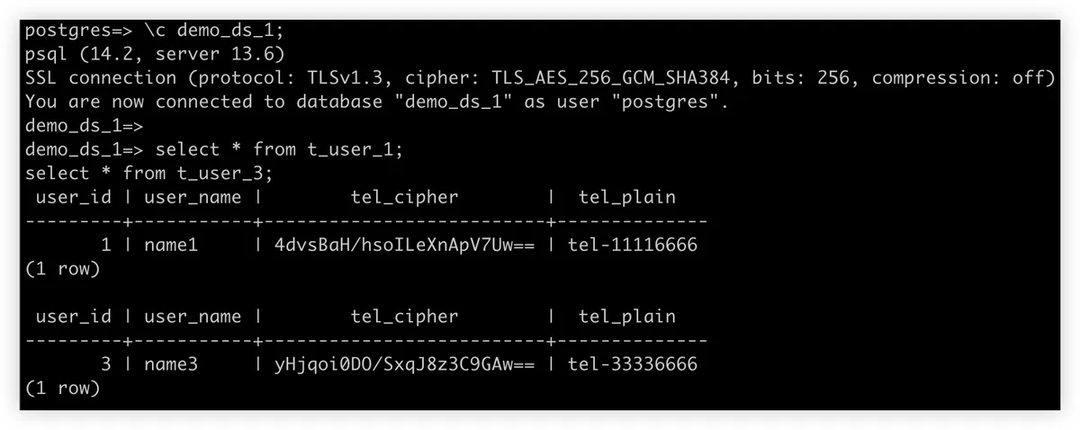
逻辑表 t_user 内有一个存储用户手机号码的列 *tel,*由于手机号码为敏感数据,必须加密后存储于数据库。在此过程中,实际表会创建两个列 tel cipher 和 tel plain,存储对应的明文和密文(这一步可有可无,此处仅用于展示)。
该生态系统的用户友好性体现在,用户无需关注实际表中的列,也不需要知道如何将逻辑列映射到实际列。用户只需使用逻辑列和明文数据构造自己的 SQL 语句,ShardingSphere 即会完成数据分片的全部过程,且自动对数据进行加解密。
在这个过程中,ShardingSphere-Proxy 会在后台执行所有步骤,这大大简化了用户操作难度。用户只需要用逻辑列 tel 处理逻辑表 t_user 即可。不过在运行 SQL 查询之前,用户需要指引 ShardingSphere 如何进行分片和数据加密。
详细指南
以下演示在 AWS 上执行,使用 Aurora 数据库作为存储节点,ShardingSphere 作为计算节点在 EC2 运行。
-
为 ShardingSphere-Proxy 创建 EC2
-
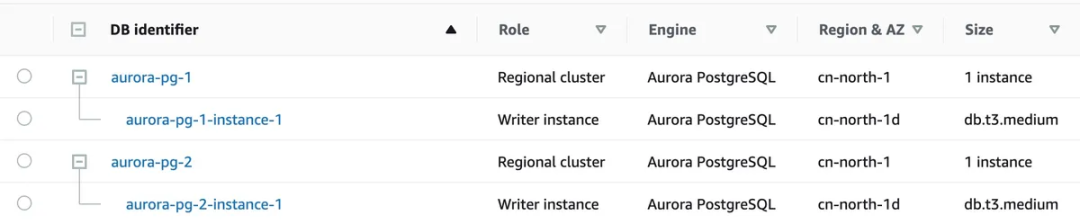
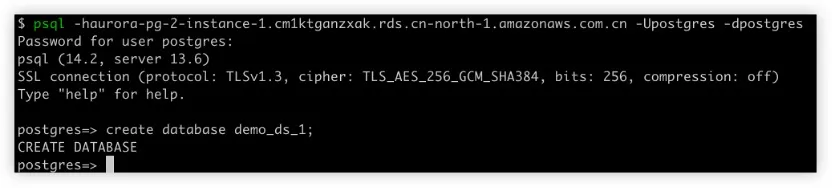
创建 Aurora 数据库



-
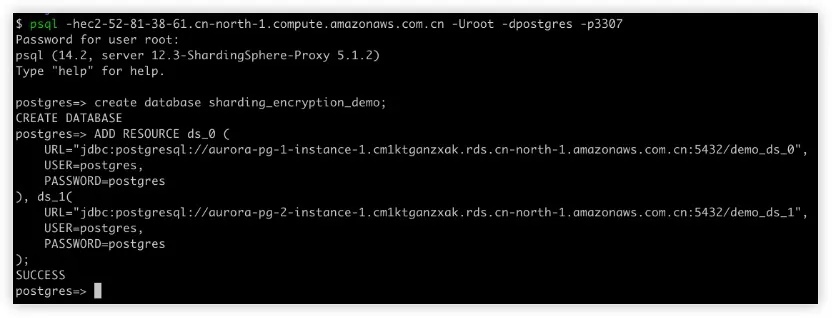
部署 ShardingSphere-Proxy
-
登录 ShardingSphere-Proxy
-
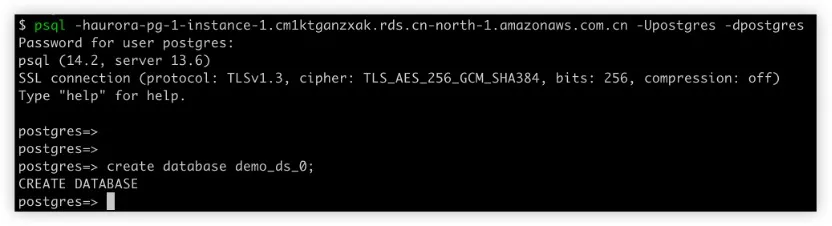
初始化 Aurora 数据库
-
通过 SQL 和 DistSQL 用加密和分片规则初始化 ShardingSphere
-
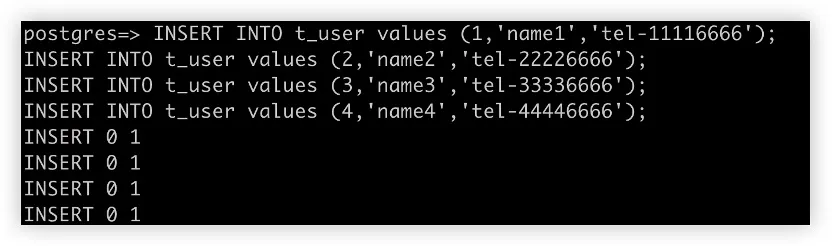
在 ShardingSphere-Proxy 上插入测试行
-
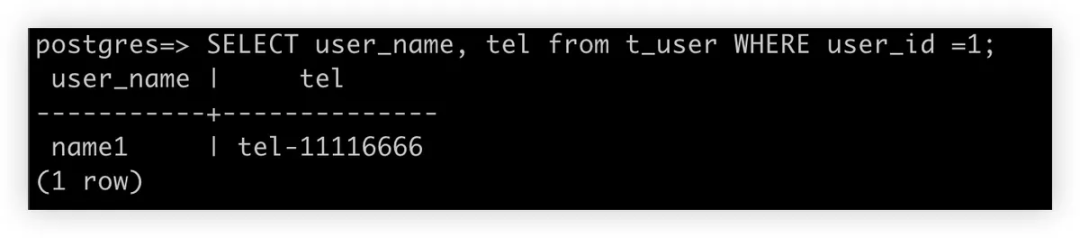
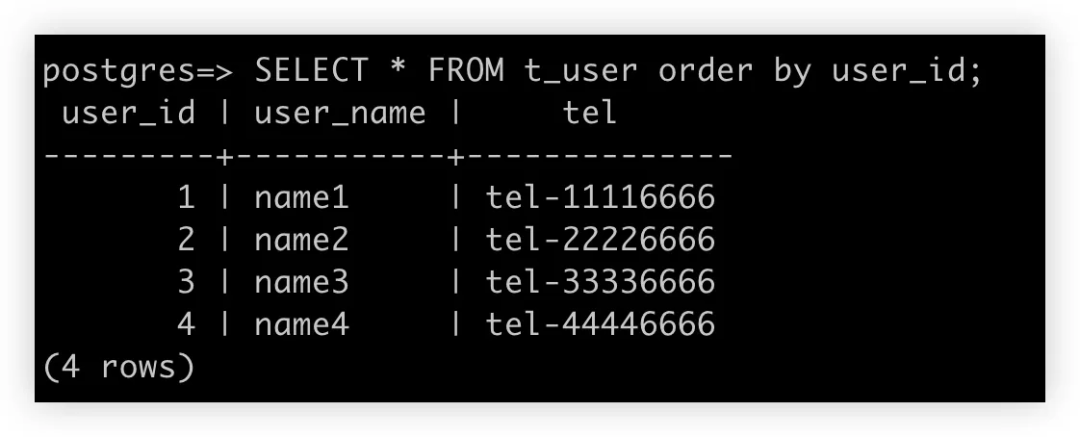
运行测试查询 SQL
-
检查 Aurora 数据库中的实际数据


本文聚焦于使用 ShardingSphere 在 Aurora 上创建安全的分布式数据库,同时提供了增加更多功能的可能性。这份操作指南同样适用于 ShardingSphere 在其它支持的数据库类型下作为分布式数据库的存储节点。开源的强大之处在于你会发现类似的问题可能还有很多解决方案,笔者希望读者可以找到最适合自身业务环境的解决方案。
目前上述两个客户端支持混合部署,ShardingSphere-JDBC 充当高性能驱动,ShardingSphere-Proxy 则作为管理客户端。
总结
大数据和数据湖的出现不一定意味着关系型数据库的没落,两者可以共存,只是关系型数据库需要进行调整。针对这次过渡,我们提出了 Database Plus 理念(一种适用于任意数据库的全新技术理念),帮助用户解决上述挑战,消除转换成本、避免供应商锁定,在后续的文章中我们将介绍如何轻松创建一个分布式加密数据库。
原文链接:Creating a Secure Distributed Database Cluster Leveraging Your Existing Database Management System