
@zjcnb 刚已经解决了,DistSql使用的方式不太对,hit是用sql注释的方式弄得,稍后我把demo贴一下,供大家参考。
数据源信息:
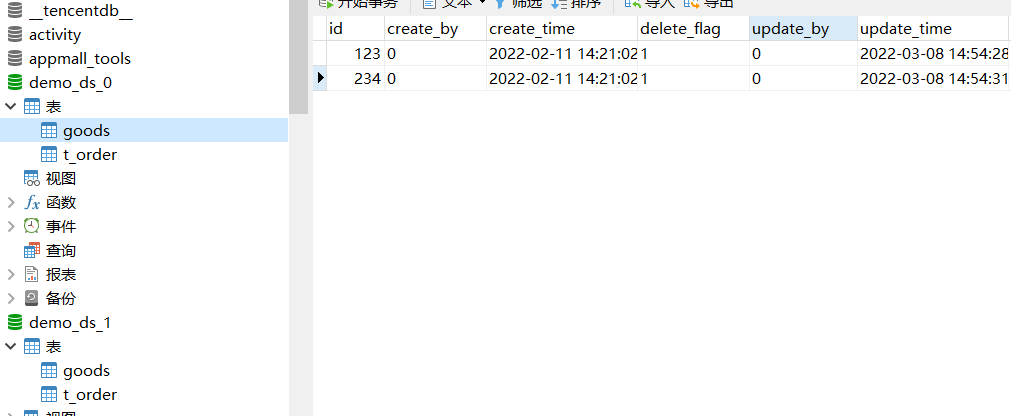
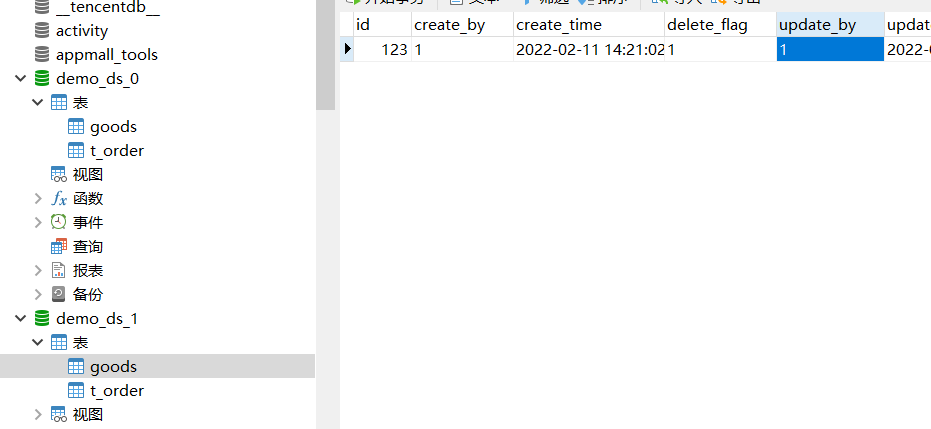
两个schema都有goods表,demo_ds_0 的goods里面有id=123,和id=234数据。demo_ds_1的goods里面有id=123的数据。
然后poxy的 goods里面就有id in(123,234,123)的数据。
以上是数据情况。
我的目标是:如果租户0过来goods就会返回demo_ds_0的123,234,如果是租户1过来查询goods就会返回demo_ds_1的123的数据。
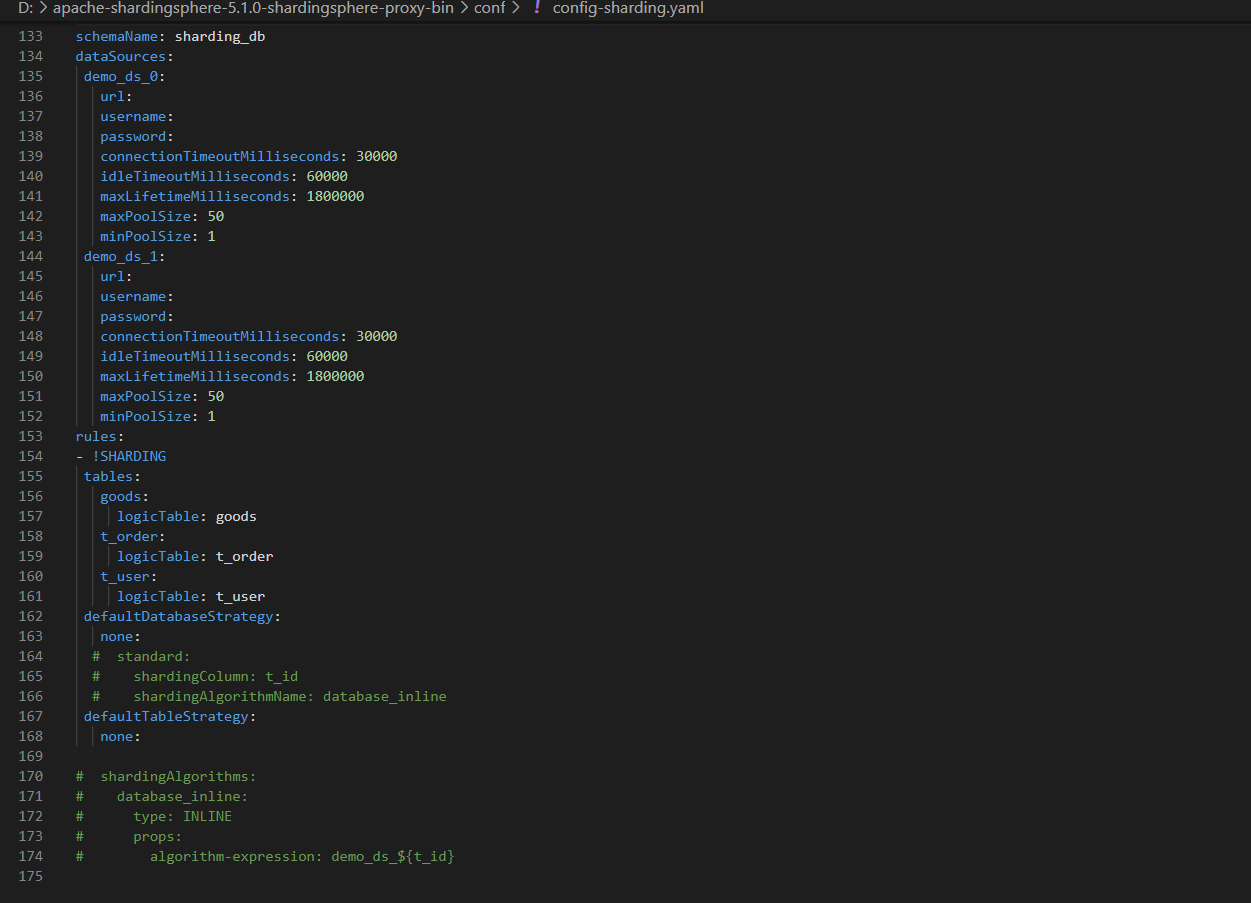
proxy的config-sharding.ymal配置如下(感觉配置写的还是有问题,因为我不用数据字段判断了,所以下列的配置,是不是可以调整一下呢,其实tid也没用):
schemaName: sharding_db
dataSources:
demo_ds_0:
url:
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
demo_ds_1:
url:
username:
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHARDING
tables:
goods:
logicTable: goods
t_order:
logicTable: t_order
defaultDatabaseStrategy:
standard:
shardingColumn: t_id
shardingAlgorithmName: database_inline
defaultTableStrategy:
none:
shardingAlgorithms:
database_inline:
type: INLINE
props:
algorithm-expression: demo_ds_${t_id}
代码使用的mybitsplus 操作数据库的,我在sql执行前,修改了sql,加入hit 代码如下:
public void beforeQuery(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
String url = ThreadContextHolder.getHttpRequest().getQueryString();//这里模拟获取租户标识
String oldSql = boundSql.getSql();
log.info(“oldSql:” + oldSql);
String newSql = “/* ShardingSphere hint: dataSourceName=”+url+" */ " + oldSql;
log.info(“newSql:” + newSql);
PluginUtils.MPBoundSql mpBoundSql = PluginUtils.mpBoundSql(boundSql);
mpBoundSql.sql(newSql);
}
@zjcnb demo如上。
好的, 感谢您的分享.
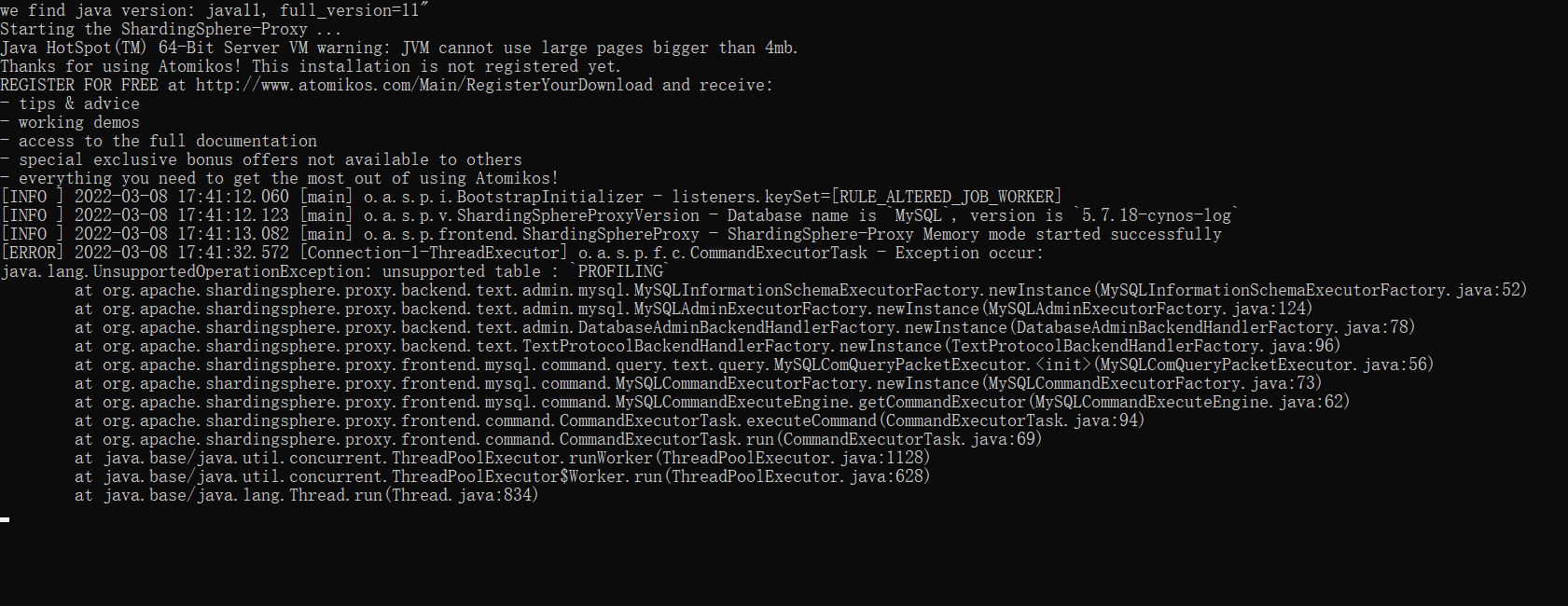
可以看下您的 server.yaml 吗? 可能把配置 copy 上来吗?
@zjcnb server.yaml配置如下:
rules:
-
!AUTHORITY
users:
-
root@%:root
-
sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
-
-
!TRANSACTION
defaultType: XA
providerType: Atomikos
-
!SQL_PARSER
sqlCommentParseEnabled: true
sqlStatementCache:
initialCapacity: 2000
maximumSize: 65535
concurrencyLevel: 4
parseTreeCache:
initialCapacity: 128
maximumSize: 1024
concurrencyLevel: 4
props:
max-connections-size-per-query: 1
kernel-executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
proxy-opentracing-enabled: false
proxy-hint-enabled: true
sql-show: false
check-table-metadata-enabled: false
show-process-list-enabled: false
proxy-backend-query-fetch-size: -1
check-duplicate-table-enabled: false
proxy-frontend-executor-size: 0 # Proxy frontend executor size. The default value is 0, which means let Netty decide.
proxy-backend-executor-suitable: OLAP
proxy-frontend-max-connections: 0 # Less than or equal to 0 means no limitation.
sql-federation-enabled: false
proxy-backend-driver-type: JDBC
zookeeper怎么配置的,没看到相关说明呢