
本节将演示如何使用 ShardingSphere 和 PostgreSQL RDS 创建分布式 PostgreSQL 数据库,以及用户如何对两个 PostgreSQL 实例进行数据分片。以下演示过程中,ShardingSphere-Proxy 运行于 Kubernetes;PostgreSQL RDS 运行于 AWS,部署架构如下图所示。
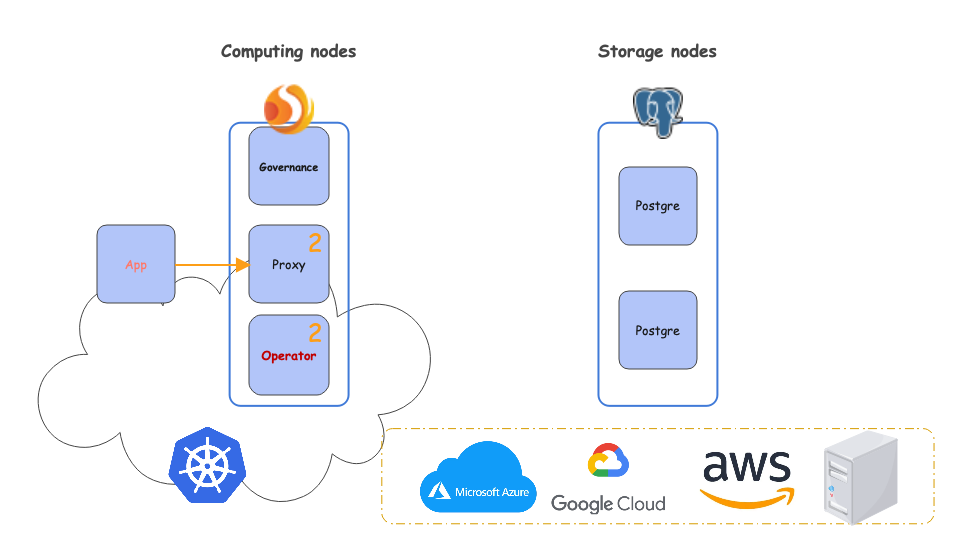
演示主要包含以下内容:
-
部署 ShardingSphere-Proxy 集群和 ShardingSphere-Operator。
-
使用 DistSQL 构建分布式数据库表。
-
测试 ShardingSphere-Proxy 集群(计算节点)的弹性伸缩能力和高可用。
1. 准备数据库 RDS
在 AWS 或任意云上创建两个 PostgreSQL RDS 实例作为存储节点。
2. 部署 ShardingSphere-Operator
下载 repo,在 Kubernetes 上创建一个名为 sharding-test 的命名空间。
git clone https://github.com/apache/shardingsphere-on-cloud
kubectl create ns sharding-test
cd charts/shardingsphere-operator
helm dependency build
cd ../
helm install shardingsphere-operator shardingsphere-operator -n sharding-test
cd shardingsphere-operator-cluster
vim values.yaml
helm dependency build
cd ..
helm install shardingsphere-cluster shardingsphere-operator-cluster -n sharding-test
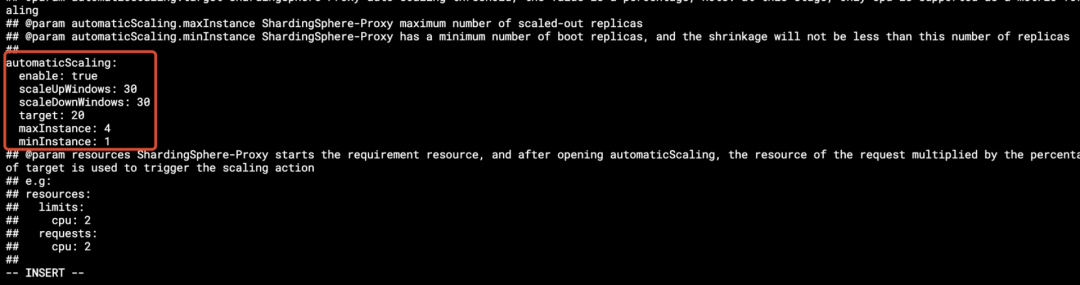
修改并部署 shardingsphere-operator-cluster 的 values.yaml 中的 automaticScaling: true 和 proxy-frontend-database-protocol-type: PostgreSQL。

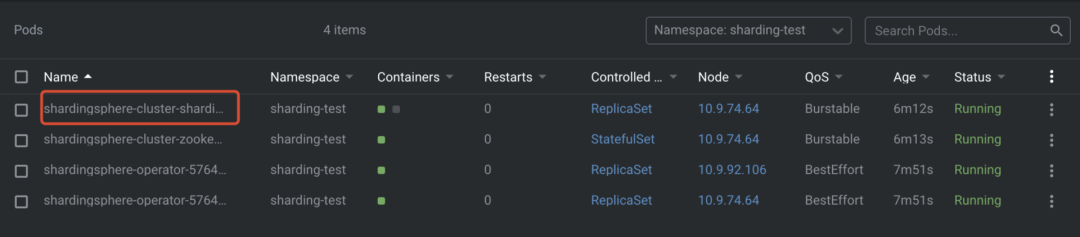
以上操作会创建一个 ShardingSphere-Proxy 集群,其中包含 1 个 Proxy 实例、2 个 Operator 实例和 1 个 Proxy 治理实例,如下所示:
3. 使用 DistSQL 创建分片表
(1) 登录 ShardingSphere-Proxy 并添加 PostgreSQL 实例。
kubectl port-forward --namespace sharding-test svc/shardingsphere-cluster-shardingsphere-operator-cluster 3307:3307
psql --host 127.0.0.1 -U root -p 3307 -d postgres

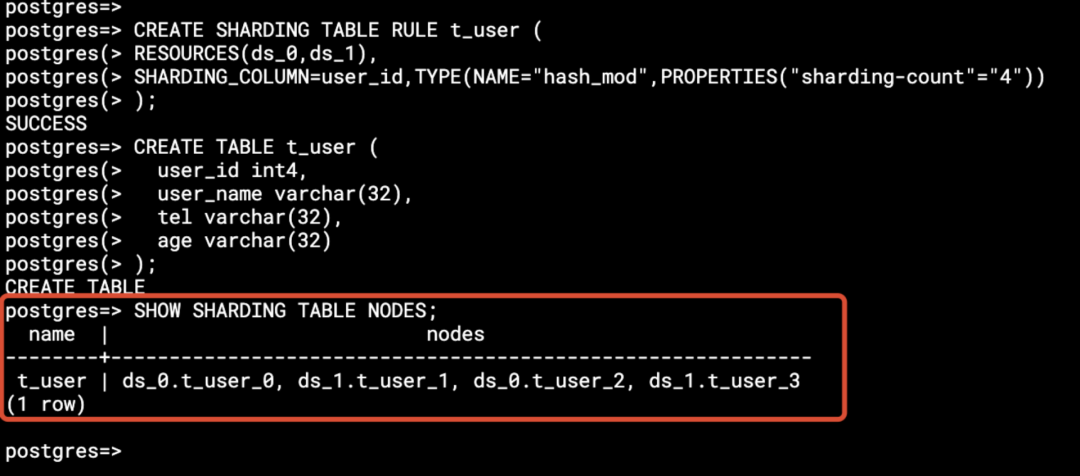
(2) 执行 DistSQL,用 MOD(user_id, 4)创建一个分片表 t_user,显示这个逻辑表 t_user 的实际表。
(3) 插入测试行,在 ShardingSphere-Proxy 上执行查询,得出最终合并结果。
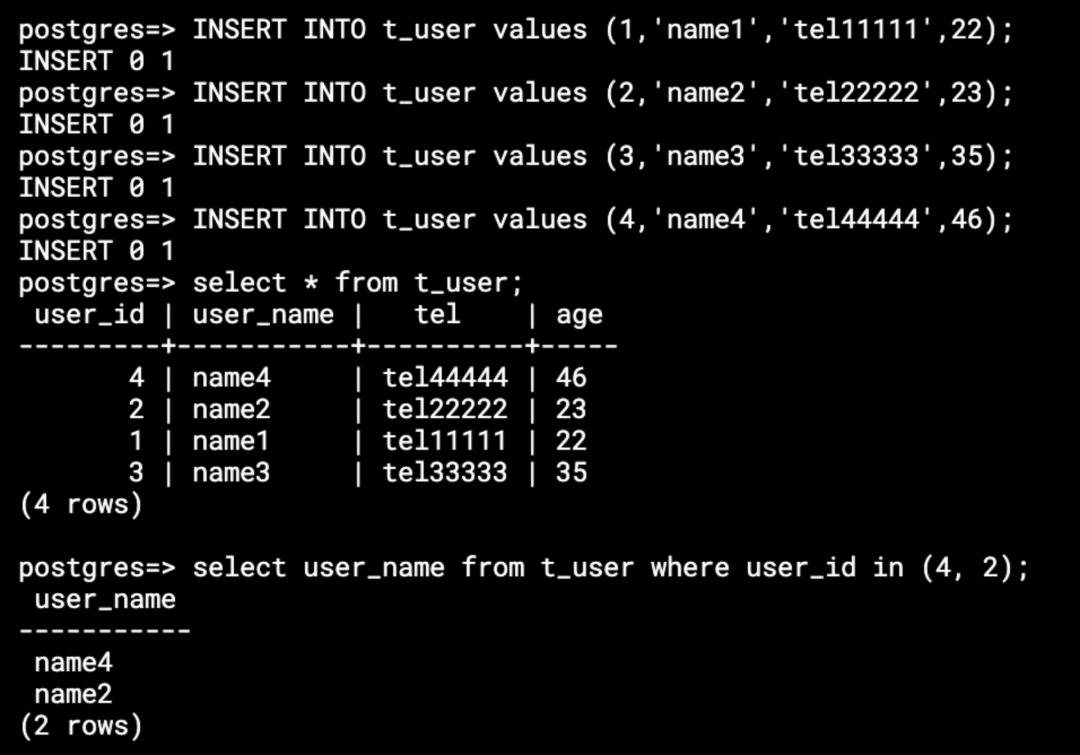
(4) 登录到两个 PostgreSQL 实例以获取它们的本地结果。
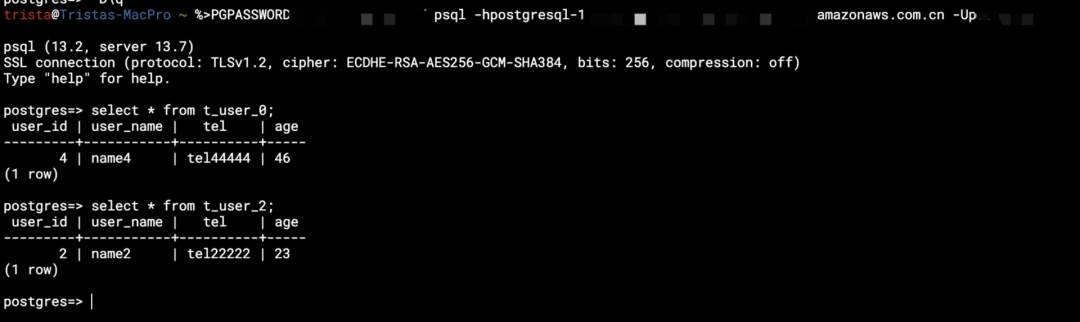
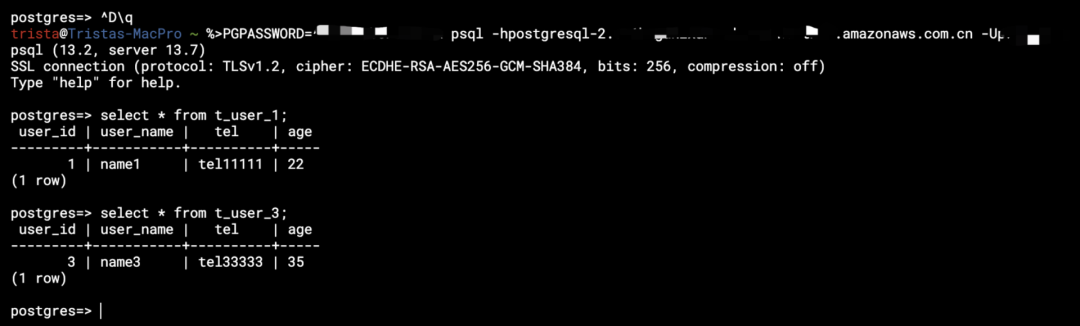
以上测试有助于理解 ShardingSphere 管理和分片数据库的功能,用户无需关注不同分片中的单个数据。
4. 测试 ShardingSphere-Proxy 集群(计算节点)的伸缩和高可用
如果用户认为新系统的 TPS 或 QPS 太高,可以考虑升级整个分布式数据库系统的计算能力。相较于其它分布式数据库系统,ShardingSphere-Proxy 增加计算节点的方式最为简单。ShardingSphere-Operator 能够基于 CPU 指标确保 ShardingSphere-Proxy 的可用性和弹性伸缩。此外,还可通过修改参数进行扩容或缩容,如下图所示:
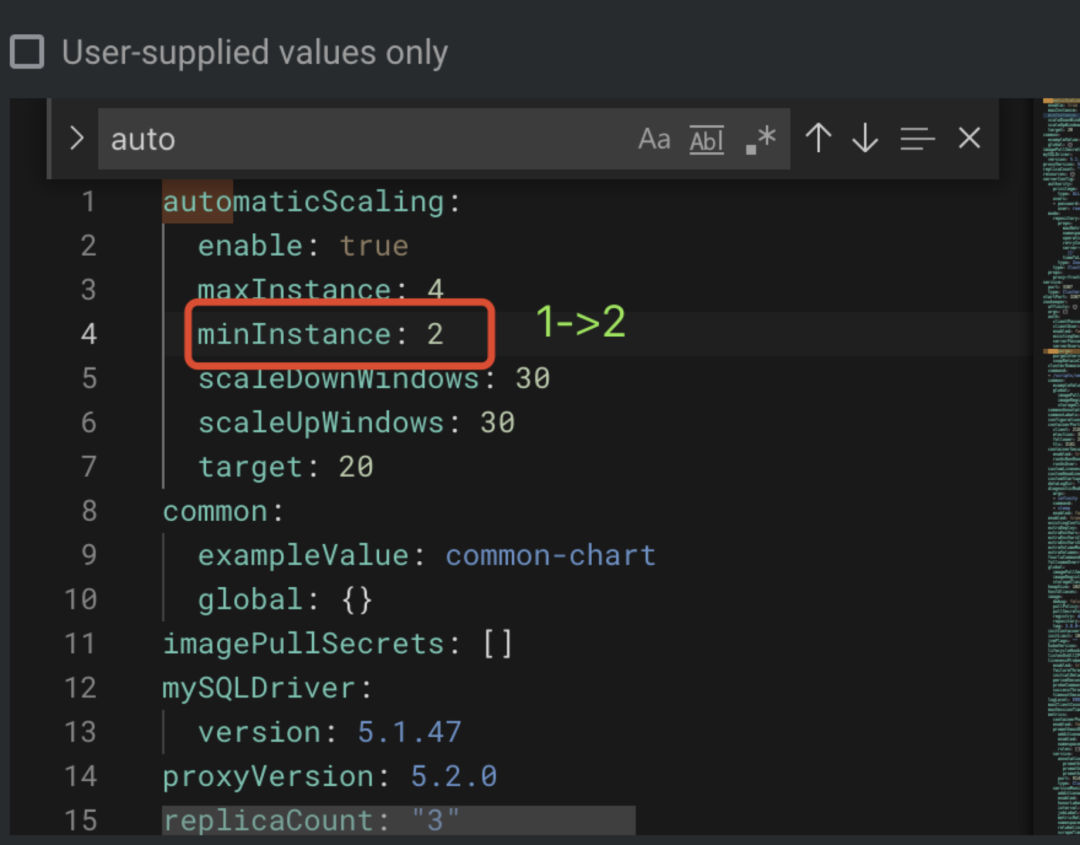
升级完成后用户将会获取两个 ShardingSphere-Proxy 实例,表明计算能力得到了增强。
如上,若用户需要更多的存储容量,可以采取以下步骤:
-
在云端或本地部署启动额外的 PostgreSQL 实例;
-
将新的存储节点添加到 ShardingSphere-Proxy 中;
-
运行 DistSQL,使用 ShardingSphere 进行重新分片。
小结
本文聚焦 Kubernetes 上的一种全新分片数据库架构,利用分布式数据库存算分离的架构,借助现有单体数据库帮运维团队高效流畅地将数据库基础设施转化为现代数据库的分布式系统。通过在 Kubernetes 重新解读和应用分布式数据库计算存储分离这种传统架构,解决了有状态数据库在 Kubernetes 上的部署、治理、使用等问题。
如今,分布式数据库、云计算、开源、大数据、数字化转型都是热门概念。这些热词传递了新概念、新想法和新方案,对解决生产问题、满足生产需求大有裨益。但毕竟世界上没有完美的方案,我们要善于接受新的思想、通过权衡优劣、依据用户独特的场景需要选出最适合自己的方案才是技术选型的王道。
潘娟,SphereEx 联合创始人 & CTO、Apache Member & Incubator Mentor、Apache ShardingSphere PMC、AWS Data Hero、腾讯云 TVP、中国木兰开源社区导师。
参考资料
[1] Database As A Service Providers Market Size, Share, Trends & Forecast
[2] Extending Kubernetes | Kubernetes
[3] https://shardingsphere.apache.org/document/current/en/overview/
[4] GitHub - apache/shardingsphere-on-cloud: ShardingSphere on Cloud
论『Kubernetes』环境下的数据库发展(下篇)内容已结束~
那就跟着本篇的实践指南,高效、快速开启自己对 ShardingSphere 的应用吧!
欢迎大家积极留言! 
我们将继续分享关于 ShardingSphere 的强大功能应用与其背后有趣的技术实践~