


唐国城
小米软件工程师,主要负责 MIUI 浏览器服务端研发工作。热爱开源,热爱技术,喜欢探索,热衷于研究学习各种开源中间件,很高兴能参与到 ShardingSphere 社区建设中,希望在社区中努力提高自己,为 ShardingSphere 社区的发展做更多的工作。
元数据在 ShardingSphere 中加载的过程
一、概述
元数据是表示数据的数据。从数据库角度而言,则概括为数据库的任何数据都是元数据,因此如列名、数据库名、用户名、表名等以及数据自定义库表存储的关于数据库对象的信息都是元数据。而 ShardingSphere 中的核心功能如数据分片、加解密等都是需要基于数据库的元数据生成路由或者加密解密的列实现,由此可见元数据是 ShardingSphere 系统运行的核心,同样也是每一个数据存储相关中间件或者组件的核心数据。有了元数据的注入,相当于整个系统有了神经中枢,可以结合元数据完成对于库、表、列的个性化操作,如数据分片、数据加密、SQL 改写等。
而对于 ShardingSphere 元数据的加载过程,首先需要弄清楚在 ShardingSphere 中元数据的类型以及分级。在 ShardingSphere 中元数据主要围绕着 ShardingSphereMetaData 来进行展开,其中较为核心的是 ShardingSphereSchema。该结构是数据库的元数据,同时也为数据源元数据的顶层对象,在 ShardingSphere 中数据库元数据的结构如下图。对于每一层来说,上层数据来源于下层数据的组装,所以下面我们采用从下往上的分层方式进行逐一剖析。
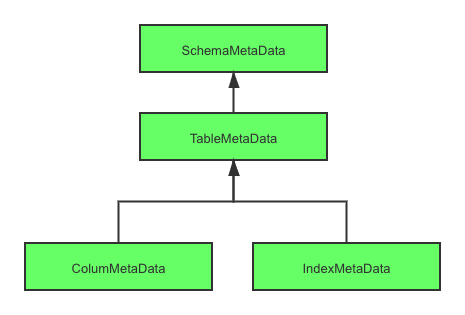
ShardingSphere 数据库元数据结构图
二、ColumMetaData 和 IndexMetaData
ColumMetaData 和 IndexMetaData 是组成 TableMetaData 的基本元素,下面我们分开讲述两种元数据的结构以及加载过程。ColumMetaData 主要结构如下:
public final class ColumnMetaData {
// 列名
private final String name;
// 数据类型
private final int dataType;
// 是否主键
private final boolean primaryKey;
// 是否自动生成
private final boolean generated;
// 是否区分大小写
private final boolean caseSensitive;
}
其加载过程主要封装在 org.apache.shardingsphere.infra.metadata.schema.builder.loader.ColumnMetaDataLoader#load方法中,主要过程是通过数据库链接获取元数据匹配表名加载某个表名下所有的列的元数据。核心代码如下:
/**
* Load column meta data list.
*
* @param connection connection
* @param tableNamePattern table name pattern
* @param databaseType database type
* @return column meta data list
* @throws SQLException SQL exception
*/
public static Collection<ColumnMetaData> load(final Connection connection, finalString tableNamePattern, final DatabaseType databaseType) throws SQLException {
Collection<ColumnMetaData> result = new LinkedList<>();
Collection<String> primaryKeys = loadPrimaryKeys(connection, tableNamePattern);
List<String> columnNames = new ArrayList<>();
List<Integer> columnTypes = new ArrayList<>();
List<String> columnTypeNames = new ArrayList<>();
List<Boolean> isPrimaryKeys = new ArrayList<>();
List<Boolean> isCaseSensitives = new ArrayList<>();
try (ResultSet resultSet = connection.getMetaData().getColumns(connection.getCatalog(), connection.getSchema(), tableNamePattern, "%")) {
while (resultSet.next()) {
String tableName = resultSet.getString(TABLE_NAME);
if (Objects.equals(tableNamePattern, tableName)) {
String columnName = resultSet.getString(COLUMN_NAME);
columnTypes.add(resultSet.getInt(DATA_TYPE));
columnTypeNames.add(resultSet.getString(TYPE_NAME));
isPrimaryKeys.add(primaryKeys.contains(columnName));
columnNames.add(columnName);
}
}
}
try (Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery(generateEmptyResultSQL(tableNamePattern, databaseType))) {
for (int i = 0; i < columnNames.size(); i++) {
isCaseSensitives.add(resultSet.getMetaData().isCaseSensitive(resultSet.findColumn(columnNames.get(i))));
result.add(new ColumnMetaData(columnNames.get(i), columnTypes.get(i), isPrimaryKeys.get(i),
resultSet.getMetaData().isAutoIncrement(i + 1), isCaseSensitives.get(i)));
}
}
return result;
}
IndexMetaData 其实是表中的索引的名称,所以没有复杂的结构属性,只有一个名称,所以不展开赘述,重点讲述一下加载过程。加载过程和 column 类似,主要流程在org.apache.shardingsphere.infra.metadata.schema.builder.loader.IndexMetaDataLoader#load方法中,基本流程同样也是通过数据库链接获取相关数据库和表的元数据中的 indexInfo 组织核心的 IndexMetaData,实现代码如下:
publicstatic Collection<IndexMetaData> load(final Connection connection, final String table)throws SQLException {
Collection<IndexMetaData> result = new HashSet<>();
try (ResultSet resultSet = connection.getMetaData().getIndexInfo(connection.getCatalog(), connection.getSchema(), table, false, false)) {
while (resultSet.next()) {
String indexName = resultSet.getString(INDEX_NAME);
if (null != indexName) {
result.add(new IndexMetaData(indexName));
}
}
} catch (final SQLException ex) {
if (ORACLE_VIEW_NOT_APPROPRIATE_VENDOR_CODE != ex.getErrorCode()) {
throw ex;
}
}
return result;
}
三、TableMetaData
该类型是组成 ShardingSphereMetaData 的基本元素,其结构如下:
public final class TableMetaData {
// 表名
private final String name;
// 列元数据
private final Map<String, ColumnMetaData> columns;
// 索引元数据
private final Map<String, IndexMetaData> indexes;
//省略一些方法
}
从上述结构可以看出,TableMetaData 其实是由 ColumnMetaData 和 IndexMetaData 组装而来,所以 TableMetaData 的加载过程可以理解为是一个中间层,具体的实现还是 ColumnMetaDataLoader 和 IndexMetaDataLoader 拿到表名以及相关链接进行数据加载。所以比较简单的 TableMetaData 加载过程主要在org.apache.shardingsphere.infra.metadata.schema.builder.loader.TableMetaDataLoader#load方法,其加载的核心流程如下:
publicstatic Optional<TableMetaData> load(final DataSource dataSource, final String tableNamePattern, final DatabaseType databaseType)throws SQLException {
// 获取链接
try (MetaDataLoaderConnectionAdapter connectionAdapter = new MetaDataLoaderConnectionAdapter(databaseType, dataSource.getConnection())) {
// 根据不同的数据库类型,格式化表名的模糊匹配字段
String formattedTableNamePattern = databaseType.formatTableNamePattern(tableNamePattern);
// 加载ColumnMetaData和IndexMetaData组装TableMetaData
return isTableExist(connectionAdapter, formattedTableNamePattern)
? Optional.of(new TableMetaData(tableNamePattern, ColumnMetaDataLoader.load(
connectionAdapter, formattedTableNamePattern, databaseType), IndexMetaDataLoader.load(connectionAdapter, formattedTableNamePattern)))
: Optional.empty();
}
}
四、SchemaMetaData
经过下两层的分析,很明显这一层是元数据暴露的最外层,最外的层的结构为 ShardingSphereSchema,其主要结构为:
/**
* ShardingSphere schema.
*/
@Getter
public final class ShardingSphereSchema {
private final Map<String, TableMetaData> tables;
@SuppressWarnings("CollectionWithoutInitialCapacity")
public ShardingSphereSchema() {
tables = new ConcurrentHashMap<>();
}
publicShardingSphereSchema(final Map<String, TableMetaData> tables){
this.tables = new ConcurrentHashMap<>(tables.size(), 1);
tables.forEach((key, value) -> this.tables.put(key.toLowerCase(), value));
}
和 schema 的概念契合,一个 schema 含有若干个表。ShardingSphereSchema 的属性是一个 map 结构,key 为 tableName,value 是表名对应表的元数据。主要是通过构造函数完成初始化。所以,还是重点对于表元数据的加载,下面我们从入口跟进。
整个元数据加载的核心入口在 org.apache.shardingsphere.infra.context.metadata.MetaDataContextsBuilder#build 中。在 build 中主要是通过配置的规则,组装和加载相对应的元数据,核心代码如下:
/**
* Build meta data contexts.
*
* @exception SQLException SQL exception
* @return meta data contexts
*/
public StandardMetaDataContexts build() throws SQLException {
Map<String, ShardingSphereMetaData> metaDataMap = new HashMap<>(schemaRuleConfigs.size(), 1);
Map<String, ShardingSphereMetaData> actualMetaDataMap = new HashMap<>(schemaRuleConfigs.size(), 1);
for (String each : schemaRuleConfigs.keySet()) {
Map<String, DataSource> dataSourceMap = dataSources.get(each);
Collection<RuleConfiguration> ruleConfigs = schemaRuleConfigs.get(each);
DatabaseType databaseType = DatabaseTypeRecognizer.getDatabaseType(dataSourceMap.values());
// 获取配置的规则
Collection<ShardingSphereRule> rules = ShardingSphereRulesBuilder.buildSchemaRules(each, ruleConfigs, databaseType, dataSourceMap);
// 加载actualTableMetaData和logicTableMetaData
Map<TableMetaData, TableMetaData> tableMetaDatas = SchemaBuilder.build(new SchemaBuilderMaterials(databaseType, dataSourceMap, rules, props));
// 组装规则元数据
ShardingSphereRuleMetaData ruleMetaData = new ShardingSphereRuleMetaData(ruleConfigs, rules);
// 组装数据源元数据
ShardingSphereResource resource = buildResource(databaseType, dataSourceMap);
// 组装数据库元数据
ShardingSphereSchema actualSchema = new ShardingSphereSchema(tableMetaDatas.keySet().stream().filter(Objects::nonNull).collect(Collectors.toMap(TableMetaData::getName, v -> v)));
actualMetaDataMap.put(each, new ShardingSphereMetaData(each, resource, ruleMetaData, actualSchema));
metaDataMap.put(each, new ShardingSphereMetaData(each, resource, ruleMetaData, buildSchema(tableMetaDatas)));
}
//
OptimizeContextFactory optimizeContextFactory = new OptimizeContextFactory(actualMetaDataMap);
returnnew StandardMetaDataContexts(metaDataMap, buildGlobalSchemaMetaData(metaDataMap), executorEngine, props, optimizeContextFactory);
}
通过上述代码可以看出在 build 方法中,主要基于配置的 schemarule 加载了数据库的基本数据如数据库类型、数据库连接池等,通过这些数据完成对于 ShardingSphereResource 的组装;完成 ShardingSphereRuleMetaData 如配置规则、加密规则、认证规则等数据组装;完成 ShardingSphereSchema 中的必要数据库元数据的加载。跟踪找到表元数据的加载方法即org.apache.shardingsphere.infra.metadata.schema.builder.SchemaBuilder#build,在这个方法中,分别加载了 actualTableMetaData 以及 logicTableMetaData,那么什么是 actualTable,什么是 logicTable 呢?简单的来说对于 t_order_1、t_order_2 算是t_order 的节点,所以在概念上来分析,t_order是 logicTable,而t_order_1和t_order_2 是 actualTable。明确了这两个概念后,我们再来一起看 build 方法,主要分为以下两步:
1. actualTableMetaData 加载
actualTableMetaData 是系统分片的基础表,在 5.0.0-beta 版本中,我们采用了数据库方言的方式利用 SQL 进行元数据的查询加载,所以基本流程就是首先通过通过 SQL 进行数据库元数据的查询加载,如果没找到数据库方言加载器,则采用 JDBC 驱动连接进行获取,再结合 ShardingSphereRule 中配置的表名,进行配置表的元数据的加载。核心代码如下所示:
private staticMap<String, TableMetaData> buildActualTableMetaDataMap(final SchemaBuilderMaterials materials) throws SQLException {
Map<String, TableMetaData> result = new HashMap<>(materials.getRules().size(), 1);
// 数据库方言SQL加载元数据
appendRemainTables(materials, result);
for (ShardingSphereRule rule : materials.getRules()) {
if (rule instanceof TableContainedRule) {
for (String table : ((TableContainedRule) rule).getTables()) {
if (!result.containsKey(table)) {
TableMetaDataBuilder.load(table, materials).map(optional -> result.put(table, optional));
}
}
}
}
return result;
}
2. logicTableMetaData 加载
由上述的概念可以看出 logicTable 是 actualTable 基于不同的规则组装而来的实际的逻辑节点,可能是分片节点也可能是加密节点或者是其他,所以 logicTableMetaData 是以 actualTableMetaData 为基础,结合具体的配置规则如分库分表规则等关联的节点。在具体流程上,首先获取配置规则的表名,然后判断是否已经加载过 actualTableMetaData,通过 TableMetaDataBuilder#decorate 方法结合配置规则,生成相关逻辑节点的元数据。核心代码流程如下所示:
private staticMap<String, TableMetaData> buildLogicTableMetaDataMap(final SchemaBuilderMaterials materials, finalMap<String, TableMetaData> tables) throws SQLException {
Map<String, TableMetaData> result = new HashMap<>(materials.getRules().size(), 1);
for (ShardingSphereRule rule : materials.getRules()) {
if (rule instanceof TableContainedRule) {
for (String table : ((TableContainedRule) rule).getTables()) {
if (tables.containsKey(table)) {
TableMetaData metaData = TableMetaDataBuilder.decorate(table, tables.get(table), materials.getRules());
result.put(table, metaData);
}
}
}
}
return result;
}
至此,核心元数据加载完成,封装成一个 Map 进行返回,供各个需求场景进行使用。
元数据加载优化分析
虽然说元数据是我们系统的核心,是必不可少的,但是在系统启动时进行数据加载,必然会导致系统的负载增加,系统启动效率低。所以我们需要对加载的过程进行优化,目前主要是以下两方面的探索:
一、使用 SQL 查询替换原生 JDBC 驱动连接
在 5.0.0-beta 版本之前,采用的方式是通过原生 JDBC 驱动原生方式加载。在 5.0.0-beta 版本中,我们逐步采用了使用数据库方言,通过 SQL 查询的方式,多线程方式实现了元数据的加载。进一步提高了系统数据加载的速度。详细的方言 Loader 可以查看 org.apache.shardingsphere.infra.metadata.schema.builder.spi.DialectTableMetaDataLoader 的相关实现。
二、减少元数据的加载次数
对于系统通用的资源的加载,我们遵循一次加载,多处使用。当然在这个过程中,我们也要权衡空间和时间,所以我们在不断的进行优化,减少元数据的重复加载,提高系统整体的效率。
更多详细功能,欢迎下载使用 Apache ShardingSphere 5.0.0-beta。
感谢支持 OpenSEC